おおまかな内容
DQNにアクションごとにメモリモジュールを追加
1アクションにつき最大5×105のメモリを格納
RMSProp使用
その他。。。
スコアが断トツに良い。
参考:https://github.com/arXivTimes/arXivTimes/issues/241
State(ゲーム画面をCNNにかけたもの)をkey、その時のQ値をvalueとしてメモリを構成。Stateが来たら各keyとの間で重みを計算し値を読みだす(メモリのサイズが大きい場合はk-nearestを使用)。
抜粋
深層強化学習方法は、広範囲の環境で超 - 人間のパフォーマンスを達成する。この方法は、妥当な性能を達成するためには、人間よりも多くのデータを大量に受け取ることが多く、非効率的である。ニューラルエピソードコントロールを提案する。新しい経験を素早くアサインし、行動することができる深層補足学習エージェント。私たちのエージェントは、価値関数の半表記表現を使用します。過去の経験のバッファーには、状態表現の変化が激しく、 私たちのエージェントは、他の最先端の汎用ディープ・リインフォーアレイン・ラーニング・エージェントよりも大幅に早く学習する広範な環境にわたっています。
1 はじめに
深層強化学習エージェントは、しばしば人間の能力を上回る様々な複雑な環境(Mnihet al。、2015; 2016)で最先端の結果を達成している(Silver et al。、2016)。
これらのエージェントの最終的なパフォーマンスは印象的ですが、これらの手法では、通常、同等のレベルの期待パフォーマンスに到達するためには、人間と比べて環境との相互作用が数桁以上必要です。
たとえば、アタリ2600環境(Bellemare et al。、2013)では、深層Qネットワーク(Mnih et al。、2016)は、2時間後に人間がプレイするのと同様のスコアを達成するために200時間以上のゲームプレイを必要とする(Lake et al。、2016)。
深層強化学習のglacialの学習速度にはいくつかの説得力のある説明があり、本研究ではこれらの問題に焦点を当てています。
1. 確率的勾配降下最適化は、小さな学習率の使用を必要とする。ニューラルネットワークの世界的な近似のために、高い学習率は壊滅的な干渉を引き起こす(McCloskey&Cohen、1989)。学習率が低いということは、経験をニューラルネットワークにしかゆっくりと組み込むことができないことを意味する。
2. 報酬が非ゼロであるインスタンスが非常に少ない可能性があるので、希薄な報酬信号を有する環境は、ニューラルネットワークをモデル化することは困難であり得る。これは、低報酬サンプルが高報酬サンプルを未知数で数え上げるクラス不均衡の一種と見ることができる。その結果、ニューラルネットワークは、より大きな報酬を予測するには不均衡に不十分となり、エージェントが最も報酬を与える行動をとることを困難にする。
3. Q-ラーニングなどのバリューブートストラップ技術による信号伝達の報酬は、環境との以前の対話の履歴を通じて、報酬情報が一度に1ステップ伝播する結果となる。これは、遷移が起こる逆の順序で更新が行われる場合、非常に効率的であり得る。しかし、無相関ミニバイトDQNスタイルを訓練するために、アルゴリズムはランダムに選択された遷移を訓練し、訓練をさらに安定させるために、ゆっくりと更新するターゲットネットワークを使用して、報酬伝播をさらに低下させる必要があります。
この作業では、上に挙げた3つの問題に取り組むことに焦点を当てます。しかし、近年の探検(Osband et al。、2016)、階層的強化学習(Vezhnevets et al。、2016)、移転帰還(Rusu et al。、2016; Fernando et al。、2017)本稿では、上記の深層補強学習の限界に取り組み、広範囲の環境での学習のスピードを飛躍的に向上させる方法であるNeural Episodic Control(NEC)を提案する。
DQN(Mnih et al。、2015)やA3Cの場合のように、最適化の多くのステップ(確率的な勾配降下など)を待つのではなく、経験を積むとすぐに非常に成功した戦略を迅速にラッチすることができます我々の研究は、意思決定における海馬の仮説的役割(Lengyel&Dayan、2007; Blundell et al。、2016)、そして最近のワンショット学習に関する研究(Vinyals et。その他、2016)、ニューラルネットワークを用いた事故を思い出す(Kaiser et al。、2016)。
