torchとか使うと推定処理に加えindex.htmlで出力されたりして、いたせりつくせりなのです。
画像分類のサンプル(imagenetフォルダ)で推定処理まとめときました。
https://github.com/pfnet/chainer/tree/v1.24.0/examples/imagenet
ソース
https://github.com/miyamotok0105/imagenet_nogizaka
環境
ubuntu14
cuda8.0
ここでは試してないけどmacのcpuモードの場合gpuを-1指定すればいいはず。
pip install chainer==1.21.0
学習用のデータセットを用意する
例)
train_image/cat/1.jpg
train_image/cat/2.jpg
train_image/dog/1.jpg
train_image/cat/2.jpg
学習用にデータセットパス一覧のテキストファイルを作成
※train_imageフォルダ以下にjpg以外のファイルがあると良くないので削除しておくこと。
python make_train_data.py train_image
import sys
import commands
import subprocess
def cmd(cmd):
return commands.getoutput(cmd)
# p = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# p.wait()
# stdout, stderr = p.communicate()
# return stdout.rstrip()
# labels
dirs = cmd("ls "+sys.argv[1])
labels = dirs.splitlines()
# make directries
cmd("mkdir images")
# copy images and make train.txt
pwd = cmd('pwd')
imageDir = pwd+"/images"
train = open('train.txt','w')
test = open('test.txt','w')
labelsTxt = open('labels.txt','w')
classNo=0
cnt = 0
# label = labels[classNo]
for label in labels:
workdir = pwd+"/"+sys.argv[1]+"/"+label
imageFiles = cmd("ls "+workdir+"/*.jpg")
images = imageFiles.splitlines()
print(label)
labelsTxt.write(label+"\n")
startCnt=cnt
length = len(images)
for image in images:
imagepath = imageDir+"/image%07d" %cnt +".jpg"
cmd("cp "+image+" "+imagepath)
if cnt-startCnt < length*0.75:
train.write(imagepath+" %d\n" % classNo)
else:
test.write(imagepath+" %d\n" % classNo)
cnt += 1
classNo += 1
train.close()
test.close()
labelsTxt.close()
例2)
Caltech 101で学習する
wget http://www.vision.caltech.edu/Image_Datasets/Caltech101/101_ObjectCategories.tar.gz
tar xzvf 101_ObjectCategories.tar.gz
python make_train_data.py 101_ObjectCategories
平均画像を出力
python compute_mean.py train.txt
学習をする
python train_imagenet.py ./train.txt ./test.txt -m ./mean.npy -g 0 -E 400 -a alex
# !/usr/bin/env python
"""Example code of learning a large scale convnet from ILSVRC2012 dataset.
Prerequisite: To run this example, crop the center of ILSVRC2012 training and
validation images, scale them to 256x256 and convert them to RGB, and make
two lists of space-separated CSV whose first column is full path to image and
second column is zero-origin label (this format is same as that used by Caffe's
ImageDataLayer).
"""
from __future__ import print_function
import argparse
import random
from PIL import Image
import numpy as np
import chainer
from chainer import training
from chainer.training import extensions
import alex
import googlenet
import googlenetbn
import nin
class PreprocessedDataset(chainer.dataset.DatasetMixin):
def __init__(self, path, root, mean, crop_size, random=True):
self.base = chainer.datasets.LabeledImageDataset(path, root)
self.mean = mean.astype('f')
self.crop_size = crop_size
self.random = random
def __len__(self):
return len(self.base)
def get_example(self, i):
