一般的な活性化関数の違いについてメモ。
結論から言うとReLuを使おう。
それでもDead Neuronsが生まれるならLeaky ReLuなど使おう。
ここにはもっと細かく書かれてる。
https://github.com/EmbraceLife/sigmoid-SEE-vs-relu-softmax-cross-entropy/blob/master/relation-sigmoid-SSE-vs-relu-softmax-cross-entropy.ipynb
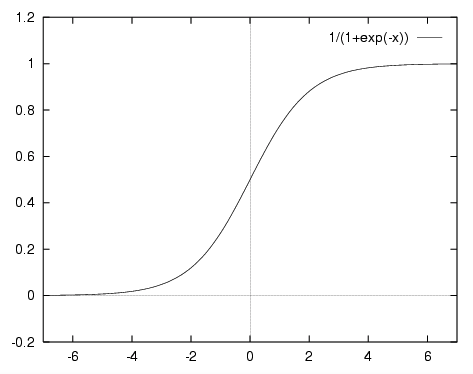
#Sigmoid or Logistic
f(x)= 1 / (1 + exp(-x))
- 勾配爆発問題
- 第2に、その出力はゼロにセンタリングされません。これは、勾配の更新を異なる方向に行きすぎるようにします。0 <出力<1であり、最適化がより困難になる。
- シグモイドは飽和してグラデーションを殺します。
- シグモイドは収束が遅い。
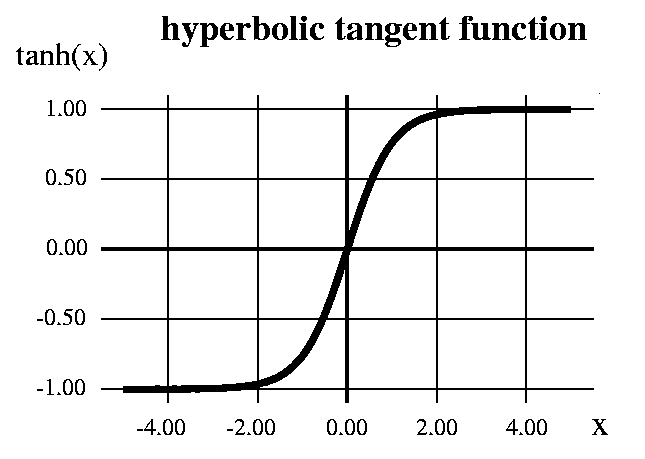
#Hyperbolic Tangent
f(x)= (1 - exp(-2x)) / (1 + exp(-2x))
-1から1までの範囲-1すなわち-1 <出力<1であるため、出力はゼロにセンタリングされます。
ですが勾配の問題は存在。
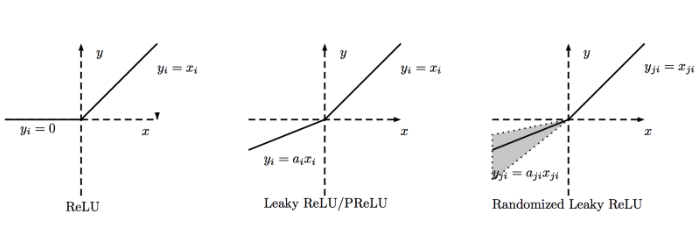
#ReLu
これは過去2〜3年で非常に普及しました。最近Tanh関数とのコンバージェンスが 6倍改善されていることが証明されました。
機械学習とコンピュータサイエンスでは、最もシンプルで一貫性のあるテクニックと方法が優先され、最良の方法であることに気付きました。したがって、消失勾配の問題を回避し、修正する。ほとんどすべての深い学習モデルは現在 ReLuを使用しています。
しかし、その限界は、ニューラルネットワークモデルの隠れ層内でのみ使用すべきであるということです。
したがって、出力層では、Classification問題にSoftmax関数を使用してクラスの確率を計算し、回帰問題に対しては単純に線形関数を使用する必要があります。
ReLuのもう1つの問題は、勾配がトレーニング中に壊れやすく、死ぬことがあるということです。それは、いかなるデータポイントでも再び活性化されないようにする、ウエイトの更新を引き起こす可能性があります。ReLuがDead Neuronsをもたらすと言うだけである。
この問題を解決するために、Dead Neuronsの問題を解決するためにLeaky ReLuという別の修正が導入されました。更新を生かし続けるために、小さなスロープが導入されています。
#結論
今日ではReLuを使用するべきです.ReLuは隠されたレイヤーにのみ適用する必要があります。我々のモデルが訓練中に死んだニューロンを形成するならば、漏れやすいReLuまたはMaxout関数を使うべきです。
SigmoidとTanhは、神経ネットワークモデルの訓練に多くの問題を引き起こす、勾配が消える問題のため、今日は使用されるべきではないということだけです。