大まかにいうと
v1よりちょっと早くなったよ
検出できるクラス数が増えたよ(9000クラス)
犬の中にいろんな種類がいるよねってのまで学習できてる。すごい。


imagenet自体がwordnetという階層構造になっているので、
それでクラスを増やして各ノードで条件付き確率を予測が可能なようだ。
imagenet

http://image-net.org/about-overview
ImageNetは、WordNet階層に従って編成された画像データセットです。
WordNetの意味のある概念は、複数の単語や語句によって記述される可能性があり、「同義語セット(synonym set)」または「synset」と呼ばれます。WordNetには100,000以上のsynsetがあり、その大部分は名詞(80,000+)です。ImageNetでは、各synsetを説明するために平均1000枚の画像を提供することを目指しています。
抜粋
9000種類以上のオブジェクトカテゴリを検出できる最先端のリアルタイムオブジェクト検出システムYOLO9000を紹介します。最初に、我々はYOLO検出法の様々な改良を提案する。改良されたモデルYOLOv2は、PASCAL VOCやCOCOのような標準的な検出タスクの最先端技術です。斬新でマルチスケールのトレーニング方法を使用することで、同じYOLOv2モデルをさまざまなサイズで実行でき、速度と精度のトレードオフが容易になります。 67 FPSでは、YOLOv2はVOC 2007で76.8 mAPになります.40 FPSでは、Yolov2が78.6 mAPとなり、ResNetやSSDを使用したRCNNの高速化など、最先端の方法よりも優れています。最後に、物体の検出と分類を共同して行う方法を提案する。この方法を使用して、COCO検出データセットとImageNet分類データセットでYOLO9000を同時に訓練します。私たちの共同トレーニングにより、YOLO9000はラベル付けされた検出データを持たないオブジェクトクラスの検出を予測できます。我々は、ImageNet検出タスクに関する我々のアプローチを検証する。 YOLO9000は、200クラスのうち44クラスの検出データしか持たないにもかかわらず、ImageNet検出検証セットで19.7 mAPを取得します。 COCOにない156クラスでは、YOLO9000は16.0 mAPを獲得します。しかし、YOLOは200以上のクラスを検出できます。 9000以上の異なるオブジェクトカテゴリの検出を予測します。そして、それはまだリアルタイムで実行されます。
1.はじめに
汎用オブジェクトの検出は、高速かつ正確で、さまざまなオブジェクトを認識できる必要があります。ニューラルネットワークの導入以来、検出フレームワークはますます高速かつ正確になってきている。しかしながら、大部分の検出方法は依然として小さなオブジェクトの集合に制約されている。現在のオブジェクト検出データセットは、分類やタグ付けなどの他のタスクのデータセットに比べて制限されています。最も一般的な検出データセットには、数十から数百のタグを持つ数千から数十万の画像が含まれています[3] [10] [2]。分類データセットは、数十万または数十万のカテゴリを有する数百万の画像を有する[20] [2]。検出は、オブジェクト分類のレベルに合わせて行いたいと考えています。しかし、検出のための画像のラベル付けは、分類やタグ付けのためのラベル付けよりもはるかに高価です(タグは無料で提供されることが多い)。したがって、我々は、近い将来、分類データセットと同じスケールで検出データセットを見る可能性は低い。大量の分類データを活用して最新の検出システムの範囲を広げるための新しい方法を提案します。私たちの方法では、オブジェクト分類の階層ビューを使用して、別々のデータセットを組み合わせることができます。また、検出と分類の両方のデータに対して物体検出器を訓練することを可能にする共同訓練アルゴリズムを提案する。我々の方法は、分類された検出画像を利用して、分類イメージを使用してその語彙および堅牢性を高めながら、オブジェクトを正確にローカライズすることを学ぶ。この方法を使用して、9000種類以上の異なるオブジェクトカテゴリを検出できるリアルタイムのオブジェクト検出器であるYOLO9000をトレーニングします。まず、ベースYOLO検出システムを改良して、最先端のリアルタイム検出器YOLOv2を製造します。次に、データセットの組み合わせ方法と共同トレーニングアルゴリズムを使用して、ImageNetの9000を超えるクラスのモデルとCOCOの検出データを訓練します。当社のすべてのコードおよび事前訓練されたモデルは、オンラインで入手できます。