Ouragentは、長期記憶、連続性、および文脈ベースの検索のような、擬似記憶のいくつかの特徴を有する環境の経験の半表記表現を使用する。半表記表現は、変化の遅いキーストロング高速更新値をバインドする付加専用メモリであり、エージェントによるアクション選択中にキーに対するコンテキストベースの検索を使用して有用な値を検索する。したがって、エージェントのメモリは、従来のテーブルベースのRLメソッドが状態およびアクションから値の見積りにマップするのと同じように動作します。強化学習のための他のニューラルメモリアーキテクチャとは対照的に、メモリのユニークな側面(第3節でより詳細に説明される)は、メモリから検索された値が、深層ニューラルネットワークの残りの部分よりもずっと速く更新され得るということである。
ネットワーク全体に適用される確率勾配降下の更新であり、我々が提示するアーキテクチャは全く異なるが、高速ウェイトに関する作業(Baら、Hinton&Plaut、1987)を連想させる。メモリのもう一つのユニークな側面は、LSTMや微分可能なニューラルコンピュータ(DNC、Graves et al。、2016)のような他のメモリアーキテクチャとは違って、我々のアーキテクチャでは、いつ記憶学習をするのが遅くても、かなりの時間を要する。代わりに、私たちはすべての経験をメモリに書き込むことを選択し、既存のメモリアーキテクチャに比べて非常に大きくなるようにする(Oh et al。(2015)、Graves et al。(2016)とは対照的に)エピソード)。
この大メモリからの読み込みは、kd-treeベースの最近傍を用いて効率的に行われた(Bentley、1975)。この論文の残りの部分は次のように編成されている:セクション2では深層強化学習をレビューする。セクション3では、Neural Episodic ControlアルゴリズムAtari LearningEnvironmentの実験結果を報告する。第5章では、強化学習のための憶測を取り上げ、第6節で今後の研究の概要とNECアルゴリズムの主な利点を要約する。
2 深層強化学習
強化学習エージェント(Sutton&Barto、1998)の行動価値関数は、以下のように定義される:Qπ(s、a)=Eπ[P tγt rt | s、a]であり、ここで、aはエージェントが初期状態sで取った初期行動であり、その後に政策πが続くことを示す期待値である。
割引率γ∈(0、1)は、短期対長期の報酬に有利に働く。
深層Q-Networkエージェント(DQN; Mnih et al。、2015)はQlearning(Watkins&Dayan、1992)を使用して、ステップtで各ステートを取り込むのが最善である値関数Q(st、at)を学習する。エージェントは、この価値関数に基づいて探査とエクスポジションとのトレードオフを行うためのβ-グリーディポリシーを実行する。エージェントはランダムに一様に行動を選択し、そうでなければ、= arg maxa Q(st、a)で行動を選択する.DQNでは、行動値関数Q(st、at)は、畳み込みニューラルネットワークによってパラメータ化され、 (st、at、rt、st + 1)タプルを再生バッファに格納し、その内容は次のようになります。トレーニングに使用されます。このニューラルネットワークは、再生バッファから無作為にサンプリングされた遷移のサブセットについて、ネットワークの出力とQラーニング目標yt = rt +γmaxa Q〜(st + 1、a)との間の二乗誤差を最小化することによって訓練される。ターゲットネットワークQ〜(st + 1、a)は、定期的に更新される値ネットワークの古いバージョンです。ターゲットネットワークとリプレイバッファからの無相関サンプルの使用は、安定したトレーニングにとって重要です。 DQNを改善するいくつかの拡張が提案されている。 Double DQN(Van Hasselt et al。、2016)は、ビーソンの目標計算を減らす。優先順位をつけたリプレイ(Schaul et al。、2015b)は、リプレイ戦略を最適化することによってDouble DQNをさらに改善します。いくつかの著者は、ポリシー上の報酬または最適化に制約を加えることによって、報酬の伝播を改善する方法およびQ学習のバックアップメカニズム(Harutyunyanら、2016; Munosら、2016; Heら、2016)を提案している。
