モデルの学習結果を保存しておけるツール。
https://github.com/mitdbg/modeldb
modeldbの派生?でkubernetesと組み合わせて、ハイパーパラメータチューニングするものが2018/4に出来ていたみたい。ここまでは追えてなかった。不覚。
ちなみにkubeflowは機械学習環境作るマン。
modeldb自体はかっこいいUIだし悪くはないので、kubernetesの人気に乗せて有名になっていく可能性あるなと。
https://github.com/kubeflow/katib
Machine Learning Toolkit for Kubernetes
https://github.com/kubeflow/kubeflow
アーキテクチャ
多様な分析業務のワークフローに合う様に柔軟性に注意して設計されてます。
scikit-learnとsparkとapiで使用可能。
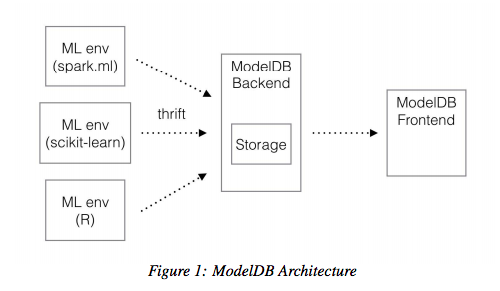
使い方のイメージ
APIで使う
API以外はscikit learnとsparkで使えるが、ラッパーでラップされてるので非常に簡単に使える。
kerasや他のライブラリで使いたい場合はAPIで使えば、どのフラームワークでも使える。
from modeldb.basic.ModelDbSyncerBase import *
import yaml
apiでプロジェクトを作る。
syncer_obj = Syncer.create_syncer("Sample Project", \
"test_user", \
"use sync_all", \
host="backend")
yamlでもいいし、jsonで作ってもいいし。
filename = "/modeldb/client/python/samples/basic/YamlSample.yaml"
print "Syncing all data from file..."
syncer_obj.sync_all(filename)
syncer_obj.sync()
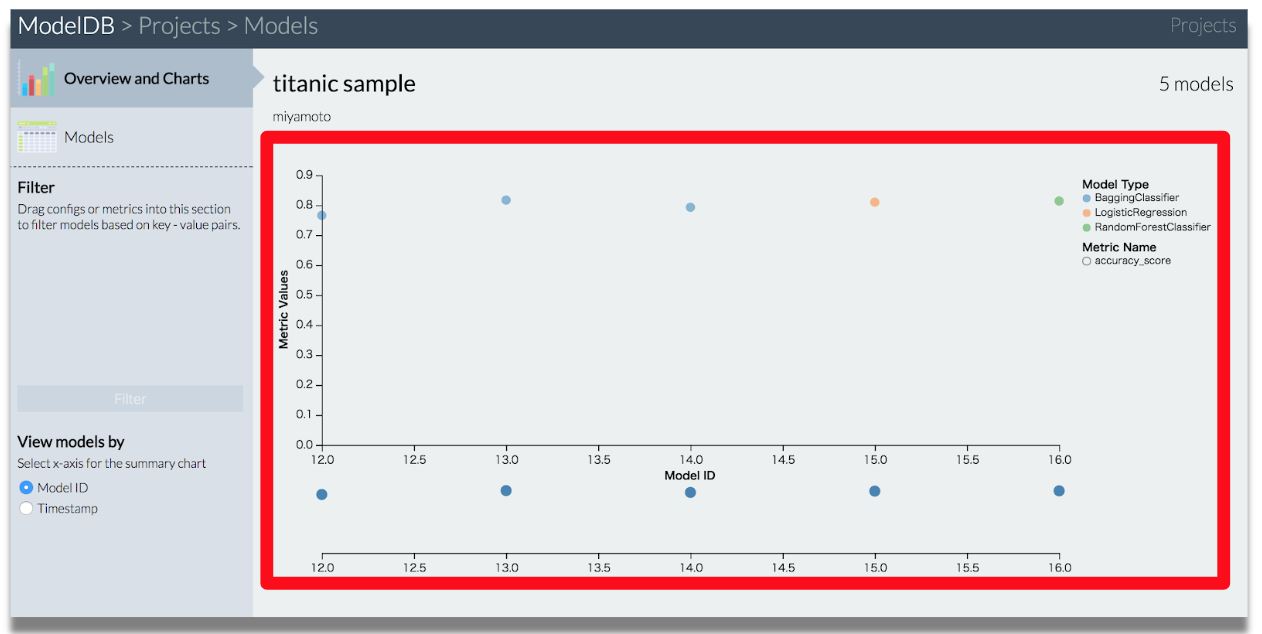