# It reads the i-th image/label pair and return a preprocessed image.
# It applies following preprocesses:
# - Cropping (random or center rectangular)
# - Random flip
# - Scaling to [0, 1] value
crop_size = self.crop_size
image, label = self.base[i]
_, h, w = image.shape
if self.random:
# Randomly crop a region and flip the image
top = random.randint(0, h - crop_size - 1)
left = random.randint(0, w - crop_size - 1)
if random.randint(0, 1):
image = image[:, :, ::-1]
else:
# Crop the center
top = (h - crop_size) // 2
left = (w - crop_size) // 2
bottom = top + crop_size
right = left + crop_size
image = image[:, top:bottom, left:right]
image -= self.mean[:, top:bottom, left:right]
image *= (1.0 / 255.0) # Scale to [0, 1]
return image, label
class TestModeEvaluator(extensions.Evaluator):
def evaluate(self):
model = self.get_target('main')
model.train = False
ret = super(TestModeEvaluator, self).evaluate()
model.train = True
return ret
def main():
archs = {
'alex': alex.Alex,
'alex_fp16': alex.AlexFp16,
'googlenet': googlenet.GoogLeNet,
'googlenetbn': googlenetbn.GoogLeNetBN,
'googlenetbn_fp16': googlenetbn.GoogLeNetBNFp16,
'nin': nin.NIN
}
parser = argparse.ArgumentParser(
description='Learning convnet from ILSVRC2012 dataset')
parser.add_argument('train', help='Path to training image-label list file')
parser.add_argument('val', help='Path to validation image-label list file')
parser.add_argument('--arch', '-a', choices=archs.keys(), default='nin',
help='Convnet architecture')
parser.add_argument('--batchsize', '-B', type=int, default=32,
help='Learning minibatch size')
parser.add_argument('--epoch', '-E', type=int, default=10,