Q *(λ)(Harutyunyanet al。、2016)とRetrace(λ)(Munos et al。、2016)は、ポリシスサンプルを組み込み、ポリシー上学習とオフポリシー学習とを流体的に切り替えるQ学習目標の形を変える。 Munos et al。 (2016)は、ポリシーなしのサンプルを組み込むことで、代理店がアタリ環境でより早く学習できるようになり、報酬の伝播が真に深層強化学習の効率のボトルネックになっていることがわかります。
A3C(Mnih et al。、2016)は、DQNとはまったく異なるもう一つのよく知られている深部補強学習アルゴリズムである。 それは政策勾配に基づいており、ポリシー上完全に学習された政策価値とそれに関連する価値関数の両方を学ぶ(λ= 1のQ(λ)の場合と同様)。 興味深いことに、Mnihらは、 (2016)は、LSTMメモリを他の畳み込みニューラルネットワークアーキテクチャに追加してエージェントにメモリの概念を与えましたが、これはAtariゲームのパフォーマンスに大きな影響を与えませんでした。
3 ニューロエピソードコントロール
我々のエージェントは、ピクセル画像を処理する畳み込みニューラルネットワーク、アクションごとに1つのメモリモジュール、アクションメモリからの読み出しをQ(s、a)値に変換する最終的なネットワークという3つのコンポーネントで構成されます。 畳み込みニューラルネットワークでは、DQN(Mnih et al。、2015)と同じアーキテクチャを使用します。
3.1。 微分可能なニューラルディクショナリ
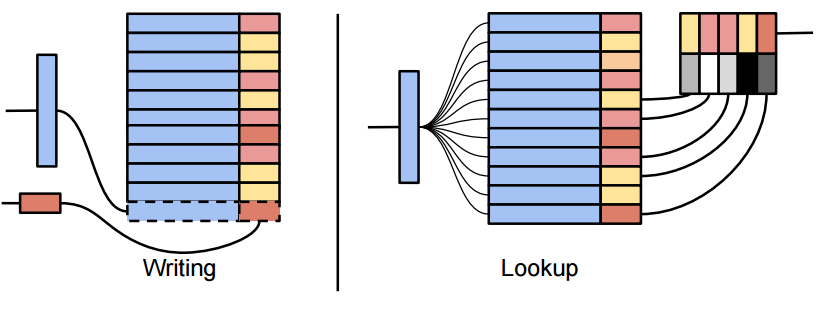
図1.微分可能なニューラルディクショナリ上の操作の図。
ECは単純なメモリモジュールMa =(Ka、Va)を持ち、ここで、KaとVaはそれぞれベクトルの数が同じであるベクトルの動的サイズ配列である。メモリモジュールは、キーから対応する値への任意の関連付けとして機能する プログラムで見つかった辞書データタイプとよく似ています。 このように、我々はこの種のメモリモジュールを微分可能なニューラルディクショナリ(DND)と呼ぶ。図1に示すように、DNDには2つの操作が可能である:ルックアップ(調べる?)と書き込み。aDNDのルックアップを実行すると、キーhが出力値にマップされるo:

viは配列Vaのi番目の要素であり、
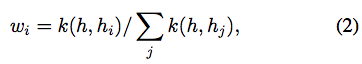
hiは配列Kaのi番目の要素であり、k(x、y)はベクトルxとyの間のカーネル、例えばガウスまたはインナーカーネルである。したがって、DNDにおけるルックアップの出力は、メモリ内の値の加重値であり、加重は、メモリ内の対応するキーとルックアップキーとの間の正規化されたカーネルによって与えられる。非常に大規模なクエリをスケーラブルにするために、私たちは2つの近似を行います。まず、(1)を最近接p-nearest neighbor(通常p = 50)に制限します。
次に、近似アルゴリズムを使用して、kdツリーに基づいてルックアップを実行する(Bentley、1975).DNDがクエリーされた後、新しいキー値ペアがメモリに書き込まれる。書き込まれたキーは、見上げたキーに対応しています。関連する値はアプリケーション固有です(NECエージェントのアップデートを指定する場合は以下を参照)。 DNDへの書き込みは追記専用です:キーと値はそれぞれ配列Kaand Vaの終わりに追加することでメモリに書き込まれます。既にキーがメモリ内に存在する場合、対応する値は複製されるのではなく更新されます。
DNDは、Blundell et al。に記載されているメモリモジュールの微分可能なバージョンであることに注意してください。 (2016)。 分類については、Vinyalsら(2016; Kaiser et al。、2016)に記載されているメモリおよびルックアップスキームへの一般化でもある。