http://pjreddie.com/yolo9000/
2.より良く
YOLOは、最先端の検出システムに比べて様々な欠点がある。 Fast R-CNNと比較したYOLOのエラー分析は、YOLOがかなりの数の位置特定エラーを生成することを示しています。さらに、YOLOは、他の提案ベースの方法と比較して、リコール率が比較的低い。したがって、主に分類精度を維持しながら、リコールとローカリゼーションの改善に焦点を当てます。コンピュータビジョンは、一般に、より大きく、より深いネットワークに向かっている[6] [18] [17]。パフォーマンスの向上は、大規模なネットワークのトレーニングや複数のモデルの組み合わせによるヒントになることがよくあります。しかし、YOLOv2では、より高速な検出器が求められています。私たちのネットワークを拡大する代わりに、ネットワークを単純化し、その表現をより簡単に学ぶことができます。私たちはYOLOのパフォーマンスを向上させるために、独自の新しいコンセプトで過去の仕事からさまざまなアイデアを集めます。結果の要約を表2に示す。
バッチ標準化(Batch Normalization)
バッチの正規化は、他の形式の正規化の必要性を排除しながら、収束の大幅な改善につながります[7]。 YOLOのすべての畳み込みレイヤにバッチ正規化を追加することで、mAPで2%以上の改善が得られます。バッチの正規化は、モデルの規則化にも役立ちます。バッチ正規化を使用すると、オーバーフィットすることなくモデルからドロップアウトを削除できます。
高解像度分類器(High Resolution Classifier)
すべての最先端の検出方法は、ImageNetで事前訓練された分類器を使用する[16]。 AlexNetから始まるほとんどの分類器は、256×256 [8]より小さい入力画像で動作する。元のYOLOは分類器ネットワークを224×224で学習し、検出のために解像度を448に増加させる。これは、ネットワークが同時に学習オブジェクトの検出に切り替えて、新しい入力解像度に調整する必要があることを意味します。
YOLOv2の場合、最初に、ImageNet上の10エポックタイムの448×448フル解像度で分類ネットワークを微調整します。これにより、高解像度の入力でよりうまく動作するようにフィルタを調整するネットワーク時間が与えられます。その結果得られたネットワークを検出時に微調整します。この高分解能分類ネットワークは、ほぼ4%のmAPの増加をもたらします。
境界ボックスと畳み込み(Convolutional With Anchor Boxes)
YOLOは、畳み込み特徴抽出器の上に完全に接続された層を直接使用して、境界ボックス(Anchor box)の座標を予測する。直接座標を予測するのではなく、Fastter R-CNNは、手で選んだプリオを使用してバウンディングボックスを予測する[15]。 FAST R-CNNの領域提案ネットワーク(RPN)は、畳み込みレイヤのみを使用して、境界ボックス(Anchor box)のオフセットと信頼性を予測します。予測レイヤは畳み込みであるため、RPNは、特徴マップ内のすべての場所でこれらのオフセットを予測します。座標の代わりにオフセットを予測することで、問題が単純化され、ネットワークの学習が容易になります。 YOLOから完全に連結されたレイヤーを削除し、アンカーボックスを使用して境界ボックス(Anchor box)を予測します。まず、ネットワークの畳み込み層の出力をより高い解像度にするために、1つのプール層を削除します。 448×448ではなく、416枚の入力画像で動作するようにネットワークを縮小しています。これは、特徴マップに奇数の場所が必要なため、1つのセンターセルが存在するためです。オブジェクト、特に大きなオブジェクトはイメージの中心を占める傾向があります。そのため、近くにある4つの場所の代わりに、これらのオブジェクトを予測するために、中央に1つの場所を正しく配置するとよいでしょう。 YOLOの畳み込み層は、画像を32倍ダウンサンプリングするので、416の入力画像を使用することにより、13×13の出力特徴マップが得られる。
