from sklearn.datasets import fetch_20newsgroups
のデータセットを使ってみます。
カテゴリを出力するコード
from pprint import pprint
pprint(list(newsgroups_train.target_names))
これが記事のカテゴリらしいけど始め何が書かれてるのか不明だった。
['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']
調べているとネットニュースプロトコルということが判明。
読んでいるニュースグループ
fj.comp.applications.excel, fj.comp.oldies, fj.comp.misc, fj.os.ms-windows.win95, fj.os.msdos, fj.net.providers, fj.net.words, fj.life.hometown.hokkaido, fj.jokes.d, fj.rec.autos, fj.rec.motorcycles, fj.news.group.*, fj.news.policy, fj.news.misc, fj.news.adm, fj.news.net-abuse, fj.questions.fj, fj.questions.internet, fj.questions, misc, fj.sci.chem, fj.engr.misc
http://www2s.biglobe.ne.jp/~kyashiki/fj/arukikata/WonderfulFj.html
Network News Transfer Protocolってプロトコルを使ったfj (ニュースグループ)ってニュースだった。
sample.py
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import CountVectorizer
import nltk
from pprint import pprint
def stopwords():
symbols = ["'", '"', '`', '.', ',', '-', '!', '?', ':', ';', '(', ')', '*', '--', '\\']
stopwords = nltk.corpus.stopwords.words('english')
return stopwords + symbols
newsgroups_train = fetch_20newsgroups(subset='train', remove=('headers', 'footers', 'quotes'))
newsgroups_test = fetch_20newsgroups(subset='test', remove=('headers', 'footers', 'quotes'))
# ニュースカテゴリを表示
pprint(list(newsgroups_train.target_names))
# 記事データ
# print(newsgroups_train.data)
# CountVectorizerクラスを作る
vectorizer = CountVectorizer(stop_words=stopwords())
# print(vectorizer)
# 語彙辞書を作る
vectorizer.fit(newsgroups_train.data)
# Train
# ドキュメント用語マトリクスをXに代入
X = vectorizer.transform(newsgroups_train.data)
# print(newsgroups_train.target)
y = newsgroups_train.target
# print(X.shape)
clf = MultinomialNB()
clf.fit(X, y)
print(clf.score(X,y))
# Test
X_test = vectorizer.transform(newsgroups_test.data)
y_test = newsgroups_test.target
print(clf.score(X_test, y_test))
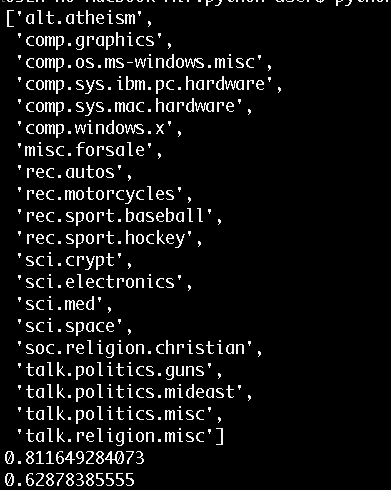
データ:正解率60%
テストデータ:正解率80%
ってことらしいです。
参考にしました。非常に助かりました。
http://qiita.com/kotaroito/items/76a505a88390c5593eba