3.2。 エージェントのアーキテクチャ
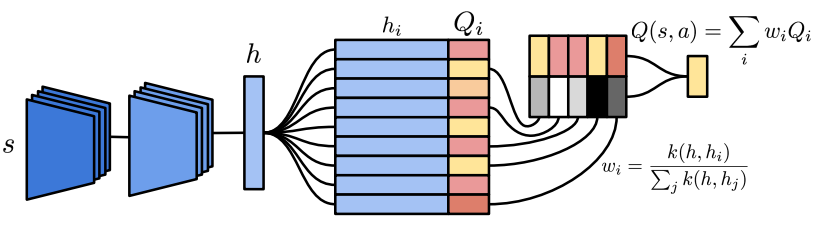
図2.単一アクションのためのエピソードメモリモジュールのアーキテクチャa。 現在の状態を表すピクセルは、左下に畳み込みニューラルネットワークを通って入り、Q(s、a)の推定値は右上に出る。 グラデーションはアーキテクチャ全体を流れます。
図2は、NECエージェントの一部としてDNDを示し、アルゴリズム1はNECアルゴリズムの概要を示しています。 ピクセル状態sは、畳み込みニューラルネットワークによって処理され、キーhを生成する。 次に、keyhを使用して、DNDから値を検索し、メモリアレイの各要素の処理において重量を計算する。 最後に、出力はDNDの値の加重和です。 DEC内の値は、NECエージェントの場合には、対応するキー - 値対を元々メモリに書き込む状態に対応するQ値である。 したがって、このアーキテクチャは、与えられた単一のアクションに対してQ(s、a)の推定値を生成する。 エージェントは、ネットワークの畳み込み部分を各DND Maごとに共有しながら、エージェントが取ることができる各アクションごとに1回複製されます。 NECエージェントは、各ステップで最も高いQ値の見積もりでアクションを実行します。 実際には、訓練期間中に「?」を使用しています。

3.3。 (s、a)個のペアをメモリに追加する
NECのエージェントは行動するので、新しいキーと値のペアを継続的にメモリに追加します。 キーは、対応するアクションのメモリに付加され、畳み込みニューラルネットワークによって符号化されたクエリkeyhの値をとる。 我々は適切な対応価値の問題に直面する。Blundell et al。 (2016年)、モンテカルロのリターンは記憶に書き込まれました。 私たちは、モンテカルロ・リターン(オン・ポリシー)とオフ・ポリシー・バックアップの組み合わせがより良く機能することを発見しました.NNのために、Mnihら(2016)のようにNステップQラーニングを使用することを選択しました。 Peng&Williams、1996)これは、以下のN on-policy報酬を追加し、残りの軌道に対する割引報酬の合計をオフ・ポリシーでブートストラップする。 次いで、N段階Q値推定値は、
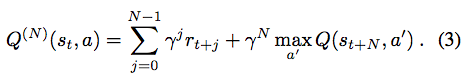
(3)のブートストラップ項、maxa0 Q(st + N、a0)は、各動作aについてすべてのメモリMaをクエリし、返された最も高い推定Q値を取ることによって求められる。 このような最も初期の値は、特定の(s、a)対が発生した後のNステップであることに留意されたい。状態アクション値が既にDND内に存在する場合(すなわち、全く同じキーhが既にKaにある) Vaに存在する対応する値Qiは、従来の表形式のQ学習アルゴリズムと同様に更新される。
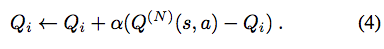
ここで、αはQ更新の学習率である。 状態がまだ存在しない場合は、Q(N)(st、a)がVaに付加され、hがKaに付加される。 私たちのエージェントは、古典的な表形式のQ-learningエージェントと同じように、値の関数を学習します。ただし、Q-tableが時間とともに増加する点が異なります。 αが高い値を取ることができ、安定した表現を有する反復された状態が、それらの値の関数推定値を迅速に更新することを可能にすることが分かった。 さらに、メモリアップアップをバッチ処理すること(例えば、エピソードの最後に)は、計算性能を向上させるのに役立つ。 メモリの最大容量に達すると、最近隣に表示されたアイテムを上書きします。
3.4。 学習
エージェントパラメータは、所与の動作に対する予測Q値と、再生バッファからのランダムにサンプリングされたミニバッチに対するQ(N)推定との間のL2損失を最小化することによって更新される。 具体的には、再生バッファにタプル(st、at、Rt)を格納する。ここで、NはNステップQruleの水平線であり、Rt = Q(N)(st、a)はターゲットネットワークの役割を果たす DQN(再生バッファはDQNよりもかなり小さい)。 次に、これらの(st、at、Rt) - 組はランダムに一様にサンプリングされ、トレーニングのためのミニバッチを形成する。 図2のアーキテクチャは完全に区別可能であり、勾配降下によるこの損失を最小限に抑えることができることに留意されたい。 バックプロパゲーション(backpropagation)は、畳み込み演算ネットワークの重みとバイアスと、この損失の勾配を使用して、各ペアに固有のメモリのキーと値を更新します。