学習済みのモデルがスコアごとに可視化される。
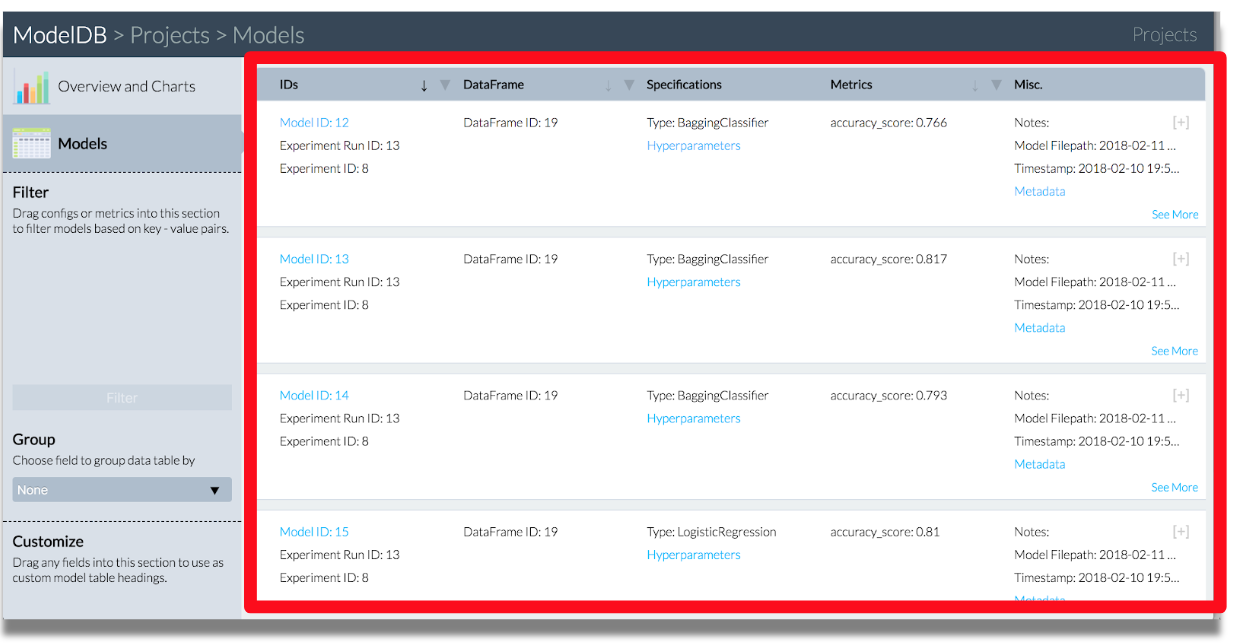
モデル一覧の閲覧。
BaggingClassiferでフィルタリング。
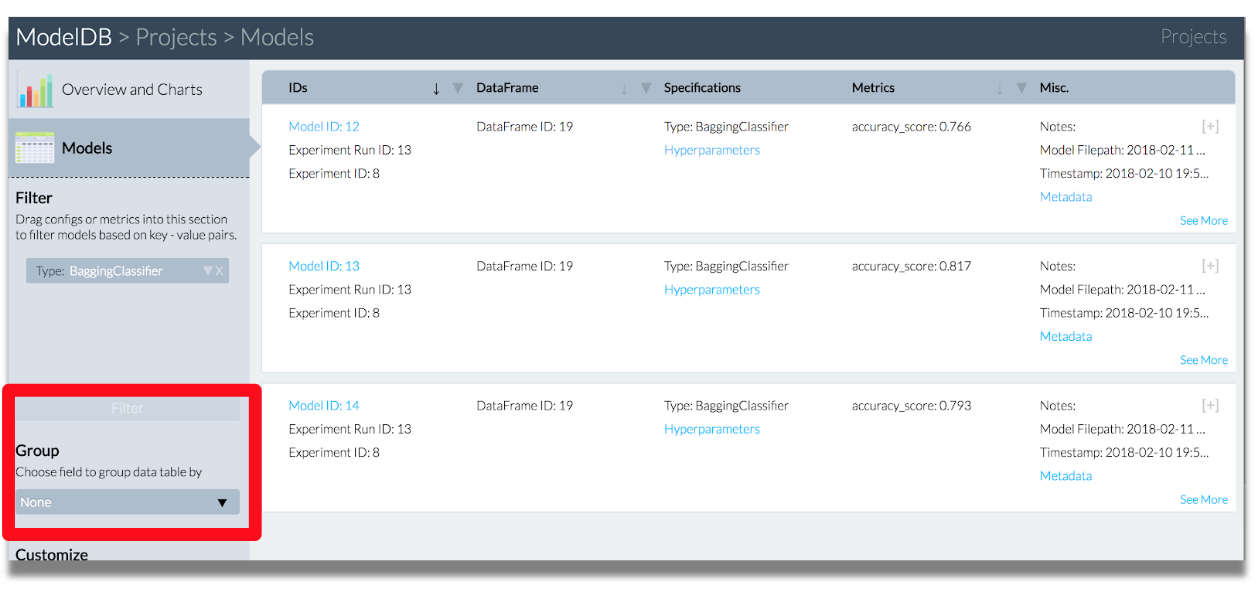
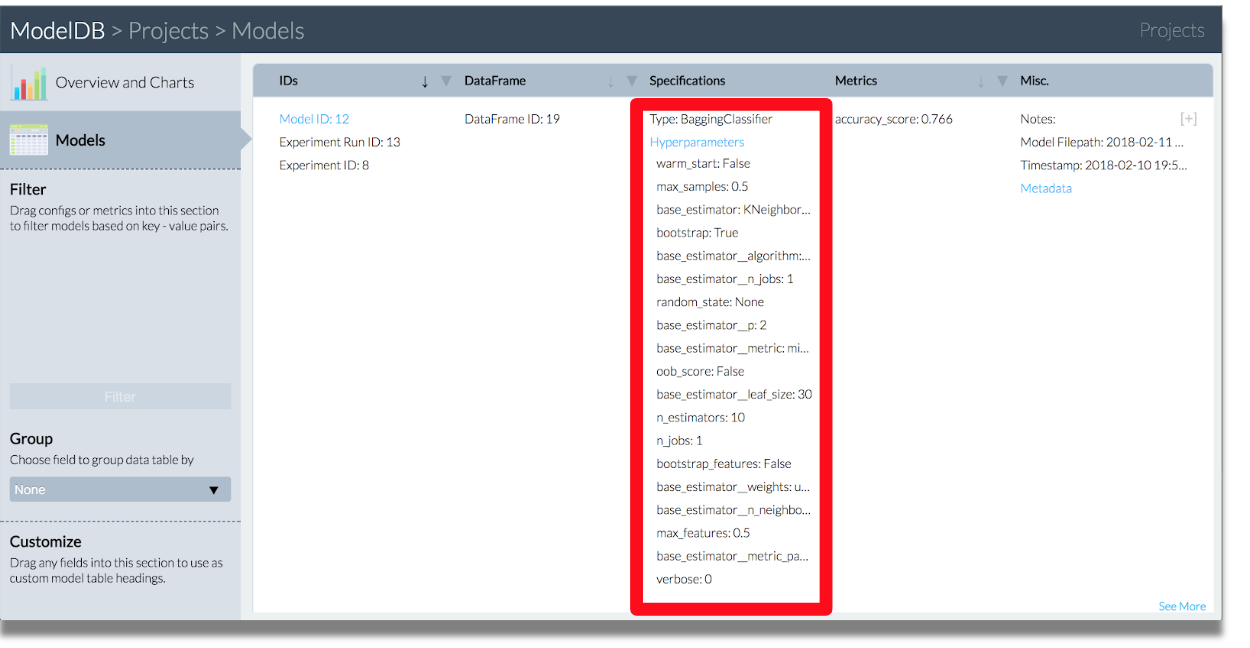
パラメータの確認。
モデルの保存場所の確認。
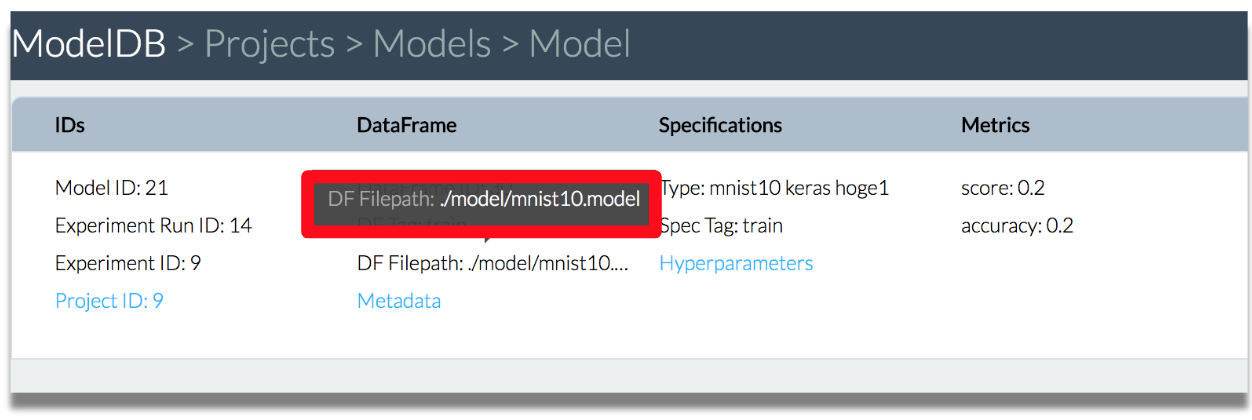
作業履歴を確認。
人ごとの作業履歴が見れるのは、管理側としてはいい機能。
環境設定
環境:Ubuntu
docker楽だよ。
1、docker-composeを入れる
2、git clone modeldb
3、docker-compose up
サーバー側を立ち上げ
dockerであげた場合はきにする必要はないですが、マニュアルで入れる場合は下記を意識。
1、docker-composeを入れる
ここを参考
https://qiita.com/taroshin/items/22bb360b18a0a24871dd
sudo COMPOSE_VERSION=1.18.0 bash -eu << '__EOT__'
echo ${COMPOSE_VERSION}
curl -L https://github.com/docker/compose/releases/download/${COMPOSE_VERSION}/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
chown root:docker /usr/local/bin/docker-compose
chmod ug+x /usr/local/bin/docker-compose
update-alternatives --install /usr/bin/docker-compose docker-compose /usr/local/bin/docker-compose 10
__EOT__
scikit-learn client:
Python 2.7**
pip
scikit-learn 0.17**
