脳科学的な知見を得たくても知らない単語が多すぎて困るので、資料に出て来る用語だけでもまとめた。
2014年の理化学研究所の資料。脳の計算理論:強化学習と価値に基づく意思決定に基づく。
http://www.itn.brain.riken.jp/05_publication/J_technicalreports/14_BSI_ITN_TechReport_No%2014-01
関連する脳部位
価値意思決定に関わる脳領野は多岐にわたる。
その多くが中脳ドーパミン神経細胞の投射を受けている。
それらの領野は、知覚から運動、あるいは、報酬予測から行動選択まで、さまざまな段階に関与する。
領野の機能的分化は、知覚から運動の軸、そして以下で議論する、異なる内部モデルの利用という軸、この2つの軸に沿っていると思われる。

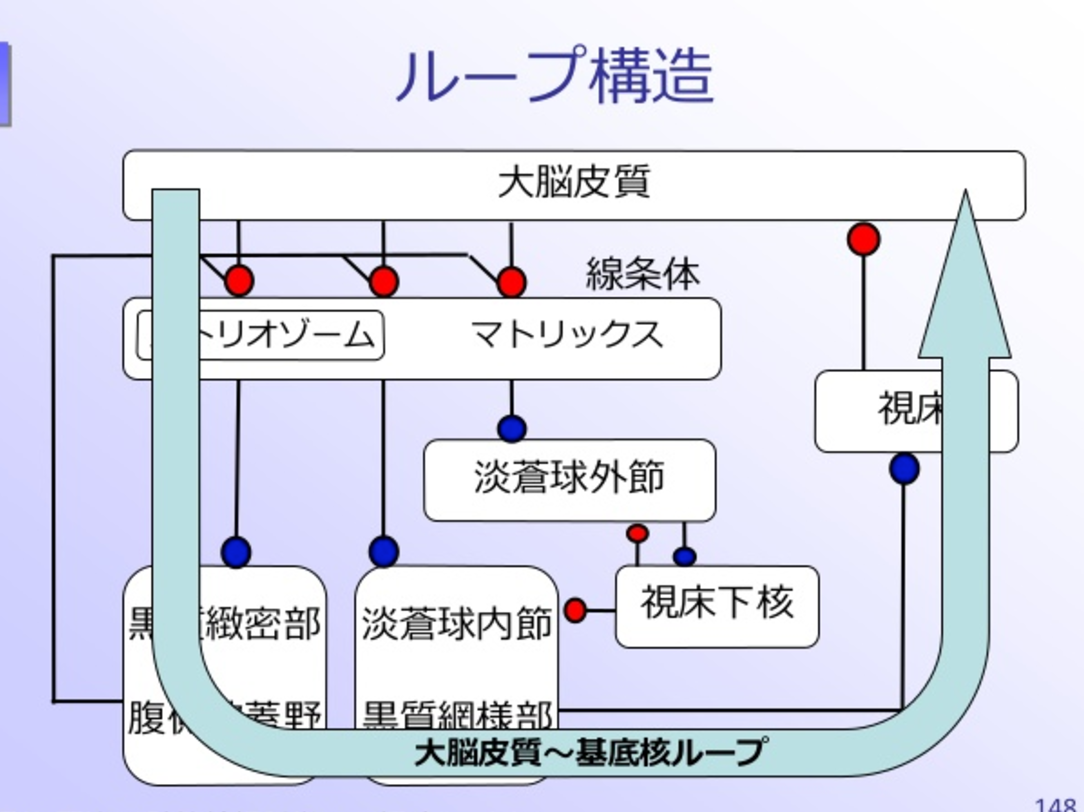
意思決定に関わる主たる皮質下領域には大脳基底核(すなわち線条体、側座核、黒質網様部、淡蒼球)、 中脳ドーパミン領域(黒質緻密部、腹側被蓋野)および扁桃体が含まれる 7)。
小脳(しょうのう、英: cerebellum、ラテン語で「小さな脳」を意味する)
脳の神経細胞の大部分は、小脳にあり、その数は1000億個以上である。小脳の主要な機能は知覚と運動機能の統合であり、平衡・筋緊張・随意筋運動の調節などを司る。このため、小脳が損傷を受けると、運動や平衡感覚に異常をきたし、精密な運動ができなくなったり酒に酔っているようなふらふらとした歩行となることがある。
下記の層構造がずっと続いている。もう一つの興味深い点は、顆粒細胞同士、ゴルジ細胞同時、あるいはプルキンエ細胞同士の接続はなく、情報はかならず別の層へと伝わっていく点です。
参考:http://kazoo04.hatenablog.com/entry/2015/12/23/120000#f-0e122bf6

小脳パーセプトロン仮説
Liquid State Machine
一種のスパイキングニューラルネットワーク。LSMはパーセプトロンと結構似ているのですが、一部にランダムに接続された部分があるという変わったアルゴリズム。

層を浅くするとネットワークの表現能力が落ちるため、これを補うために中間層(隠れ層)のノード数(ニューロン数)を大幅に増やす必要があります。これが小脳に大量の顆粒細胞がある理由だと思われます。大脳新皮質ほど高度な処理はできないけれど、処理ユニットを超並列化して、任意の関数の近似を非常に高速に行う、というのが小脳の役割というわけです。
大脳基底核(だいのうきていかく:basal ganglia)
大脳皮質と視床、脳幹を結びつけている神経核の集まりである。大脳は基本的に外周部が灰白質(ニューロンの細胞体がある場所)である場所が多いものの、大脳の深い所にあるのにもかかわらず大脳基底核は灰白質である。哺乳類の大脳基底核は運動調節、認知機能、感情、動機づけや学習など様々な機能を担っている。

大脳皮質(だいのうひしつ、: Cerebral cortex)
大脳の表面に広がる、神経細胞の灰白質の薄い層。その厚さは場所によって違うが、1.5~4.0mmほど。大脳基底核と呼ばれる灰白質の周りを覆っている。知覚、随意運動、思考、推理、記憶など、脳の高次機能を司る。神経細胞は規則正しい層構造をなして整然と並んでいる。
皮質領域
6層は外側から順に
分子層
外顆粒層
外錐体細胞層
内顆粒層
内錐体細胞層(神経細胞層)
多形細胞層

その他にも、報酬の欠如と嫌悪刺激に関連する手網外側核、報酬価値に関連する視床下部、運動出力に関連する上丘(じょうきゅう)と脚橋被蓋核、およびセロトニンニューロンを含む背側縫線核がある。
視床下部(ししょうかぶ:hypothalamus)
間脳(視床の前下方で、第三脳室下側壁)に位置し、自律機能の調節を行う総合中枢である。中脳以下の自律機能を司る中枢がそれぞれ呼吸運動や血管運動などの個々の自律機能を調節するのに対して、視床下部は交感神経・副交感神経機能及び内分泌機能を全体として総合的に調節している。

上丘(じょうきゅう:superior colliculus, SC)
上丘のうち視覚情報を受け取るのは浅層のみであり、深層は聴覚・体性感覚の入力を受け取り、脳の多くの感覚運動領野との神経接続を持つ。上丘は全体としては頭部や眼球を、視対象・聴対象のほうへ向ける役割がある