help='Number of epochs to train')
parser.add_argument('--gpu', '-g', type=int, default=-1,
help='GPU ID (negative value indicates CPU')
parser.add_argument('--initmodel',
help='Initialize the model from given file')
parser.add_argument('--loaderjob', '-j', type=int,
help='Number of parallel data loading processes')
parser.add_argument('--mean', '-m', default='mean.npy',
help='Mean file (computed by compute_mean.py)')
parser.add_argument('--resume', '-r', default='',
help='Initialize the trainer from given file')
parser.add_argument('--out', '-o', default='result',
help='Output directory')
parser.add_argument('--root', '-R', default='.',
help='Root directory path of image files')
parser.add_argument('--val_batchsize', '-b', type=int, default=250,
help='Validation minibatch size')
parser.add_argument('--test', action='store_true')
parser.add_argument('--optimizer', '-op', type=int, default=1,
help='optimizer')
parser.set_defaults(test=False)
args = parser.parse_args()
# Initialize the model to train
model = archs[args.arch]()
if args.initmodel:
print('Load model from', args.initmodel)
chainer.serializers.load_npz(args.initmodel, model)
#chainer.serializers.load_hdf5(args.initmodel, model)
if args.gpu >= 0:
chainer.cuda.get_device(args.gpu).use() # Make the GPU current
model.to_gpu()
# Load the datasets and mean file
mean = np.load(args.mean)
train = PreprocessedDataset(args.train, args.root, mean, model.insize)
val = PreprocessedDataset(args.val, args.root, mean, model.insize, False)
#for t in train:
# print(t[0].shape)
# These iterators load the images with subprocesses running in parallel to
# the training/validation.
train_iter = chainer.iterators.MultiprocessIterator(