spark.ml client:
Java 1.8+
Spark 2.0.0**
2、dockerでセットアップ
git clone https://github.com/mitdbg/modeldb
cd modeldb
docker-compose up
デフォルトでは3000番ポート。
初めは何もないですが学習結果を保存していくことが可能です。
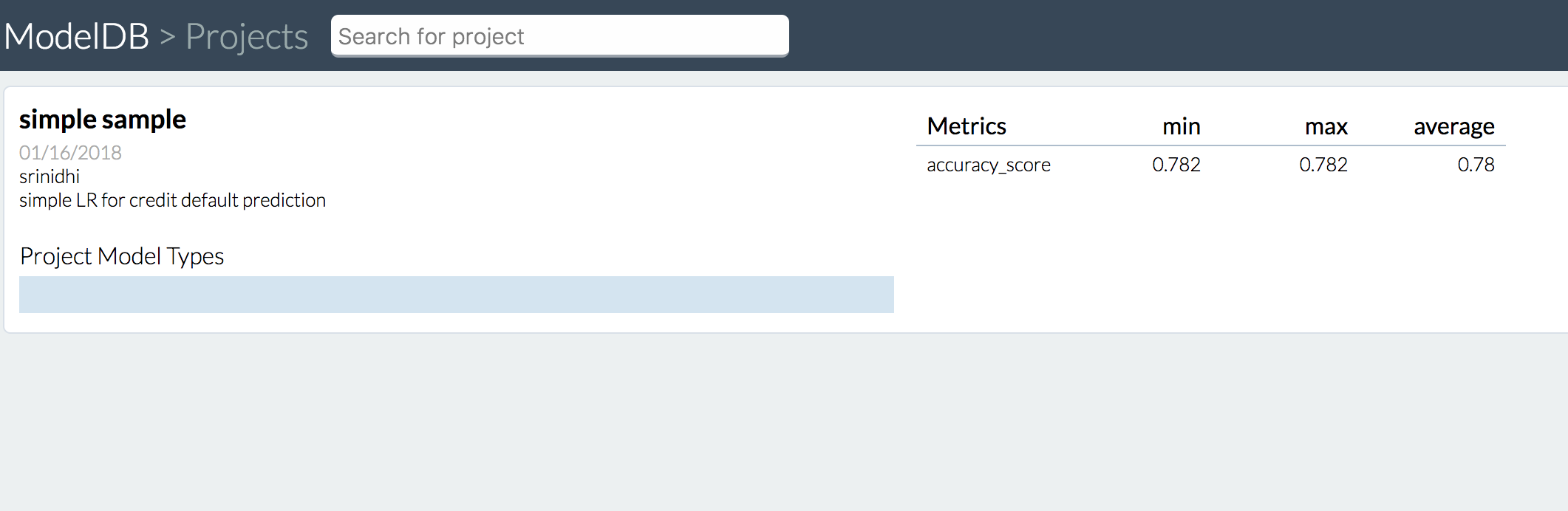
sklearnで学習する
メソッド名が少し変わっているだけで使いやすい。
fit->fit_sync
など
cd modeldb/client/python/samples/sklearn
python SimpleSampleWithModelDB.py
import pandas as pd
from sklearn import linear_model
from sklearn.metrics import accuracy_score
from modeldb.sklearn_native.ModelDbSyncer import *
from modeldb.sklearn_native import SyncableMetrics
DATA_PATH = '../../../../data/'
'''
Source: http://archive.ics.uci.edu/ml/datasets/default+of+credit+card+clients
'''
# modeldb start
name = "simple sample"
author = "srinidhi"
description = "simple LR for credit default prediction"
syncer_obj = Syncer(
NewOrExistingProject(name, author, description),
DefaultExperiment(),
NewExperimentRun("credit test"))
# modeldb end
# modeldb start
df = pd.read_csv_sync(DATA_PATH + 'credit-default.csv', skiprows=[0])