脚橋被蓋核(きゃくきょうひがいかく pedunculopontine tegmental nucleus または pudunculopontine nucleus、PPTN、PPTg、PPN、などと略記)
脳幹に位置する神経核。黒質の尾側、上小脳脚の近くに位置する。解剖学的には脳幹網様体の一部を、生理機能的には睡眠や覚醒に関わる上行性網様賦活系(ascending reticular activating system)の一部を成す。一方で、大脳基底核との相互連絡が強く、学習や報酬などにも関与すると考えられている。

背側縫線核 raphe nuclei(縫線核 ほうせんかく)
脊椎動物の脳幹にある神経核の一つである。大きく吻側核群、背側縫線核、 尾側核群に細分類される。睡眠覚醒・歩行・呼吸などのパターン的な運動や注意・報酬などの情動や認知機能にも関与する。その投射は脳全体にわたっている。生化学的にはセロトニンを含む細胞が存在するのが大きな特徴である。

DRN: 背側縫線核 (dorsal raphe nucleus); MRN: 内側縫線核 (median raphe nucleus); NRM: 大縫線核 (nucleus raphe magnus); NRP: 淡蒼縫線核 (nucleus raphe pallidus); NRO: 不確縫線核(nucleus raphe obscures)
AC: 前交連 (anterior commissure); CC: 脳梁 (corpus callosum); Am: 扁桃体 (amygdala); CB: 帯状束 (cingulum bundle); DG: 歯状回 (dentate gyrus); DRCT: 背側縫線核皮質路 (dorsal raphe cortical tract); F: 脳弓 (fornix); H: 視床下部 (hypothalamus); Hipp: 海馬 (hippocampus); IC: 内包 (internal capsule); IP: 脚間核 (interpeduncular nucleus); LC: 青斑核 (locus coeruleus); MB: 乳頭体 (mammillary body); MFB: 内側前脳束 (medial forebrain bundle); OB: 嗅球 (olfactory bulb); S: 中隔 (septum); SM: 髄条 (stria medullaris); Str: 線条体 (striatum); SN: 黒質 (substantia nigra); VAFP; 腹側扁桃体遠心路 (ventroamygdalofugal pathway)
海馬は種々の内部モデルの構築を支援する 8)。主たる皮質領域は前頭前皮質および頭頂皮質、特に背外側前頭前皮質、内側前頭皮質(前帯状皮質を含む)、眼窩前頭皮質である 9-11)。 特に腹側内側部前頭前皮質は最終的に選択される価値をコードすると思われる。また、この領域は他の社会的神経回路、たとえば(後部)上側頭溝や側頭頭頂接合部とともに社会的意思決定にも関与する。
海馬
海馬は大脳側頭葉の内側部で側脳室下角底部に位置し、エピソード記憶等の顕在性記憶の形成に不可欠な皮質部位である(図1)。記憶形成に関与する側頭葉皮質部位には、嗅内野、傍海馬台、前海馬台、海馬台、海馬(アンモン角)、歯状回がある。また、海馬台、海馬、歯状回に、脳梁上部に位置し、中隔方向に連続する構造物である脳梁灰白層を加えて集合的に海馬体 (hippocampal formation) と呼ぶ。

前頭前皮質(ぜんとうぜんひしつ、英: prefrontal cortex、PFC)
脳にある前頭葉の前側の領域で、一次運動野と前運動野の前に存在する。前頭連合野、前頭前野、前頭顆粒皮質とも呼ばれる。
この脳領域は複雑な認知行動の計画、人格の発現、適切な社会的行動の調節に関わっているとされている。この脳領域の基本的な活動は、自身の内的ゴールに従って、考えや行動を編成することにあると考えられる。

側頭葉
側頭葉(そくとうよう、英: Temporal lobe)は、大脳葉のひとつで、言語、記憶、聴覚に関わっている。

シナプス
ニューロン(neurone)とニューロン、またはニューロンと効果器細胞との接合部位。

シナプス可塑性
記憶・学習など、ヒトの脳の機能を実現するために、神経回路が物理的・生理的に、その性質を変化させる事のできる能力の事で、アポトーシスによるニューロンの減少と発芽によるシナプス接合部の増加という物理的な変化と、長期増強(long-term potentiation)によって信号の通りが良くなる、という生理的な変化がその主なものです。
記憶・学習の形成過程では、シナプスでの情報の伝わりやすさ(シナプス伝達効率)が変化します。短・中期に持続する記憶・学習はシナプスに存在する分子の機能的な変化によっておきると考えられています。一方、より長期に持続する記憶・学習はシナプスの数や形態が変化する構造的な変化がおきるものとされています。
Cbln1とGluD2という2つのシナプス可塑性を制御について
http://kompas.hosp.keio.ac.jp/contents/medical_info/science/201404.html
ドーパミン(dopamine)
中枢神経系に存在する神経伝達物質で、アドレナリン、ノルアドレナリンの前駆体でもある。運動調節、ホルモン調節、快の感情、意欲、学習などに関わる。

ドーパミンとセロトニン
ドーパミン
快楽を司り報酬系と言われる神経伝達物質
向上心やモチベーション、記憶や学習能力、運動機能に関与
ノルアドレナリンの前駆体
セロトニン
精神を安定させる役割を担っています。ノルアドレナリンやドーパミンの分泌をコントロールして暴走を抑えます。咀嚼や呼吸、歩行といった反復する運動機能にも関与しています。
ノンアドレラニン
物事への意欲の源、生存本能を司ります。ストレスに反応して怒りや不安・恐怖などの感情を起こすため、「怒りのホルモン」や「ストレスホルモン」などの異名を持ちます。また、交感神経を刺激して心身を覚醒させる働きがあります。
https://www.human-sb.com/serotonin_dopamin_noradrenalin.html

スパイクニューラルネットワーク
参考:http://www2.kobe-u.ac.jp/~hampton/Lecture/Model/Lecture20111214-2.pdf

スパイクニューラルネットワークにおける音楽パターン認識
https://github.com/mrahtz/musical-pattern-recognition-in-spiking-neural-networks
brian
http://www.briansimulator.org/docs/
brian2
http://briansimulator.org/
Auryn spiking neural network simulator
http://www.fzenke.net/auryn/doku.php?id=start
⼤脳⽪質ベイジアンネットモデルの実⽤化に向けて


脳の様々な⾼次機能(認識、意思決定、運動制御、思考、推論、⾔語理解など)が、たった50個程度の領野のネットワークで実現されている。

詳細
http://wba-initiative.org/wp-content/uploads/2015/05/20160518-wbas1-ichisugi.pdf
https://staff.aist.go.jp/y-ichisugi/besom/research-theme.html
Target Propagation
参考:http://i101330.hatenablog.com/entry/2016/07/11/232317
参考:http://deeplearning.jp/wp-content/uploads/2014/04/20150826_suzuki.pdf
Back Propagationが生物学妥当性がないという根拠を6つの要点を持って提示し、
それに代わる手法としてTarget Propagationを提案している。

参考:https://www.slideshare.net/kazoo04/ss-69947926

feedback alignment
参考:https://www.slideshare.net/kazoo04/ss-69947926
他にも資料には書かれていたが、今回は省く。

HTM
参考:http://wba-initiative.org/1653/



大脳皮質を中心とする神経回路の研究フォーラム
参考:http://www.mbs.med.kyoto-u.ac.jp/cortex/
強化学習:理論的背景とモデルフリー強化学習
意思決定(報酬予測と行動選択)に環境の内的モデルを一切必要としない。
状態 s のときに行動 a をとったときの価値 Q(s,a) を学習し、それに基づいて意思決定を行う。
参考:http://brainvalley.jp/%E5%BC%B7%E5%8C%96%E5%AD%A6%E7%BF%92