train, args.batchsize, n_processes=args.loaderjob)
val_iter = chainer.iterators.MultiprocessIterator(
val, args.val_batchsize, repeat=False, n_processes=args.loaderjob)
# Set up an optimizer
if args.optimizer == 1:
optimizer = chainer.optimizers.MomentumSGD(lr=0.01, momentum=0.9)
elif args.optimizer == 2:
optimizer = chainer.optimizers.AdaDelta(rho=0.95, eps=1e-06)
elif args.optimizer == 3:
optimizer = chainer.optimizers.AdaGrad(lr=0.001, eps=1e-08)
elif args.optimizer == 4:
optimizer = chainer.optimizers.Adam(alpha=0.001, beta1=0.9, beta2=0.999, eps=1e-08)
optimizer.setup(model)
# Set up a trainer
updater = training.StandardUpdater(train_iter, optimizer, device=args.gpu)
trainer = training.Trainer(updater, (args.epoch, 'epoch'), args.out)
val_interval = (10 if args.test else 4000), 'iteration'
log_interval = (10 if args.test else 4000), 'iteration'
trainer.extend(TestModeEvaluator(val_iter, model, device=args.gpu),
trigger=val_interval)
trainer.extend(extensions.dump_graph('main/loss'))
trainer.extend(extensions.snapshot(), trigger=val_interval)
trainer.extend(extensions.snapshot_object(
model, 'model_iter_{.updater.iteration}'), trigger=val_interval)
# Be careful to pass the interval directly to LogReport
# (it determines when to emit log rather than when to read observations)
trainer.extend(extensions.LogReport(trigger=log_interval))
trainer.extend(extensions.observe_lr(), trigger=log_interval)
# Save two plot images to the result dir
#if extensions.PlotReport.available():
trainer.extend(
extensions.PlotReport(['main/loss', 'validation/main/loss'],