# modeldb end
target = df['default payment next month']
df = df[["LIMIT_BAL", "SEX", "EDUCATION", "MARRIAGE", "AGE"]]
x_train, x_test, y_train, y_test = cross_validation.train_test_split_sync(
df, target, test_size=0.3)
lr = linear_model.LogisticRegression(C=2)
# modeldb start
lr.fit_sync(x_train, y_train)
# modeldb end
# modeldb start
y_pred = lr.predict_sync(x_test)
# modeldb end
# modeldb start
score = SyncableMetrics.compute_metrics(
lr, accuracy_score, y_test, y_pred, x_train, "features",
'default payment next month')
# modeldb end
# modeldb start
syncer_obj.sync()
# modeldb end
from modeldb.sklearn_native.ModelDbSyncer import *
from modeldb.sklearn_native import SyncableMetrics
from modeldb.basic.Structs import (
Model, ModelConfig, ModelMetrics, Dataset)
from modeldb.basic.ModelDbSyncerBase import Syncer
# Create a syncer using a convenience API
name = "simple sample"
author = "srinidhi"
description = "simple LR for credit default prediction"
syncer_obj = Syncer(
NewOrExistingProject(name, author, description),
DefaultExperiment(),
NewExperimentRun("credit test"))
datasets = {
"train": Dataset("/path/to/train", {"num_cols": 15, "dist": "random"}),
"test": Dataset("/path/to/test", {"num_cols": 15, "dist": "gaussian"})
}
model = "model_obj"
mdb_model1 = Model("NN", model, "/path/to/model1")
model_config1 = ModelConfig("NN", {"l1": 10})
model_metrics1 = ModelMetrics({"accuracy": 0.8})
mdb_model2 = Model("NN", model, "/path/to/model2")
model_config2 = ModelConfig("NN", {"l1": 20})
model_metrics2 = ModelMetrics({"accuracy": 0.9})
syncer_obj.sync_datasets(datasets)
syncer_obj.sync_model("train", model_config1, mdb_model1)
syncer_obj.sync_metrics("test", mdb_model1, model_metrics1)
syncer_obj.sync_model("train", model_config2, mdb_model2)
syncer_obj.sync_metrics("test", mdb_model2, model_metrics2)
syncer_obj.sync()
そのうちハイパーパラメータチューニングの分散環境用のkatibの方も触ってみたい。