モデルフリー強化学習について、まずは逐次的意思決定が関与しない場合から理解しよう(図 1A)。
「エージェント(意思決定者)」は所与の環境において「状態」を観測し、選択肢の中から報酬を得るための「行動」を選択する。価値とは、この行動選択をするための予測報酬であり、報酬予測誤差(報酬予測誤差=実報酬-予測報酬)は将来の予測(および行動選択)を改善するための学習信号として機能する。報酬予測の学習は誤差の減少を目指す(新たな報酬予測=今までの報酬予測+学習係数×報酬予測誤差)。
 図 1. モデルフリー強化学習(A)と報酬予測誤差仮説(B)A. 入力からの直接連想により想起された報酬予測(価値)に基づいて確率的に行動を選択する。その結果として得られる報酬をもとに計算された報酬予測誤差(実際に得られた報酬量と予測していた量の差)を利用して、報酬予測を学習(更新)する。なお、四角の枠は個体の内部プロセスを表す。B. ドーパミン神経細胞活動は報酬予測誤差を表す(黒色点線矢印)。誤差は実際に得た報酬(ドーパミン神経細胞に入っていく赤色矢印)と予測された報酬との差である。ここで用いられている報酬予測は、基本的にはその各時点での外界事象(ドーパミン神経細胞に入っていく黒色矢印)で表現される予測に限られる。ドーパミン神経細胞活動で表される報酬予測誤差は学習信号として、報酬予測と行動選択の学習に寄与する(黒色点線矢印)。この学習信号を利用して、太い黒色実線矢印の強度が変化することで報酬予測と行動選択の学習が行われる。
図 1. モデルフリー強化学習(A)と報酬予測誤差仮説(B)A. 入力からの直接連想により想起された報酬予測(価値)に基づいて確率的に行動を選択する。その結果として得られる報酬をもとに計算された報酬予測誤差(実際に得られた報酬量と予測していた量の差)を利用して、報酬予測を学習(更新)する。なお、四角の枠は個体の内部プロセスを表す。B. ドーパミン神経細胞活動は報酬予測誤差を表す(黒色点線矢印)。誤差は実際に得た報酬(ドーパミン神経細胞に入っていく赤色矢印)と予測された報酬との差である。ここで用いられている報酬予測は、基本的にはその各時点での外界事象(ドーパミン神経細胞に入っていく黒色矢印)で表現される予測に限られる。ドーパミン神経細胞活動で表される報酬予測誤差は学習信号として、報酬予測と行動選択の学習に寄与する(黒色点線矢印)。この学習信号を利用して、太い黒色実線矢印の強度が変化することで報酬予測と行動選択の学習が行われる。
これが「モデルフリーの強化学習」と呼ばれるのは、その意思決定(報酬予測と行動選択)に環境の内的モデルを一切必要としないことに由来する(図 3、緑色矢印)。報酬予測と行動選択は状態からの直接連想として学習され、またこの 2 つのみが意思決定に用いられるのである。
 図 3. 価値に基づく意思決定のプロセス。エージェント、すなわち意思決定者が感覚入力(外界事象)を受けてそれが脳内表現になる。モデルフリーの強化学習はこの脳内表現からの直接連想によって価値を計算する(緑色矢印)。ドーパミン報酬予測誤差仮説では、さらに、この「感覚入力」が「脳内表現」に等しいと仮定したモデルフリー強化学習のモデルを用いる。一方で、経験を通じて、エージェントは報酬構造や他人の心などの内部モデルを構築する。この内部モデルを用いる意思決定では、プランニングや、索餌行動をはじめとするモデルベース強化学習などが可能となる(青色矢印)。内部モデルは外界を脳内シミュレーションする(再帰的な青色矢印)ことでこれらを実現する。赤色矢印は本文で述べた、脳内表現は内部モデルからの情報と感覚入力の統合であり、それによりモデルフリー強化学習がより強力になりうるという点を強調している。
図 3. 価値に基づく意思決定のプロセス。エージェント、すなわち意思決定者が感覚入力(外界事象)を受けてそれが脳内表現になる。モデルフリーの強化学習はこの脳内表現からの直接連想によって価値を計算する(緑色矢印)。ドーパミン報酬予測誤差仮説では、さらに、この「感覚入力」が「脳内表現」に等しいと仮定したモデルフリー強化学習のモデルを用いる。一方で、経験を通じて、エージェントは報酬構造や他人の心などの内部モデルを構築する。この内部モデルを用いる意思決定では、プランニングや、索餌行動をはじめとするモデルベース強化学習などが可能となる(青色矢印)。内部モデルは外界を脳内シミュレーションする(再帰的な青色矢印)ことでこれらを実現する。赤色矢印は本文で述べた、脳内表現は内部モデルからの情報と感覚入力の統合であり、それによりモデルフリー強化学習がより強力になりうるという点を強調している。
さて、この図式をより完成されたものにするには、「時間」の観点を含めることが必要で、そこで強化学習理論の中で最もよく用いられる時間差学習(temporal difference learning; 以下 TD 学習)が出てくる。たとえば短い時間スケールでは、いわゆる実時間の視点、すなわち上の例で言えば、状態の観測から報酬獲得までの時間経過が考えられる。TD 学習は、この実時間を適切に扱うのである(これが次節で述べる報酬予測誤差仮説の提唱につながったのである)。より長いスケールでは、それが逐次的意思決定につながる。ある状態で行動選択をしてすぐに報酬を得るというよりも、いくつかの状態を経由し(その各状態で各行動を選択し)、その経過の途中や最後に得られる報酬を集める。このとき、最大限の報酬を獲得するためには、エージェントは即時の報酬を追求するだけではなく、即時の報酬と将来の報酬のバランスも確保しなければならない。TD 学習はこれらの問題に対処し、得られる報酬のバランスを状態間、つまり時間経過で考慮した価値を形成する。その学習には TD 誤差が用いられる。
プランニング
http://www.jsk.t.u-tokyo.ac.jp/~inamura/lecture/agent-system/
ドーパミン神経細胞活動の報酬予測誤差仮説
価値意思決定の研究が著しく発展したきっかけは、ドーパミン報酬予測誤差仮説の提唱であった 4)。この仮説は、ドーパミン神経細胞活動の実験結果に対して、モデルフリー強化学習(より正確には、TD 学習)理論と 2 つの仮定を土台に提唱された。この仮説の骨子は、ドーパミン神経細胞活動が「TD 学習の報酬予測誤差(TD 誤差)を表し、それを学習信号として、報酬予測が学習される」というものである (図 1B、図 2)。この仮説に用いられた 2 つの仮定を整理すると、第一の仮定は、最適の意思決定を下すためには現在の「状態」が入力としてあれば十分で、過去の情報は不要というものである。この仮定は、現実世界では破られる可能性はあるが、理論的な解析を容易にする(後述)。第二の仮定は直近の感覚入力のみが「状態」を形成するという仮定である。これは、単純化するための仮定である。実際、報酬予測と行動選択の両方に用いられた「状態」を実験条件で明示的に与えることはできるが、脳の強化学習に用いられる脳活動としての入力(つまり「状態」)として特定するのは困難なことが多い。