'epoch', file_name='loss.png'))
trainer.extend(
extensions.PlotReport(
['main/accuracy', 'validation/main/accuracy'],
'epoch', file_name='accuracy.png'))
trainer.extend(extensions.PrintReport([
'epoch', 'iteration', 'main/loss', 'validation/main/loss',
'main/accuracy', 'validation/main/accuracy', 'lr'
]), trigger=log_interval)
trainer.extend(extensions.ProgressBar(update_interval=10))
if args.resume:
chainer.serializers.load_npz(args.resume, trainer)
trainer.run()
#chainer.serializers.save_hdf5('alex_400e_png_model.h5', model)
if __name__ == '__main__':
main()
推定する
alexnetを使った推定
論文
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
スライド
http://vision.stanford.edu/teaching/cs231b_spring1415/slides/alexnet_tugce_kyunghee.pdf
python test_imagenet.py --test image_list.txt -g 0 -E 1 -m mean.npy --initmodel alex_400e_png_model.h5 -a alex
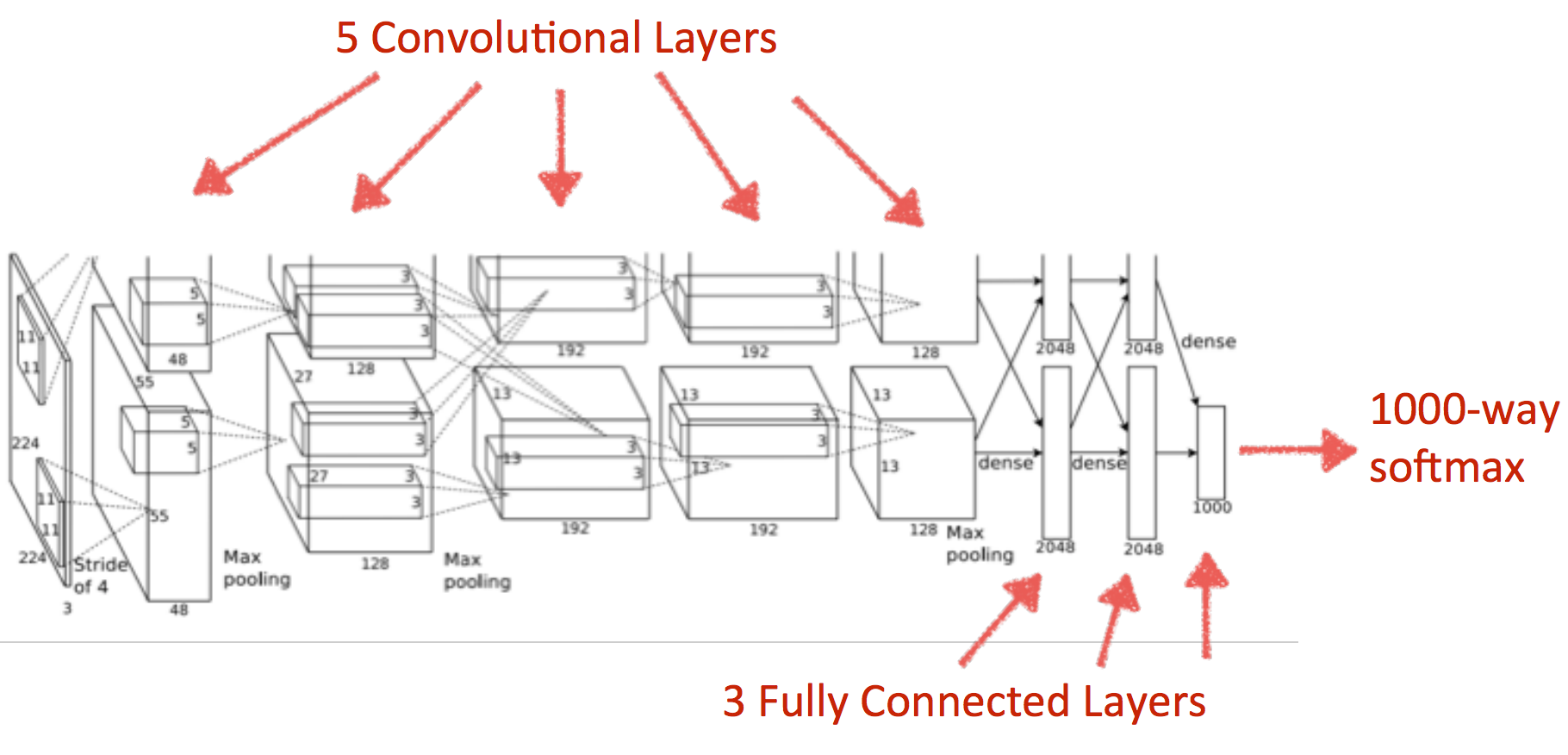
predictor関数を追加。
import numpy as np
import chainer
import chainer.functions as F
from chainer import initializers
import chainer.links as L
class Alex(chainer.Chain):
"""Single-GPU AlexNet without partition toward the channel axis."""
insize = 227
def __init__(self):
super(Alex, self).__init__(
conv1=L.Convolution2D(None, 96, 11, stride=4),
conv2=L.Convolution2D(None, 256, 5, pad=2),
conv3=L.Convolution2D(None, 384, 3, pad=1),
conv4=L.Convolution2D(None, 384, 3, pad=1),
conv5=L.Convolution2D(None, 256, 3, pad=1),
fc6=L.Linear(None, 4096),
fc7=L.Linear(None, 4096),
fc8=L.Linear(None, 1000),
)
self.train = True
def __call__(self, x, t):
h = F.max_pooling_2d(F.local_response_normalization(
F.relu(self.conv1(x))), 3, stride=2)
h = F.max_pooling_2d(F.local_response_normalization(