4.実験
我々は、神経のエピソード制御が、複雑な領域で実際にフォルモアのデータ効率的な学習を可能にするかどうかを調べた。問題の領域としてAtari Learning Environment(ALE; Bellemare et al。、2013)を選択した。私たちは、Schaulらが使用した57個のAtariゲームでこの方法をテストしました。 (2015a)は、さまざまな課題を含んでいるため、興味深い一連のタスクを形成します。これは、ゲーム全体での激しい報酬とは非常に異なる規模です。 DQNやA3Cの変種など、これらの領域に適用される最も一般的なアルゴリズムは、数千時間のゲーム内時間を必要とします。すなわち、データは非効率的です.MFECだけでなく、A3CとDQNの5つの変種をベースラインとして考えます。 、2016)。 A3C(Mnih et al。、2016)とDQN(Mnih et al。、2015)の基本的な実装を比較する。 Q *(λ)(Harutyunyan et al。、2016)andRetrace(λ)(Munos et al。、2016)のように、クレジット割り当てをより速く伝播させることにより、より多くのデータ効率を目的とするλ戻り値を組み込んだ2アルゴリズム(Sutton、1988) 。また、より顕著なトランジションをより頻繁に再生してデータ効率を改善するDQN Prioritized Replayと比較します。結果はすべてのAtariゲームで利用できないため、DRQN(Hausknecht&Stone、2015)やFRMQN(Oh et al。、2016)と直接比較していませんでした。 DRQNの場合、報告された性能はPrioritized Replayよりも低いことに注意してください。すべてのアルゴリズムはγ= 1を使用するMFECを除いて割引率γ= 0.99を使用して訓練されました。MFECの実装では、元の刊行物はテストされたAtariのゲームでより良い性能を得ました。
NECのハイパーパラメータに関しては、DQNと同じ畳み込みアーキテクチャを選択し、1アクションにつき最大5×105のメモリを格納しました。 勾配降下訓練にはRMSPropアルゴリズム(Tieleman&Hinton、2012)を使用しました。各アクションを4回繰り返すことを含め、(Mnih et al。、2015)と同じ前処理ステップを適用します。 NステップのQ推定値について、N = 100の地平線を選択した。我々の再生バッファは、観察された唯一の105ステート(DQNの106に対して)およびそれらのNステップQ推定値を格納する。 Wedo one再生は、サイズ16の観測フレームごとに更新され、サイズ32のaminibatchで更新されます。我々は、すべての実験において最も近いneighboursp = 50の数を設定しました。 カーネル関数については、短距離の平均値と大きい距離の重み付き逆距離の間を補間する関数を選択しました。より正確には、次のようになります。
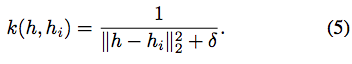
直感的には、すべての隣人が遠く離れている場合、我々はすべての重みを1つのデータ点に置くことを避けたい。例えば、ガウス核カーネルは、最も近いものについてすべての近傍セクタを指数関数的に抑制する。私たちが選んだカーネルは、大きなテールを持つ利点があります。これにより、アルゴリズムが堅牢になり、カーネルのハイパーパラメータに敏感でないことがわかりました。式(4)における残りのハイパーパラメータ(SGDlearning-rate、高速更新学習率α、埋め込みの次元数、式(3)のQ(N)、および探索確率)私たちは超音速掃引onsixゲームを走らせました:ビームライダー、ブレークアウト、ポン、Q *バート、シークエストとスペースインベーダー。