 図 2. 刺激―報酬課題(古典的条件付課題)における、A;ドーパミン神経細胞活動(DA 活動)と、B;それに対応する時間差学習(TD 学習)および誤差(TD 誤差):B の下の 2 行の図は、ドーパミン神経細胞活動と TD 誤差が一致することを、報酬がもらえる場合ともらえない場合の両方について示している。
図 2. 刺激―報酬課題(古典的条件付課題)における、A;ドーパミン神経細胞活動(DA 活動)と、B;それに対応する時間差学習(TD 学習)および誤差(TD 誤差):B の下の 2 行の図は、ドーパミン神経細胞活動と TD 誤差が一致することを、報酬がもらえる場合ともらえない場合の両方について示している。
参考:http://brainvalley.jp/%E5%BC%B7%E5%8C%96%E5%AD%A6%E7%BF%92



参考:http://aidiary.hatenablog.com/entry/20021202/1119960582
-
TD誤差δ
報酬の予測値と実際に得られた報酬との差 -
割引率γ
どのくらい未来の報酬まで考慮するか -
逆温度β
行動選択において搾取(目先の利益を追求して行動選択)するか探査(ランダムに行動選択)するか
εグリーディ法 -
学習率α
報酬予測を一度にどの程度変更するか -
TD誤差δ ⇔ ドーパミン系
上に書いたサルの実験。 -
割引率γ ⇔ セロトニン系
セロトニン系が低下すると、うつ病や衝撃的な行動といった目先の苦難や誘惑にとらわれ、長期的な展望をもとに行動できなくなる。これは、γが0に近いと目先の利益を考慮して行動を選択し、γが1に近いほど長期的な報酬を考慮する強化学習のアルゴリズムと一致する。 -
逆温度β ⇔ ノルアドレナリン系
青斑核のノルアドレナリン系の活動は緊迫したり、痛み刺激などのストレスを伴った状態で高く、リラックスした状態では低い。これは、βが高い緊急事態では現時点で考えられる最良の行動を取り(=搾取)、βが低い状態では行動にランダムさを持たせる(=探査)という強化学習の行動選択法と一致する。εグリーディ法。 -
学習率α ⇔ アセチルコリン系
アセチルコリンは、海馬などの記憶に関するゲートを開いたり閉じたりする働きがあることが示唆されている。また、アセチルコリンの低下はアルツハイマー病の記憶障害の原因であることが示されている。これは、学習を調節したり、学習の重み付けを行うαの働き(αが大きいと急速に学習が進み、αが小さいと学習が遅い)と一致する。
参考:http://brainvalley.jp/%E5%BC%B7%E5%8C%96%E5%AD%A6%E7%BF%92
脳は強化学習している?




モデルベース強化学習
外界の脳内モデルを用いる価値意思決定の代表例。
外界のモデルを学習する強化学習の手法らしい。
意思決定に必要な計算時間は増えるが、学習に必要なエピソードの経験回数は減るらしい。
ドーパミン報酬予測誤差仮説の提唱とともに導入されたモデルフリー強化学習の理論は、その後、多くの価値意思決定に関する脳研究に用いられ、大きな成果を挙げた。しかし、感覚入力からの直接連想だけで、報酬予測と行動選択がいつも決まってしまうわけではない(図 3)。生物は経験を通じて、外界の事柄をいわば脳内シミュレーションするような内部モデルを学習することができる。もちろん、内部モデルを外界の環境すべてについて獲得しているわけではないが(それは極めて困難である)、環境構造のさまざまな側面について種々の内部モデルを獲得していると考えられる。特に大切な内部モデルとしては、報酬にまつわる環境構造や、社会生活における他者の心などが挙げられる。現在、それらの内部モデルを含む価値意思決定の研究が花開きつつある。その一例として、索餌行動(foraging)の研究がある。この行動では、報酬をもらったからそのまま報酬予測を上げて、その場所に留まり引き続き餌を探すのか、もうそこを離れて未知の場所に餌を探しに行くのかを意思決定しなければならない。留まるか離れるか、どちらの行動の価値を考えるにも内部モデルが必要である。他の例としては、モデルベース強化学習の研究も内部モデルがその土台となっている 8,12)。一般にモデルベース強化学習では、「状態から状態への遷移」(状態遷移)および「状態と行動のペアに対して起きる報酬」(報酬関数)のいずれか一方あるいは両方の内部モデルを(たとえ近似的にでも)学習する。そして、それらの学習をもとに、報酬予測と行動選択の意思決定を行う(図 3、青色矢印)。このモデルベース強化学習の特性を生かした研究としては、たとえば、目的指向性の行動と習慣的な行動の間の差を研究するために、モデルベースド強化学習のほうが意思決定に柔軟性があることを利用する研究がある 13)。その他に、学習時の特性について、あるいはモデルフリー強化学習とモデルベース強化学習がどのように協調的に働くかなどについても研究が進められている 8,11,14,15)。