F.relu(self.conv2(h))), 3, stride=2)
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = F.max_pooling_2d(F.relu(self.conv5(h)), 3, stride=2)
h = F.dropout(F.relu(self.fc6(h)), train=self.train)
h = F.dropout(F.relu(self.fc7(h)), train=self.train)
h = self.fc8(h)
loss = F.softmax_cross_entropy(h, t)
chainer.report({'loss': loss, 'accuracy': F.accuracy(h, t)}, self)
return loss
def predictor(self, x):
h = F.max_pooling_2d(F.local_response_normalization(
F.relu(self.conv1(x))), 3, stride=2)
h = F.max_pooling_2d(F.local_response_normalization(
F.relu(self.conv2(h))), 3, stride=2)
h = F.relu(self.conv3(h))
h = F.relu(self.conv4(h))
h = F.max_pooling_2d(F.relu(self.conv5(h)), 3, stride=2)
h = F.dropout(F.relu(self.fc6(h)), train=self.train)
h = F.dropout(F.relu(self.fc7(h)), train=self.train)
h = self.fc8(h)
return h
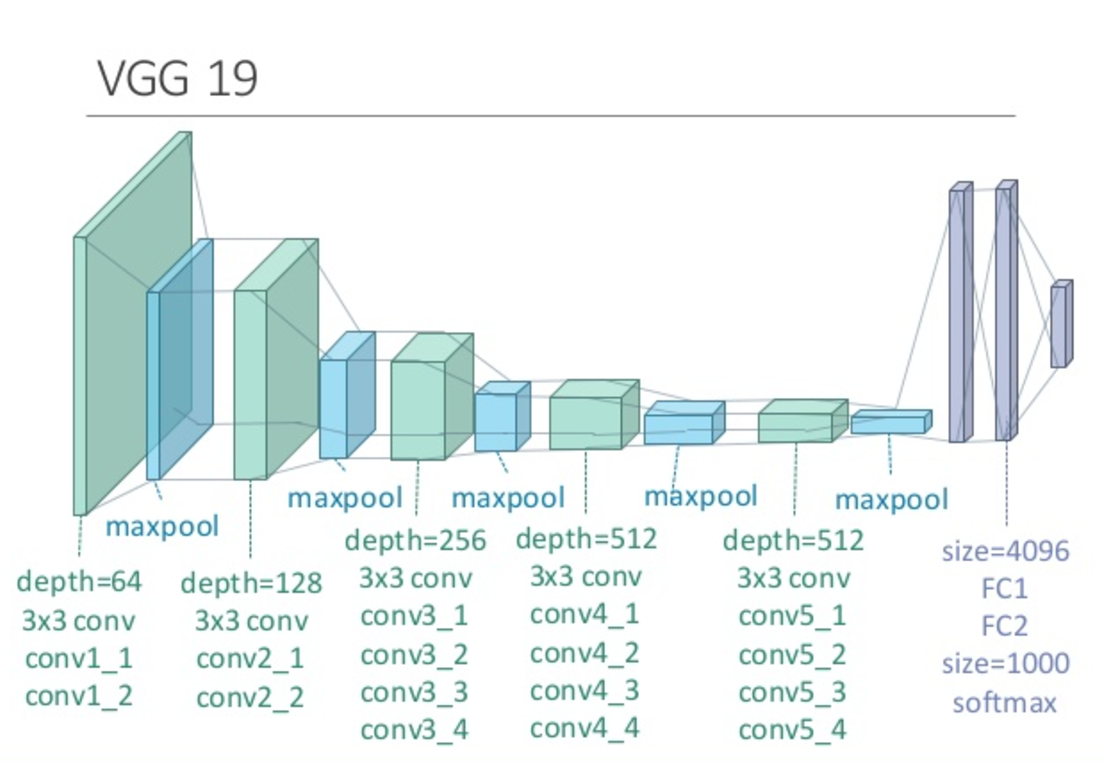
VGGを使った推定
imagenetフォルダには無いが勉強のために書いとく。
論文
https://arxiv.org/abs/1409.1556
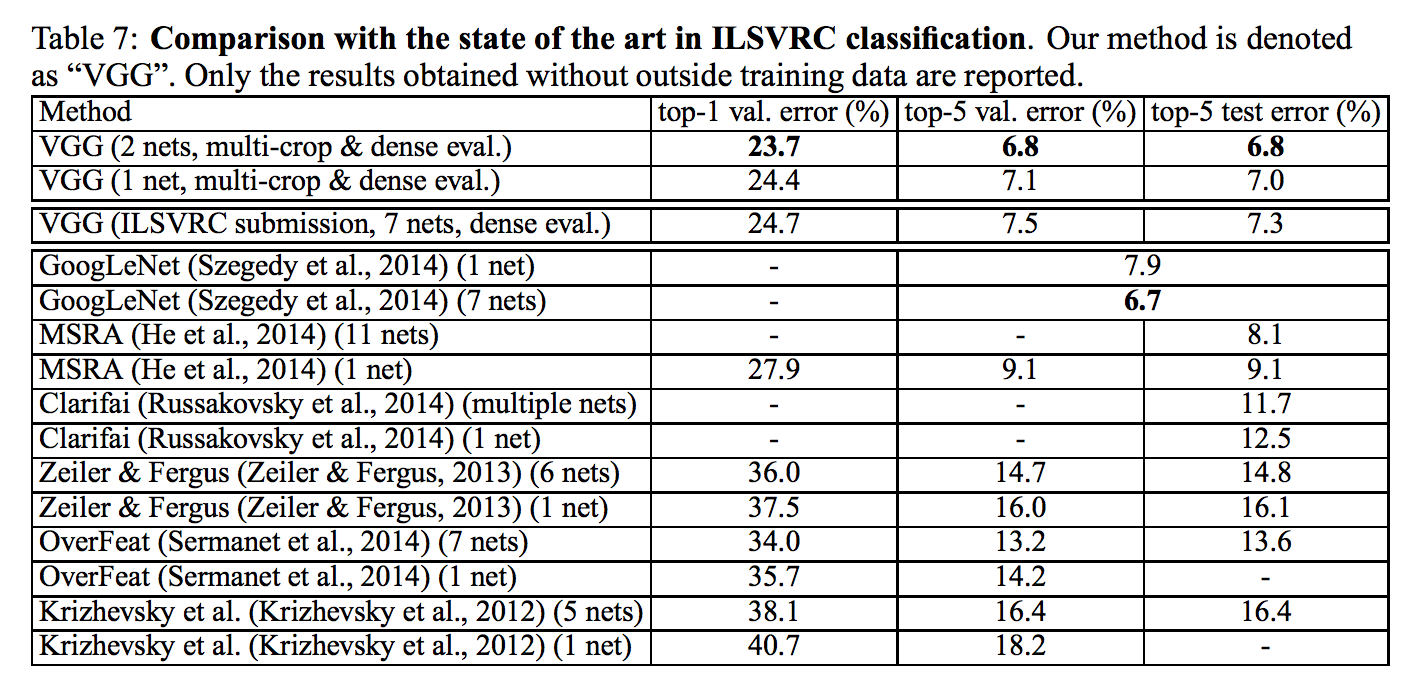
昔のgooglenetよりエラー率が低い。
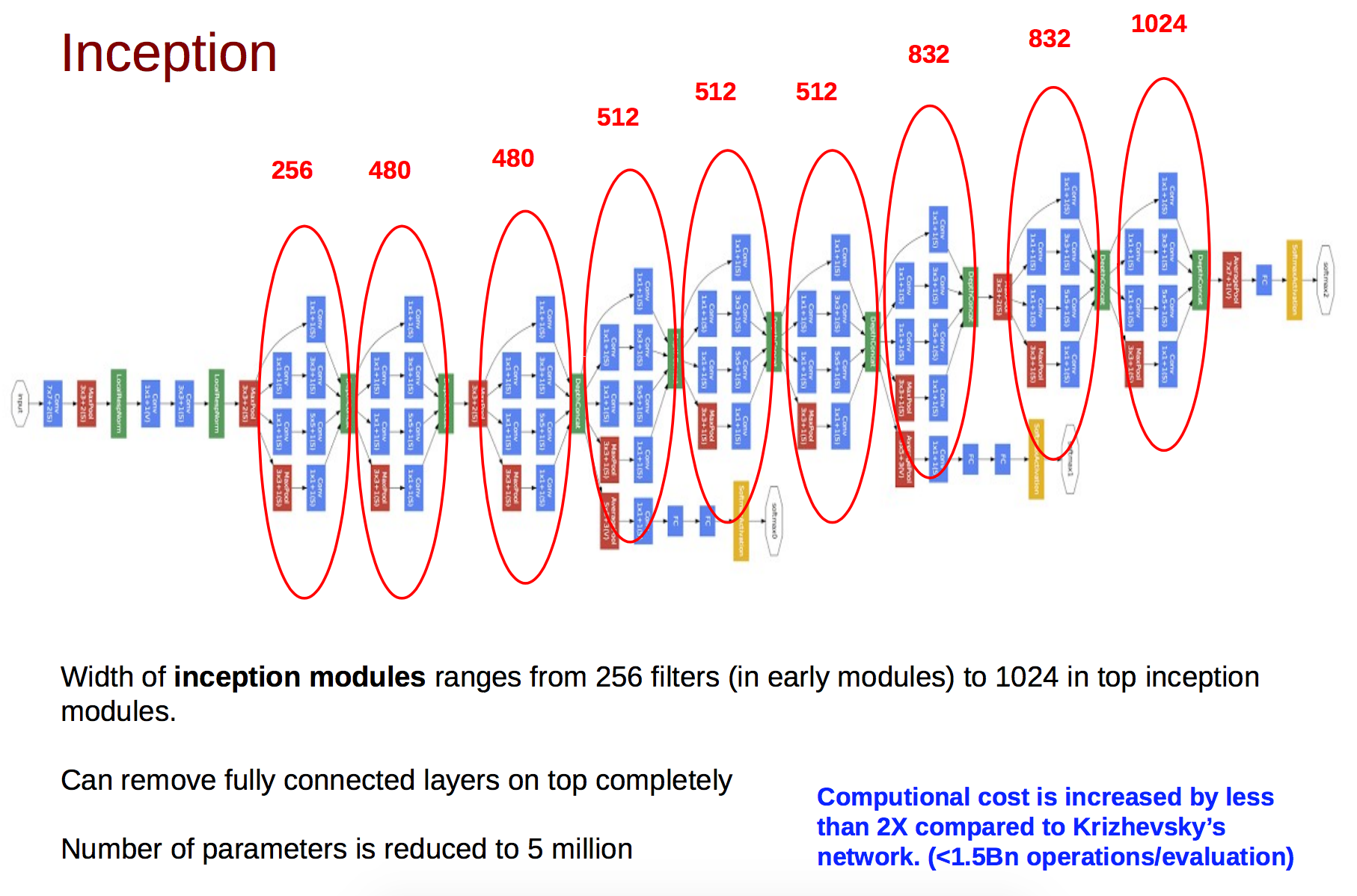
GoogLeNetを使った推定
python test_imagenet.py --test test.txt -g 2 -E 1 -m mean.npy --initmodel result/model_iter_18000 -a googlenet
predictorを追加。
def predictor(self, x):
h = F.relu(self.conv1(x))
h = F.local_response_normalization(
F.max_pooling_2d(h, 3, stride=2), n=5)
h = F.relu(self.conv2_reduce(h))
h = F.relu(self.conv2(h))
h = F.max_pooling_2d(
F.local_response_normalization(h, n=5), 3, stride=2)
h = self.inc3a(h)
h = self.inc3b(h)
h = F.max_pooling_2d(h, 3, stride=2)
h = self.inc4a(h)
h = self.inc4b(h)
h = self.inc4c(h)
h = self.inc4d(h)
h = self.inc4e(h)