我々は、このゲームのサブセットの中央値で最もよく実行されたハイパーパラメータ値を選んだ(Bellemareet al。(2013)によって記述され、Mnihら(2015)が守った共通の検証手順)。 1.小さなデータ領域(2000万フレーム未満)では、NECは他のすべてのアルゴリズムを明らかに実行します。この差は特に500万フレームが観測される前に発表されています.4000万フレームだけでPrioritisedReplayのDQNは平均してNECを上回ります。図3から7は、6試合(エイリアン、ボウリング、ボクシング、凍傷、英雄、パックマン、ポン)の学習曲線を示しています。これは、NECのパフォーマンスの詳細な図を提供するために、185時間のゲームプレイに対応しています。 NECの業績のいくつかのステレオタイプのケースが観察されることがあります。すべての学習曲線は、5つの異なる初期ランダムシードにわたる平均性能を示す。 MECとNECを200.000フレーム毎に評価し、その他のアルゴリズムは100万ステップで評価する。ほとんどのゲームで、NECは初期段階(表1も参照)を学習する上で著しく高速であり、 NECは平均でMFECを上回っています(表2参照)。NECはMFECとは対照的に、報酬信号を使用して値の補間に適した埋め込みを行います。この差は、少数のピクセルが各アクションの価値を決定するゲームでは特に重要です。 MFECの単純化されたバージョンは、ランダム投影によるピクセル空間でのL2距離への近似を使用し、小さいが、最も関連性のある詳細には焦点を合わせることができない。 MFECの別のバージョンでは、モデルのフレームを学習するために、変動オートエンコーダ(Kingma&Welling、2013)の潜在的表現の距離を計算しました。この潜在的な表現は報酬に依存せず、例えば現在のスコアの表示のような無関係な詳細の対象となる。
A3C、DQN、および関連するアルゴリズムでは、訓練の安定性1のために[-1,1]の範囲に報酬が必要です(Mnih et al。、2015)。 NECとMFECは報酬のクリッピングを必要としないため、クリッピングを必要とするゲームで他のアルゴリズムと比べて行動やパフォーマンスが質的に変化します(Bowling、Frostbite、H.E.R.O.、PacMan、Alien of the sevenの表示)。
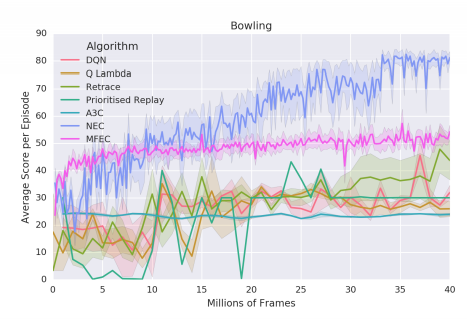
図3.ボウリングの学習曲線
AlienとMs. Pac-Manはどちらもキャラクターをコントロールします。少年報酬を収集する簡単な方法があります。そこにはたくさんのアイテムがありますが、エージェントには負けない少数を避けます。一方、エージェントは敵を敵にする特別なアイテムを拾うことができ、エージェントは攻撃を受けることができ、小さな報酬を集めることよりも大きな報酬を得ることができます。既存のパラメトリック手法を用いて訓練されたエージェントは、クリッピングが大きな報酬と小さな報酬の間に差異がないことを意味するので、これにほとんど関心を示さないようにする。したがってNECでは報酬クリッピングが必要ないため、NECが非クリッピングスコア(真のスコア)を最大にしているため、他のアルゴリズムよりも大幅に優れている可能性があります。また、報酬のクリッピングが影響を与えないポンとボクシングの他のアルゴリズムよりも優れています。すべての元報酬が[-1、1]の範囲にあるため、NECは他の人よりも優れた得点を上回っているわけではありませんが、これは非常に効率的です。図10では、プライオリティリプレイとMFECと比較して、全57回のAtariゲームを1000万フレームで正規化したスコア。各アルゴリズムごとに独立してゲームをランク付けし、y軸にデシルを表示します。NECは1000万フレーム以内にゲームの25%で人間レベルのパフォーマンスを達成することができます。 Wecanは、NECがMFECと優先リプレイよりも優れていることを見ています。
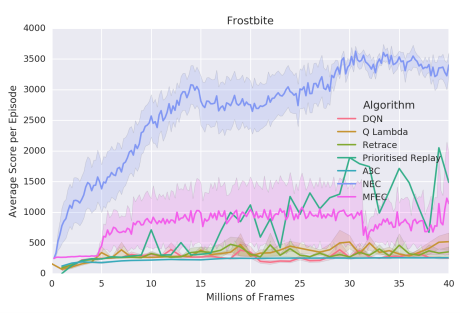
図4. Frostbiteの学習曲線
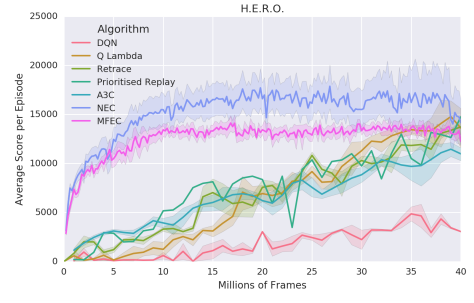
図5. Learning curve on H.E.R.O.