他人の心の内部モデルを利用する意思決定
人っぽくするには利他行為も実装する必要がある。
「相手の気持ちを考えなければ…」――私たちは生涯で何度この言葉を繰り返すことだろうか。私たちは他人の心について内部モデルを持っている。これがよく知られている「心の理論」(theory of mind)である 16)。実は、強化学習の脳計算理論は、価値意思決定を超えて、社会的知性の脳機能の解明にも役立つことが示されつつある。これは、「はじめに」で述べたように、脳計算の具体性を追求することで、社会的知性という複雑な脳機能が、明快な強化学習の脳計算理論を通じて明らかにされるからである。この分野は今後の発展が大いに期待されている。ここで私たちの研究例を挙げて説明したい 17)(図 4)。心の理論の土台として、「人は自分の心のプロセスをもとにして、他人の心のプロセスを自分の心の中で構成する」というシミュレーション説(simulation theory)がある 18)。一方、「シミュレーションは不必要で、人は他人が何にどう反応するかのパターンを学習して、他人の目に見える行動を当てる」という考え方もある(例「セオリー・セオリー」(theory-theory);以下、「行動パターン説」と総称)19)。これらの議論を踏まえて、私たちは、他者の心の動きを予測するという複雑なプロセスを解明するには、その意思決定プロセスと学習について徹底的な検証を行うこと、すなわち脳情報処理、つまり脳計算の観点から検討することが必要だと考え、他者の心の脳内シミュレーションに迫るために、価値意思決定の実験を行った。その際の工夫として、被験者に価値意思決定の課題(コントール課題)を行わせると同時に、他人がコントロール課題をしているときの、その他人の行動選択を予測するという課題(メイン課題)も行わせた。そして、モデル化解析手法と呼ばれる脳計算モデルを利用して、行動データと脳活動を照合し、脳計算過程に対応する脳活動をヒト fMRI 実験で解析した。その結果、実は、ヒトは他者の心をシミュレーションするとき、2 つの学習信号を用いることが分かった。一つは、まさしくシミュレーション説が唱える他者報酬予測誤差信号(simulated-other’s reward prediction error)で、これは前頭葉腹内側部にのみ対応する脳活動が見られた。一方、その学習信号だけではなく、行動パターン説に当てはまるような、他者の行動の予測と実際の行動との差、つまり他者行動予測誤差信号(simulated-other’s action prediction error)を利用した学習も同時に行われることがわかった。他者行動予測誤差は、前頭葉背外側部や背内側部の脳活動に表れていた。他にも、社会性の議論でしばしば挙げられる脳領野、たとえば、側頭頭頂接合部と後部上側頭溝でも対応する脳活動が見られた 20,21)。私たちは、強化学習に基づき脳計算の具体性を追求することで、ヒトは 2 つの説を統合したハイブリッドな学習を通じて、他者の心(価値意思決定)をシミュレーションしていることを発見した。
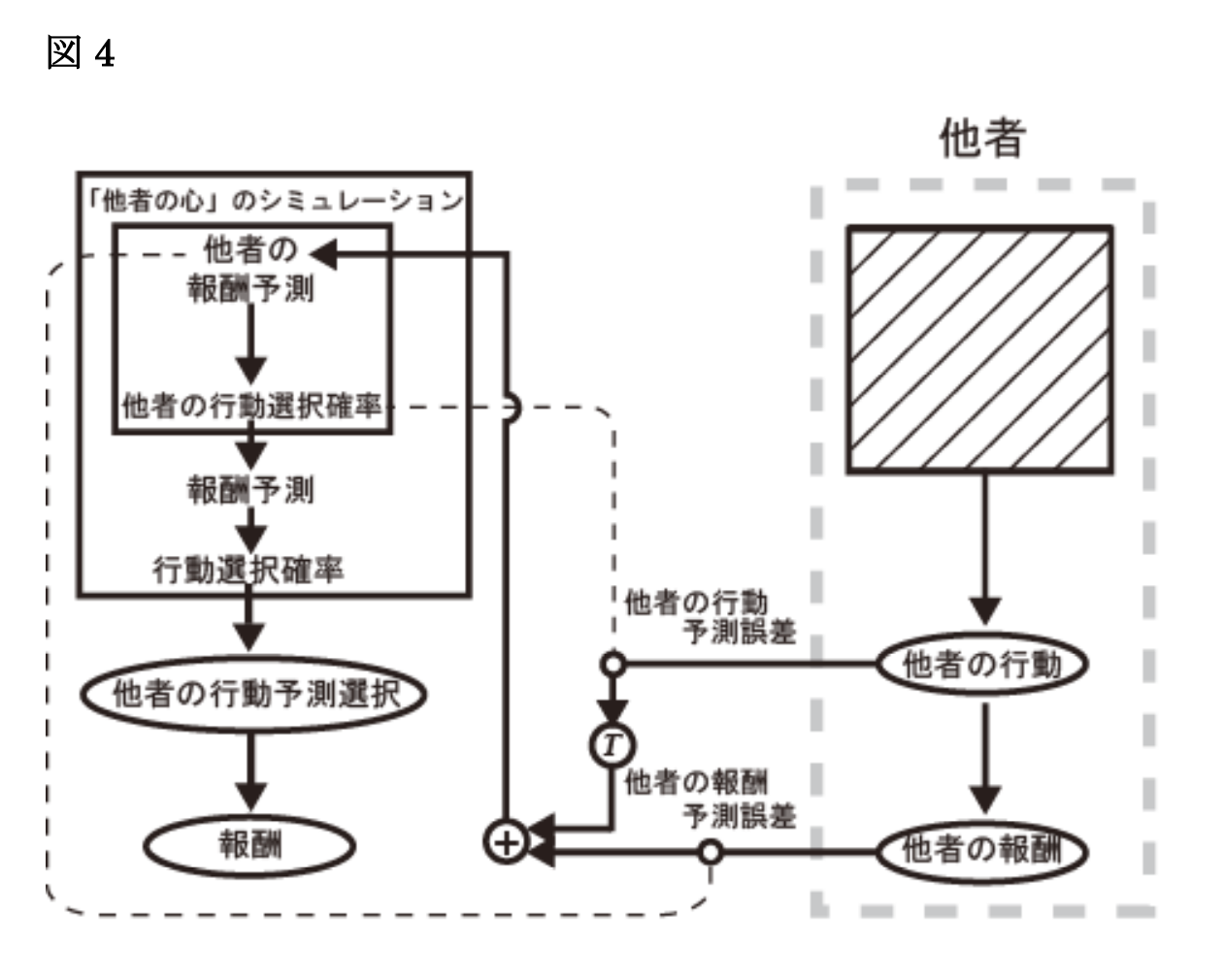 図 4.他者の心の脳計算モデルの概要シミュレーション説と行動パターン説のハイブリッドモデル: 被験者は脳内で「他者の意思決定プロセス(報酬予測、行動選択確率)」を再現し、他者の行動を予測する(左図)。他者の実際の行動とその結果得られた報酬(右図)が明らかになった時点で、他者報酬予測誤差(他者が実際に得た報酬量と、被験者の脳内でシミュレーションしている他者が予測していた量の差)と他者行動予測誤差(他者の実際の行動とその予測の差)から「他者の報酬予測」を学習する。ここで、他者行動予測誤差は行動に関する予測誤差なので、そのままの形では報酬予測の更新には使えない。数学的には変分法と呼ばれる方法に対応した、行動予測誤差を報酬予測の学習に使える形に変換するプロセスが介在している。なお、斜線の四角枠は被験者から観察不可能な「他者の内部プロセス」を表す(図 1A を他者、あるいは本人が報酬予測を行って意思決定するプロセスと考えて参照するとよい)。
図 4.他者の心の脳計算モデルの概要シミュレーション説と行動パターン説のハイブリッドモデル: 被験者は脳内で「他者の意思決定プロセス(報酬予測、行動選択確率)」を再現し、他者の行動を予測する(左図)。他者の実際の行動とその結果得られた報酬(右図)が明らかになった時点で、他者報酬予測誤差(他者が実際に得た報酬量と、被験者の脳内でシミュレーションしている他者が予測していた量の差)と他者行動予測誤差(他者の実際の行動とその予測の差)から「他者の報酬予測」を学習する。ここで、他者行動予測誤差は行動に関する予測誤差なので、そのままの形では報酬予測の更新には使えない。数学的には変分法と呼ばれる方法に対応した、行動予測誤差を報酬予測の学習に使える形に変換するプロセスが介在している。なお、斜線の四角枠は被験者から観察不可能な「他者の内部プロセス」を表す(図 1A を他者、あるいは本人が報酬予測を行って意思決定するプロセスと考えて参照するとよい)。
報酬構造学習仮説
ドーパミン神経細胞に関わる新仮説。どこまでを状態として入力するのか考える必要がある。
ドーパミン神経活動は、感覚入力を状態としてモデルフリーの学習信号(TD 誤差)だけをコードしているのだろうか。実は、私たちは実験と理論を融合した研究を行うことで、ドーパミン神経細胞活動が報酬予測誤差仮説で想定されている報酬予測よりも優れた報酬予測をもとに、報酬予測誤差を表現しうることを発見した 22)。紙面の限りから、喩えを使って説明しよう。たとえば、報酬予測誤差仮説は、「報酬」を「日曜」に置き換えて考えた場合、「明日は日曜ですか」という質問の場合、「はい」という答えがくる確率は(1 週間は 7 日あるため)7 分の 1 であるという予測が行われるとしている。しかし、私たちが得た結果では、「今日が土曜日なら確率は 1 である」という予測が働くことが示された。また、報酬予測誤差仮説ではドーパミン神経細胞活動が誤差信号として比較的一様であることが想定されていたが、誤差仮説に触発されて積み上げられた近年の知見は、より多様な情報(例:不確実性、事前情報、運動開始、アラート信号、サリエンス信号)がその活動を修飾していることを示している 23) 24)。しかも特筆すべきは、これらはすべて原理的に脳内表現の学習を助ける信号になりうる点である。また、知覚学習の分野では、そもそもドーパミン神経細胞が表現学習にも重要な役割を果たすことが支持されている 25)。これらの知見をもとに、私たちは最近「ドーパミン報酬構造学習仮説」を提唱した(図5)26)。これは報酬の構造とその予測の学習は本来不可分であるという考え方を出発点としている。ドーパミン神経細胞活動は誤差仮説で想定される報酬予測誤差信号に留まらず、環境構造も反映する学習信号であり、それは予測の学習だけではなく環境構造を入力表現に反映するのにも適していると考えられる。すなわち、ドーパミン神経細胞活動は誤差仮説で想定する報酬予測のための“重み”の学習だけでなく、予測の入力表現の学習にも利用される、つまり、予測学習と表現学習の双方に影響を与えるとするのがこの仮説である。この議論のカギは、脳の価値意思決定における「状態」とは何かを理解することである。今まで、この疑問はほとんど見過ごされてきた。しかし、モデルフリー強化学習を行う脳回路への入力が「状態」であるはずだから、感覚入力以外の内的に生成された情報も脳内表現の一部であって不思議はない。報酬構造の内部モデルを利用することによって、より優れた脳内表現が作られる(図 3、脳内表現と内部モデルの間の赤色矢印)26)。このモデルフリー強化学習は報酬予測誤差仮説のモデルフリー強化学習に比べて強力である。このモデルフリーの意思決定は、内部モデルの利用という意味で実はモデルベースでもある。それでも、学習と意思決定自体は、「状態」からの直接連想という意味ではモデルフリーである。この直接連想では、より正確な報酬予測と行動選択が生成されうるし、その学習は、ドーパミン活動がそれを反映した報酬予測誤差をコードすることで可能になる 26,27)。
 図 5. 報酬構造学習仮説:ドーパミン神経細胞活動は報酬構造を学習するための信号を表す(黒色点線矢印および灰色点線矢印)。ドーパミンや神経細胞は報酬予測のみならず、学習された報酬構造に関する入力(青色矢印)を受ける。さらに、ここでの報酬予測は各時点での外界事象と学習された報酬構造の両者を反映した脳内入力から生成される。この予測は原理的に報酬予測誤差仮説(図 1B)で用いられた報酬予測より優れている。この予測を利用した報酬予測誤差信号は、より優れた学習信号として報酬構造学習の信号の一部となる(黒色点線矢印)。報酬構造成分をより多く含むドーパミン神経細胞活動は、報酬構造を反映した内的表現の学習にも用いられる(灰色点線矢印)。
図 5. 報酬構造学習仮説:ドーパミン神経細胞活動は報酬構造を学習するための信号を表す(黒色点線矢印および灰色点線矢印)。ドーパミンや神経細胞は報酬予測のみならず、学習された報酬構造に関する入力(青色矢印)を受ける。さらに、ここでの報酬予測は各時点での外界事象と学習された報酬構造の両者を反映した脳内入力から生成される。この予測は原理的に報酬予測誤差仮説(図 1B)で用いられた報酬予測より優れている。この予測を利用した報酬予測誤差信号は、より優れた学習信号として報酬構造学習の信号の一部となる(黒色点線矢印)。報酬構造成分をより多く含むドーパミン神経細胞活動は、報酬構造を反映した内的表現の学習にも用いられる(灰色点線矢印)。
さいごに
価値に基づく意思決定について、強化学習を中心とした脳の計算理論を概観し、その最近のトピックを駆け足で見てきた。理論と実験の融合研究は、たとえばヒト fMRI 実験あるいは動物実験などで今後ますます必要になってくる(NAKAHARA LAB:http://www.itn.brain.riken.jp 参照)。このような融合研究に挑戦する人々が増え、それが価値意思決定や報酬予測の研究だけでなく、多様な分野の研究で大きな発展につながることを期待している。また、本稿ではほとんど触れなかったが、意思決定の研究は社会的知性の研究と今後より関係を深めると思われる。それは、社会的意思決定、他人の心の予測、あるいは精神疾患のよりよい理解につながることだろう。神経科学が広範な科学と連携し、神経経済学や計算論的社会脳科学、計算論的精神医学、ひいては人間総合科学へと発展していくという、大きな学問的潮流が動きつつある。私たちもこの流れに貢献していきたいと考えている。
fMRI (functional magnetic resonance imaging)
MRI(核磁気共鳴も参照)を利用して、ヒトおよび動物の脳や脊髄の活動に関連した血流動態反応を視覚化する方法の一つである。最近のニューロイメージングの中でも最も発達した手法の一つである。