h = F.max_pooling_2d(h, 3, stride=2)
h = self.inc5a(h)
h = self.inc5b(h)
h = F.average_pooling_2d(h, 7, stride=1)
h = self.loss3_fc(F.dropout(h, 0.4, train=self.train))
return h
GoogLeNetのInception Module層では、1×1フィルタが64枚、3×3フィルタが32枚、5×5フィルタが16枚、poolingフィルタが16枚のように、複数種のフィルタを用意し、そのフィルタリング結果を結合して、nチャンネル(128チャンネル)の出力を生成する。(サイズの異なるフィルタでも、出力画像のサイズが同じになるように、strideとpaddingでサイズ調整される)
参考
https://github.com/leetenki/googlenet_chainer
NINを使った推定
論文
https://arxiv.org/pdf/1312.4400.pdf
参考
http://140.113.203.57/topics/Deep_Learning.html
# !/usr/bin/env python
"""Example code of learning a large scale convnet from ILSVRC2012 dataset.
1;95;0c
Prerequisite: To run this example, crop the center of ILSVRC2012 training and
validation images, scale them to 256x256 and convert them to RGB, and make
two lists of space-separated CSV whose first column is full path to image and
second column is zero-origin label (this format is same as that used by Caffe's
ImageDataLayer).
"""
from __future__ import print_function
import argparse
import random
from PIL import Image
import numpy as np
import chainer
from chainer import training
from chainer.training import extensions
from chainer import cuda
import chainer.links as L
import chainer.functions as F
import os
import re
import shutil
import alex
import googlenet
import googlenetbn
import nin
class PreprocessedDataset(chainer.dataset.DatasetMixin):
def __init__(self, path, root, mean, crop_size, random=True):
self.base = chainer.datasets.LabeledImageDataset(path, root)
self.mean = mean.astype('f')
self.crop_size = crop_size
self.random = random
def __len__(self):
return len(self.base)
def get_example(self, i):