境界ボックス(Anchor box)に移動するとき、クラス予測メカニズムを空間位置から切り離し、代わりにすべての境界ボックス(Anchor box)のクラスとオブジェクト性を予測します。 YOLOに続いて、客観性予測は、依然として地上真理と提案されたボックスのIOUを予測し、クラス予測は、オブジェクトがあると仮定すると、そのクラスの条件付き確率を予測する。アンカーボックスを使用すると、精度が少し低下します。 YOLOは画像あたり98個のボックスしか予測しませんが、アンカーボックスを使用すると、私たちのモデルでは1000を超えると予測されます。アンカーボックスがなければ、中間モデルは69.5 mAPとなり、リコール率は81%です。アンカーボックスでは、モデルは69.2 mAP、回収率は88%です。 mAPが減少したにもかかわらず、リコールの増加は、モデルが改善すべき余地があることを意味します。
ディメンション-クラスタ(Dimension Clusters)
YOLOでアンカーボックスを使用する場合、2つの問題が発生します。 1つは、ボックスの寸法が手で選ばれたことです。ネットワークはボックスを適切に調整することを学ぶことができますが、ネットワークをより良く前もって選択すると、ネットワークが良好な検出を予測することを容易にすることができます。
私たちは手でプライヤーを選ぶのではなく、トレーニングセットのバウンディングボックスでk-meansクラスタリングを実行し、良いプリオリ(priors)を自動的に見つけます。ユークリッド距離の標準的なk平均を使うと、大きなボックスは小さなボックスよりも誤差が大きくなります。しかし、私たちが本当に望むのは、ボックスのサイズに依存しない良いIOUスコアにつながるプリオリ(priors)です。したがって、距離メトリックでは次のものを使用します。
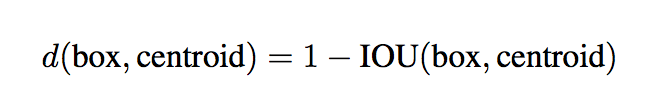
kのさまざまな値に対してk-meansを実行し、最も近い重心との平均IOUをプロットします(図2を参照)。
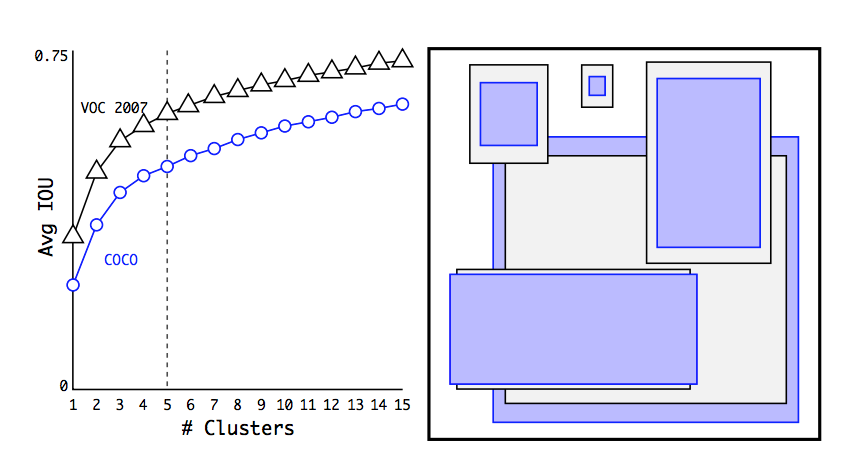
図2:VOCとCOCOのクラスタリング・ボックス・ディメンション 私たちのモデルでは、バウンディングボックスの次元をk-平均クラスタリングして、プライオリティを得ることができます。 左の画像は、kのさまざまな選択肢を持つ平均IOUweを示しています。 k = 5は、モデルの再現と複雑さのバランスをとることができます。 右側の画像は、VOCとCOCOの相対重心を示しています。 両方のプライオリティセットは薄くて高いボックスを好みますが、COCOはVOCよりも大きなバリエーションインサイトを持ちます。
モデルの複雑さと高いリコールの間の良いトレードオフとしてk = 5を選択します。クラスタ重心は、手で選択したアンカーボックスと大きく異なります。短くて幅の広いボックスと、背の高い、薄いボックスが少なくなります。クラスタリング戦略の最も前のものと表1の手作業で選んだアンカー・ボックスの平均値を比較します。わずか5つのプリオーバーで、重心は9つのアンカー・ボックスと同様に機能し、平均IOUは61.9で60.9です。 9セントロイドを使用すると、平均IOUがはるかに高いことがわかります。これは、k-meansを使用してバウンディングボックスを生成することにより、より良い表現でモデルが始まり、タスクをより簡単に学習できることを示しています。
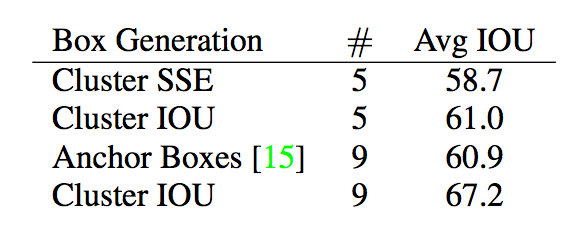 表1:VOC 2007における最寄りのプライオリティのボックスの平均IOU。
VOC 2007上のオブジェクトの平均IOUは、異なる世代の方法を使用する前に、それらの最も近い、変更されていないものです。 クラスタリングは、手で選んだプリオラーを使用するよりもはるかに優れた結果をもたらします。
表1:VOC 2007における最寄りのプライオリティのボックスの平均IOU。
VOC 2007上のオブジェクトの平均IOUは、異なる世代の方法を使用する前に、それらの最も近い、変更されていないものです。 クラスタリングは、手で選んだプリオラーを使用するよりもはるかに優れた結果をもたらします。
直接的な位置予測(Direct location prediction)