モデルフリーとモデルベースの違いってなんなんでしょう?
強化学習の文脈で「価値」というと、報酬の期待値をとるときに、未来に得られる報酬の予測を含んでいいます。もちろん、現時点で未来はわからないですから、「過去から環境が変わらないとしたら」という前提で予測することになります。
TD誤差を求めるときに使っている価値Vは、t時刻に得られる報酬をr(t)として、未来に得られる報酬の総和V(t) = r(t) + r(t+1) + r(t+2) + …です。
もちろんr(t+1), r(t+2)など未来に得られる報酬を現在は知ることができない。そこで、未来にいくであろう状態sに依存して報酬が得られるのならsの関数として予測することになります。
値関数V(s(t)) = r(s(t)) + r(s(t+1)) + …を報酬r(t)から直接学習するのがモデルフリー強化学習、未来の状態sを状態遷移モデルなどによって独立に予測し、間接的にVを求めるのがモデルベースです。
https://togetter.com/li/313328
強化学習論文情報
Atari 2600

環境
keras-rl
https://github.com/matthiasplappert/keras-rl
chainer-rl
http://chainer.org/general/2017/02/22/ChainerRL-Deep-Reinforcement-Learning-Library.html
DQN


Double DQN
参考スライド
https://www.slideshare.net/ssuser07aa33/introduction-to-double-deep-qlearning