# It reads the i-th image/label pair and return a preprocessed image.
# It applies following preprocesses:
# - Cropping (random or center rectangular)
# - Random flip
# - Scaling to [0, 1] value
crop_size = self.crop_size
image, label = self.base[i]
_, h, w = image.shape
if self.random:
# Randomly crop a region and flip the image
top = random.randint(0, h - crop_size - 1)
left = random.randint(0, w - crop_size - 1)
if random.randint(0, 1):
image = image[:, :, ::-1]
else:
# Crop the center
top = (h - crop_size) // 2
left = (w - crop_size) // 2
bottom = top + crop_size
right = left + crop_size
image = image[:, top:bottom, left:right]
image -= self.mean[:, top:bottom, left:right]
image *= (1.0 / 255.0) # Scale to [0, 1]
return image, label
class TestModeEvaluator(extensions.Evaluator):
def evaluate(self):
model = self.get_target('main')
model.train = False
ret = super(TestModeEvaluator, self).evaluate()
model.train = True
return ret
def main():
archs = {
'alex': alex.Alex,
'alex_fp16': alex.AlexFp16,
'googlenet': googlenet.GoogLeNet,
'googlenetbn': googlenetbn.GoogLeNetBN,
'googlenetbn_fp16': googlenetbn.GoogLeNetBNFp16,
'nin': nin.NIN
}
parser = argparse.ArgumentParser(
description='Learning convnet from ILSVRC2012 dataset')
parser.add_argument('--test', help='Path to training image-label list file')
parser.add_argument('--arch', '-a', choices=archs.keys(), default='nin',
help='Convnet architecture')
parser.add_argument('--batchsize', '-B', type=int, default=32,
help='Learning minibatch size')
parser.add_argument('--epoch', '-E', type=int, default=10,
help='Number of epochs to train')
parser.add_argument('--gpu', '-g', type=int, default=-1,
help='GPU ID (negative value indicates CPU')
parser.add_argument('--initmodel',
help='Initialize the model from given file')
parser.add_argument('--loaderjob', '-j', type=int,
help='Number of parallel data loading processes')
parser.add_argument('--mean', '-m', default='mean.npy',
help='Mean file (computed by compute_mean.py)')
parser.add_argument('--resume', '-r', default='',
help='Initialize the trainer from given file')
parser.add_argument('--out', '-o', default='result',
help='Output directory')
parser.add_argument('--root', '-R', default='.',
help='Root directory path of image files')
parser.add_argument('--val_batchsize', '-b', type=int, default=250,
help='Validation minibatch size')
parser.set_defaults(test=False)
args = parser.parse_args()
# Initialize the model to train
model = archs[args.arch]()
if args.initmodel:
print('Load model from', args.initmodel)
#chainer.serializers.load_npz(args.initmodel, model)
chainer.serializers.load_hdf5(args.initmodel, model)
if args.gpu >= 0:
chainer.cuda.get_device(args.gpu).use() # Make the GPU current
model.to_gpu()
xp = cuda.cupy if args.gpu >= 0 else np
mean = np.load(args.mean)
test = PreprocessedDataset(args.test, args.root, mean, model.insize, False)
print("test----")
# for line in open('test.txt', 'r'):
# print(line)
for t, line in zip(test, open(args.test, 'r')):
#print(t[0].shape)
#x = np.asarray(1, t[0])[:].astype(np.float32)
x = np.ndarray((1, 3, model.insize, model.insize), dtype=np.float32)
x[0] = t[0]
x = xp.asarray(x)
x = chainer.Variable(x, volatile=True)
y = model.predictor(x)
score = F.softmax(y)
print(line)
print(np.argmax(y.data[0].tolist()))
print("---")
if __name__ == '__main__':
main()
ファインチューニングの追加はこっち
トラブルシューティング
pngで学習したので次元があってなかったので合わせて
x = np.ndarray((1, 4, model.insize, model.insize), dtype=np.float32)
→x = np.ndarray((1, 3, model.insize, model.insize), dtype=np.float32)
参考
良いスライド
https://www.slideshare.net/ckmarkohchang/applied-deep-learning-1103-convolutional-neural-networks