YOLOでアンカーボックスを使用すると、特に初期の反復中にモデルの不安定性という2つ目の問題が発生します。不安定性の大部分はボックスの(x、y)の位置を予測することから来ます。領域提案ネットワークでは、ネットワークは値txとtyを予測し、(x、y)中心座標は次のように計算されます。
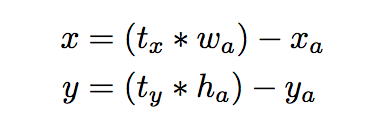
例えば、tx = 1の予測は、ボックスをアンカーボックスの幅だけ右にシフトし、tx = -1の予測は、同じ量だけ左にそれをシフトする。この定式化は拘束されないので、アンカーボックスは、どの位置がボックスを予測したかにかかわらず、画像の任意の点で終わる可能性があります。ランダム初期化では、モデルは、感知可能なオフセットを予測するために安定化するのに長い時間を要する。オフセットを予測する代わりに、我々はYOLOのアプローチに従い、グリッドセルの位置に対する位置座標を予測する。これは、地面の真理が0と1の間になるように制限されます。ネットワークの予測がこの範囲に収まるようにロジスティックアクティベーションを使用します。ネットワークは、出力特徴マップ内の各セルで5つのバウンディングボックスを予測する。ネットワークは、各境界ボックス(Anchor box)tx、ty、tw、th、toに5つの座標を予測します。セルが画像の左上隅から(cx、cy)だけオフセットされていて、先行する境界ボックス(Anchor box)が幅と高さpw、phを持つ場合、予測は次のように対応します。

我々は位置予測を制約するので、パラメータ化は学習がより容易であり、ネットワークをより安定にする。 バウンディングボックスの中心位置を直接予測するとともにディメンションクラスタを使用することで、YOLOがアンカーボックスのバージョンよりも約5%改善されます。
ファイン-グレイン特徴(Fine-Grained Features)
この変更されたYOLOは、13×13の特徴マップ上の検出を予測する。 これは大きなオブジェクトでは十分ですが、より細かいオブジェクトをローカライズするために細かい粒度の特徴が役立ちます。 より速いR-CNNおよびSSDは、ネットワーク内のさまざまな特徴マップで提案ネットワークを実行し、さまざまな解決策を得る。 以前のレイヤーの機能を26×26の解像度で実現するパススルーレイヤーを追加するだけで、別のアプローチをとっています。
パススルー層は、ResNetのアイデンティティマッピングと同様に、隣接する特徴を空間的位置ではなく異なるチャネルに積み重ねることにより、より高い解像度の特徴と低解像度特徴とを連結する。26×26×512特徴マップを13×13×2048特徴マップに変換します。これは元の特徴と連結できます。 私たちの検出器は、拡張された特徴マップの上で実行されるので、きめ細かな機能にアクセスできます。 これは、わずか1%のパフォーマンス向上をもたらします。
 図3:ディメンション・プリウスと位置予測を含む境界ボックス。 箱の重心からのオフセットとしてボックスの幅と高さを予測します。 シグモイド関数を使用して、フィルタアプリケーションの位置に対するボックスの中心座標を予測します。
図3:ディメンション・プリウスと位置予測を含む境界ボックス。 箱の重心からのオフセットとしてボックスの幅と高さを予測します。 シグモイド関数を使用して、フィルタアプリケーションの位置に対するボックスの中心座標を予測します。
マルチスケールトレーニング(Multi-Scale Training)
オリジナルのYOLOは、448×448の入力解像度を使用します。アンカーボックスを追加すると、解像度が416×416に変更されました。しかし、我々のモデルは畳み込みレイヤーとプールレイヤーを使用するだけなので、オンザフライでサイズ変更することができます。私たちはYOLOv2をさまざまなサイズのイメージを実行するために頑強にして、モデルに訓練するようにします。入力イメージのサイズを固定する代わりに、ネットワークの変更はほとんどありません。私たちのネットワークは、10次元のバッチごとに、新しい画像寸法サイズを無作為に選んでいます。私たちのモデルは32の係数でダウンサンプルしているので、32の倍数{320、352、...、608}から引き出します。したがって、最も小さいオプションは320×320で、最大は608×608です。ネットワークをその次元にリサイズしてトレーニングを続けます。この体制により、ネットワークは様々な入力次元を十分に予測することを学びます。