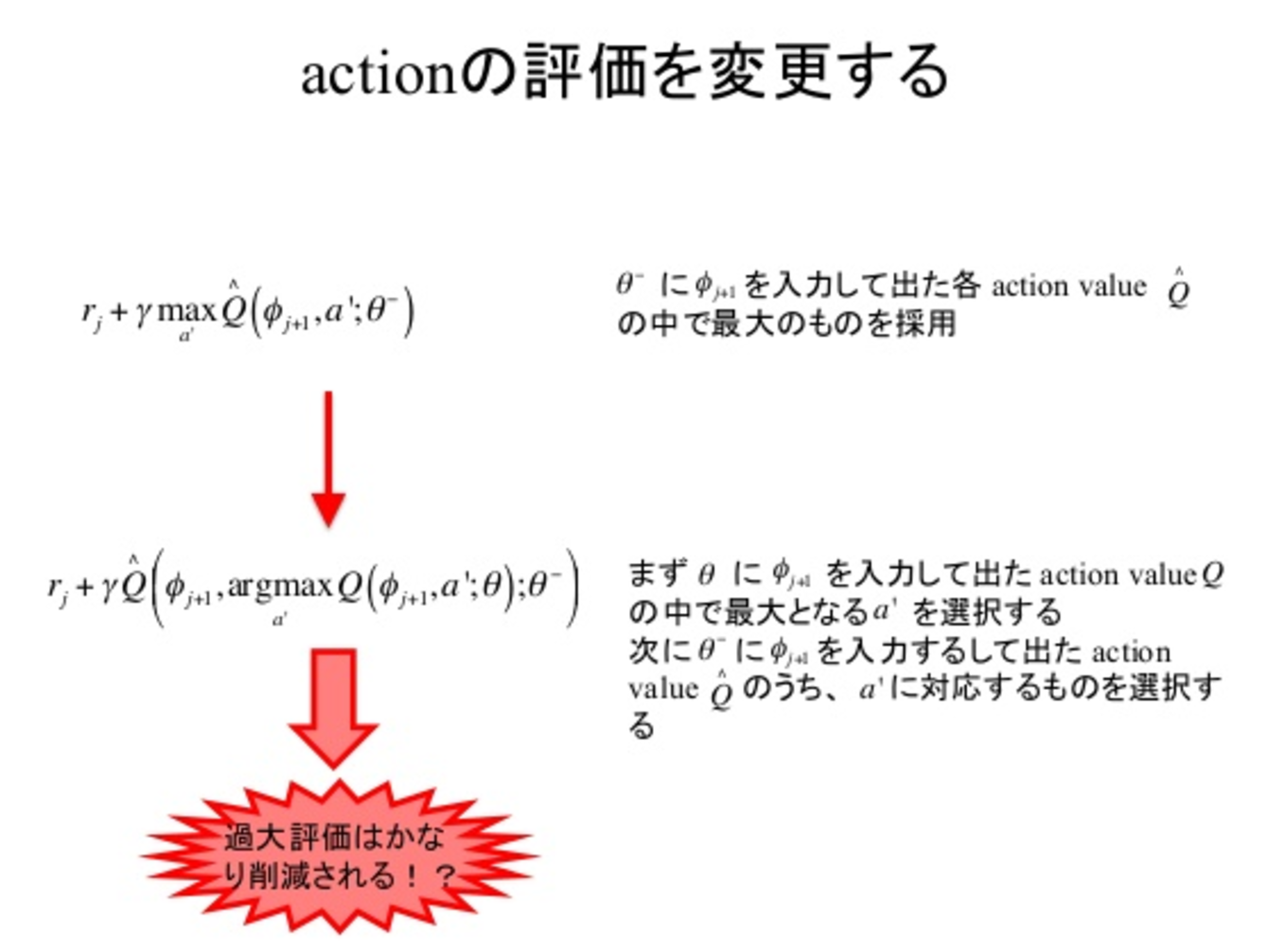
結論
- 学習の固有の推定誤差のために、決定論的であっても、なぜ大規模問題においてQ-learningが過度に最適化できるのを示した。
- アタリゲームの価値見積もりを分析することにより、これらの過大評価は以前に認められたよりも実際上より一般的で重大であることが示した
- この過度のオプティミスムをうまく減らし、より安定した信頼性のある学習をもたらすために、ダブルQラーニングを大規模に使用できることを示した
- 追加のネットワークやパラメータを必要とせずにDQNアルゴリズムの既存のアーキテクチャと深層ニューラルネットワークを使用するDouble DQNと呼ばれる特定の実装を提案
- Double DQNがより良いポリシーを見つけ、Atari 2600ドメイン上で新しい最先端の結果を得ることを示した
A3C(Asynchronous Methods for Deep Reinforcement Learning)
勾配更新を非同期に行う手法の提案。 4つの非同期手法を示し、A3Cが一番結果が良かったことを示している。大きな貢献をしたexperience replayだったが多くのメモリや多くの計算量が必要で、off-policyで学習する必要がある。 experience replayの代わりに、複数agentで実行することで学習を不安定にしていたデータの相関性という問題を回避し、on-policyでの学習を行えるようにした。 http://eratostennis.hatenablog.com/entry/2016/06/05/223401
参考スライド
https://www.slideshare.net/mooopan/a3c-62170605