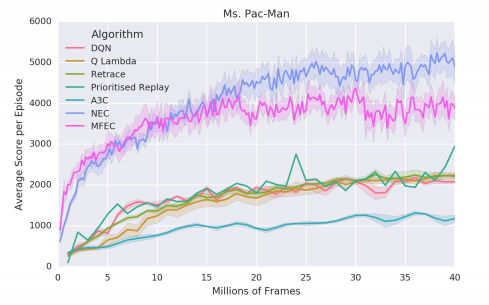
図6. Learning curve on Ms. Pac-Man.
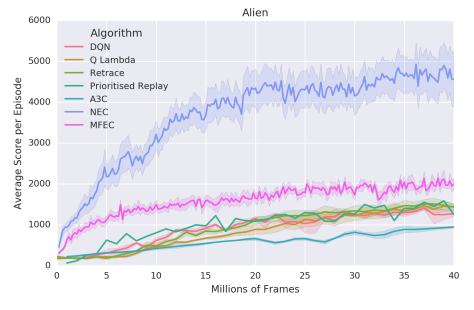
図7. Learning curve on Alien
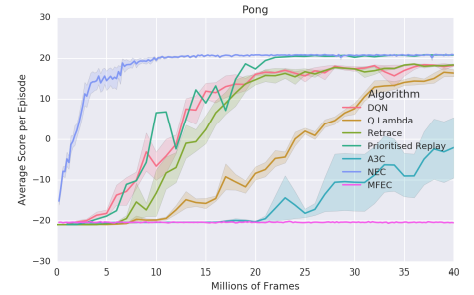
図8. Learning curve on Pong.
バックグラウンド
Paper #1 - Hippocampal Contributions to Control (2007)
https://papers.nips.cc/paper/3311-hippocampal-contributions-to-control-the-third-way.pdf
2007年、LengyelとDayanは質問を提起しました。なぜ、エピソード記憶が有用なのですか?
あなたが私のようなコンピュータ科学者であれば、その質問やその意義をすぐには理解できないかもしれません。人間の記憶システムがどのように構築されているかを簡単に概観してみましょう。
ヒトには、明示的(宣言的)な記憶と暗黙的(手続き的)記憶の2種類の長期記憶があります。 明示的な記憶は意図的にあなたの心の前に持って来る想いを記憶し、さらに2つのサブカテゴリに分かれています:エピソード記憶と意味記憶。 エピソードの記憶には、人、場所、感情、コミュニケーションを含む特定の個人的な経験が含まれています - 私はあなたの頭の中で遊ぶことができる小さなビデオクリップとしてエピソードの記憶を考えています。 これは、ボヘミアン・ラプソディへのすべての言葉を知るなどの一般化された理解を含んでいる意味記憶、あるいは人間の活動が気候変動に対する実質的な原因因子であるという意味記憶とは異なる。 別の言い方をすれば、質問は、「一般化可能な情報を覚えていることに加えて、特定の記憶をなぜ覚えているのだろうか?
参考
https://arxiv.org/pdf/1703.01988.pdf
http://rylanschaeffer.github.io/content/research/neural_episodic_control/main.html