https://www.slideshare.net/ssuser07aa33/introduction-to-a3c-model








抜粋
我々は、深層ニューラルネットワークコントローラの最適化のための非同期グラジエントデセンを使用する、深層補強学習のための概念的に単純で軽量なフレームワークを提案する。 我々は、標準的な強化学習アルゴリズムの非同期の変形を提示し、並列のアクター学習者が4つの方法のすべてがニューラルネットワークコントローラを訓練することを可能にする訓練に対して安定化効果を有することを示す。 最高のパフォーマンスを発揮する方法であるアクター評論家の非同期型は、Atariドメインの現在の最先端技術を凌駕し、GPUの代わりに単一のマルチコアCPUで半分の時間を訓練します。 さらに、非同期アクター評論家は、視覚的入力を用いて無作為の3D迷路をナビゲートするという新たな課題に加えて、幅広い連続的なモーター制御問題の後に続くことを示す。
結論
我々は、4つの標準強化学習アルゴリズムの非同期バージョンを提示し、安定した方法で様々な領域でニューラルネットワークコントローラを訓練することができることを示した。我々の結果は、提案されたフレームワークが強化学習を通じたニューラルネットワークの安定した訓練が、値ベースの方法とポリシーベースの方法、オフポリシーとオンポリックメソッド、離散的で連続的なドメインで可能であることを示している。16 CPUcores提案された非同期アルゴリズムは、Nvidia K40 GPUで訓練されたDQNよりも、トレーニング時間の半分で現在の最先端技術を上回るA3Cを凌駕してより速く訓練されています.1つの主な発見は、並列アクセルアレーナを使用して共有モデルを更新すると、 3つの価値ベースの方法の学習プロセスに関心を寄せている。これは、DQNの目的で使用されていた体験リプレイなしで安定したオンラインQ-ラーニングが可能であることを示していますが、経験リプレイが有用でないことを意味するものではありません。経験の再現を非同期強化学習フレームワークに組み込むことで、古いデータを再利用することにより、これらのメソッドのデータ効率を大幅に向上させることができます。これは、TORCSのような領域では、環境とのやりとりが、使用しているアーキテクチャーのモデルを更新するよりも費用がかかります。他の既存の強化学習方法を組み込むことも、非同期フレームワークによる深層強化学習の最近の進歩により、私たちの提示した方法は、nステップの方法が修正されたnステップのリターンを直接的にターゲットとして使用することによって、nステップの方法がフォワードビュー(Sutton&Barto、1998)で動作している間に、バックグラウンドビューを使用して、 、1989; Sutton&Barto、1998; Peng&Williams、1996)。 (Schulmanet al。、2015b)の一般化された優位推定のような、優越関数を推定する他の方法を使用することによって、非同期的な有利子 - 批評的方法を潜在的に改善することができる。調査したすべての価値ベースの方法は、Q値の過大評価を減らすさまざまな方法から利益を得ることができた(Van Hasselt et al。、2015; Bellemareet al。、2016)。さらに、最近の研究を真のオンライン時間差法(van Seijen et al。、2015)と非線形関数近似で組み合わせようとするより投機的な方向性がある。これらのアルゴリズムの改良に加えて、ニューラルネットワークアーキテクチャに対する補完的な改良が可能である。 (Wanget al。、2015)の決闘アーキテクチャは、ネットワークにおける状態価値と利点のために別々のストリームを含めることによって、より正確なQ値の推定値を生成することが示されている。 (Levine et al。、2015)によって提案された空間softmaxは、ネットワークがフィーチャ座標を容易に表現できるようにすることによって、値ベースおよびポリシーベースの方法を改善することができる。
アクタークリテック 経験リプレイ(Actor-Critic with Experience Replay)
抜粋
この論文では、安定したサンプルの効率的な体験を再現した、俳優評論家の深層強化学習エージェントを紹介します。ディスクリート57ゲームAtariドメインやいくつかの連続的な制御問題など、困難な環境でも優れたパフォーマンスを発揮します。 バイアス補正による切捨てインポートサンプル、確率的な給油ネットワークアーキテクチャー、新しいトラストリージョンのポリシー最適化メソッドなどのイノベーション。
結論
我々は、連続行動空間と離散行動空間の両方に対応する安定したオフ・ポリシーアクタークリティックを導入した。このアプローチは、RLの最近のいくつかの進歩を原則的に統合する。 さらに、この論文で進められた3つの改良点、すなわち、バイアス補正、確率的なデュエルネットワーク、効率的な信頼領域ポリシー最適化手法を用いた切り捨て重要度サンプリングを統合します。この方法は、Atariの最もよく知られた方法の性能にマッチするだけでなく、 この論文で進められた効率的な信頼領域最適化手法は、連続領域で非常によく機能します。 それは、トレーニングプロセスを安定させることが難しい他の深層学習領域では非常に役立つことがあります。
モデルベースの加速度で継続的深層Q-Learning(Continuous Deep Q-Learning with Model-based Acceleration)
抜粋
モデルレス補強学習は、一連の困難な問題にうまく適用され、最近は大規模なニューラルネットワークポリシーや価値関数を扱うように拡張されました。しかしながら、モデルフリーアルゴリズムのサンプルの複雑さは、特に高次関数近似器を使用する場合、物理システムへの適用性を制限する傾向があります。
本稿では、連続制御タスクのための深層強化学習のサンプルの複雑さを軽減するためのアルゴリズムと表現を検討する。そのようなアルゴリズムの効率を改善するための2つの補完的な手法を提案する。まず、より一般的に使用されるポリシー勾配法およびアクター評定法の代わりに、正規化されたadantage関数(NAF)と呼ばれるQ-learningアルゴリズムの連続的な変形を導き出します。 NAF表現を使用することで、連続再生に経験を再生したQ-ラーニングを適用でき、一連のシミュレートされたロボット制御タスクのパフォーマンスが大幅に向上します。私たちのアプローチの効率をさらに向上させるために、モデルフリー補強学習を加速するための学習モデルの使用を検討します。反復的に再構成された局所線形モデルは、これに特に効果的であり、そのようなモデルが適用可能な領域での学習が大幅に高速であることを示しています。
結論
本稿では、モデルフリーの深層強化学習のサンプル効率を改善するためのいくつかの方法を検討した。最初に、標準化された優位関数(NAF)表現を用いて、標準的なQ学習法を高次元の連続領域に適用する方法を提案する。これにより、非線形価値関数近似の利点を維持しながら、より標準的なアクター評論スタイルのアルゴリズムを単純化することができ、簡単で効果的な適応探査法を採用することができます。最近提案されたディープアクター - ビジニックアルゴリズムと比較して、我々の方法はより早く学習し、より正確な方針を獲得する傾向があることを示す。不完全なモデル学習に直面して、ポリシーの最適性を犠牲にすることなく、学習モデルを組み込むことによって、モデルフリーのRLをどのように加速するかをさらに探求します。 Q-ラーニングはオフポリシー経験を組み込むことができますが、主にオフポリシーによる探索(モデルベースの計画による学習)は、アルゴリズムの全体的なサンプル効率を向上させることはめったにありません。我々は、Qファンクションの正確な推定値を得るために、成功したアクションと失敗したアクションの両方を観察する必要が原因であると仮定します。合成on-policyロールアウトに基づく別の方法では、モデルの学習アルゴリズムが慎重に選択された場合にのみ、サンプルの複雑さが大幅に改善されることを示しています。学習ニューラルネットワークモデルは我々の領域で実質的な改善をもたらさないが、単純に反復的に時間変化する線形モデルは適用可能な領域で実質的な改善をもたらすことを示す。
アクションギャップの拡大:強化学習の新しいオペレータ(Increasing the Action Gap: New Operators for Reinforcement Learning)
抜粋
本稿では、Q関数の新しい最適性保存演算子を紹介します。最初に、表形式の表現のための演算子、一貫したBellman演算子について説明します。これには、ローカルポリシーの一貫性の概念が組み込まれています。この地域の一貫性は、各州における行動ギャップの増加につながることを示している。このギャップを大きくすることで、誘導された貪欲なポリシーに対する近似誤差や推定誤差の望ましくない影響を緩和すると主張している。この演算子は、離散化された連続した宇宙および時間の問題に適用することもでき、我々はこの文脈で優れた性能を示す経験的な結果を提供する。局所的に一貫したオペレータの考え方を拡張して、オペレータが最適性を保つのに十分な条件を導き、一貫したベルマンオペレータを含むオペレータのファミリに導く。結果として、我々はBairdの利点の学習アルゴリズムの最適性の証明を提供し、興味深い特性を持つ他のギャップ増加演算子を導出する。我々は、これらの新しい演算子の強力な可能性を示す60個のAtari 2600ゲームについての実証的な研究で結論づける。
結論
この論文では、一貫性のあるベルマンオペレータが著名なメンバーである最適性保存オペレータのファミリーを紹介しました。 私たちの追求の中心に、行動ギャップを広げたいという希望があります。 我々は、このギャップが近似値関数に対する貪欲なポリシーの実行において中心的な役割を果たし、ベルマンオペレータの簡単な変更によってどれほど有意な性能が得られるかを実験によって示した。 私たちの研究は、実際に信頼性の高い政策を立てる際の古典的なQ機能の不備を浮き彫りにし、価値ベースの強化学習における伝統的な政策と価値の関係に疑問を呈し、価値そのものの概念を再考することがどれほど有益であるかを示している。
DDPG(Deep Deterministic Poilcy Gradients)
参考情報
https://research.preferred.jp/2016/05/yoshidaintern/
抜粋
本稿では、継続的な行動を伴う強化学習のための決定論的なポリシー勾配アルゴリズムを考察する。 決定論的政策勾配は、特に魅力的な形式をとります。これは、行動価値関数の予想される勾配です。この単純な形式は、決定論的な政策勾配が通常の確率的政策勾配よりもずっと効率的に推定できることを意味します。 適切な探索を確実にするために、我々は、エクスプロアーな行動方針から決定論的な目標方針を学習するオフポリシーactor-criticアルゴリズムを導入する。 決定論的な政策勾配アルゴリズムは、高次元の行動空間における確率論的なカウンターパーツよりも有意に優れていることを示す。
結論
我々は、決定論的なポリシー勾配アルゴリズムのためのフレームワークを提示した。 これらの勾配は、それらの確率的な対応物よりも効率的に推定され、作用空間上の問題のある積分を回避する。 実際には、決定論的なアクター評論家は、絶え間なく50の連続的な行動次元で数千倍の確率でその確率的な能力を著しく上回り、20の連続した行動の次元と50の状態の次元を持つ挑戦的な強化学習の問題を解決した。
PCL (Path Consistency Learning)
価値と政策に基づく強化学習のギャップを橋渡しする(Bridging the Gap Between Value and Policy Based Reinforcement Learning)











参考
https://openai.com/research/
https://github.com/pfnet/chainerrl