これは、サムネットワークが異なる解像度で検出を予測できることを意味します。ネットワークはより小さいサイズでより高速に動作するので、YOLOv2は速度と精度との間の妥協点を提供します。低解像度では、YOLOv2は安価で、かなり正確な検出器として動作します。 288×288では、Fast R-CNNとほぼ同じくらいmAPで90 FPS以上で動作します。これは、より小さいGPU、高いフレームレートのビデオ、または複数のビデオストリームに適しています。高解像度のYOLOv2は、VOC 2007で78.6 mAPの最先端の検出器であり、それでもリアルタイムスピードを上回っています。 VOC 2007のYOLOv2と他のフレームワークの比較については、表3を参照してください。図4
 図4:VOC 2007の精度とスピード
図4:VOC 2007の精度とスピード
さらなる実験(Further Experiments)
表4は、YOLOv2と他の最先端の検出システムとの比較性能を示しています。
YOLOv2は競合する方法よりもはるかに高速に動作しながら73.4 mAPを達成します。 また、COCOを訓練し、表5の他の方法と比較します。VOCメトリック(IOU = .5)では、YOLOv2はSSDとFaster R-CNNに匹敵する44.0 mAPになります。
より早く
検出が正確であることを望みますが、私たちはそれがより速くなることを望みます。 ロボティクスやセルフドライブカーのような検出のためのほとんどのアプリケーションは、低遅延予測に依存しています。 性能を低下させるために、我々はYOLOv2を地上から高速に設計する。多くの検出フレームワークは、基底抽出器としてVGG-16に依存している[17]。 VGG-16は強力で正確な分類ネットワークですが、それは不必要に複雑です。 VGG-16の畳み込みレイヤーは、224×224の解像度で1つの画像に対して1回のパスで30.69億の浮動小数点演算を必要とします.YOLOフレームワークは、Googlenetアーキテクチャ[19]に基づいたカスタムネットワークを使用します。 このネットワークは、VGG-16よりも高速で、フォワードパスに852億回の操作しか使用していません。 しかし、精度はVGG-16よりもわずかに悪いです。 単一作物のトップ5精度224×224の場合、YOLOのカスタムモデルは88.0%のImageNet、VGG-16の90.0%のImageNetが得られます。
ダークネット-19
YOLOv2の基盤として用いられる新しい分類モデルを提案する。 私たちのモデルは、ネットワーク設計とその分野における一般的な知識についての先駆的な仕事から成り立っています。 VGGモデルと同様に、我々は大部分3×3のフィルタを使用し、永久脱着ステップ[17]の後にチャネルの数を2倍にする。 Network inNetwork(NIN)の作業に続いて、グローバル平均プーリングを使用して予測を行い、1×1フィルタを使用して3×3コンボリューション間のフィーチャ表現を圧縮します[9]。 ダークネット19と呼ばれる最終モデルは、19の畳み込みレイヤーと5つのマックスプールレイヤーを持っています。[7]訓練を安定化し、収束を加速し、モデルを正規化するために、 完全な説明については、表6を参照してください。ダークネット-19は、画像を処理するのに55.8億の操作しか必要とせず、ImageNet上で72.9%の精度を達成し、91.2%の精度を達成します。
分類のためのトレーニング。
我々は、Darknetニューラルネットワークフレームワークを使用して、開始学習率0.1、多項式減衰率4、重み減衰0.0005およびモメンタム0.9の確率的勾配降下を使用して、160個のエポックの標準ImageNet 1000クラス分類データセットでネットワークを訓練する [13]。
訓練中はランダムクロップ、回転、色相、彩度、露出シフトなどの標準的なデータ補強トリックを使用します。上記で説明したように、画像224×224の最初の訓練の後、我々はネットワークをより大きなサイズ448で微調整します。私たちは上記のパラメータで訓練しますが、10エポックと10-3の学習率で開始します。この高解像度で私たちのネットワークは76.5%のトップ1精度と93.3%のトップ5精度を達成しています。
検出のためのトレーニング。
最後の畳み込みレイヤーを削除し、1024個のフィルターセッションを持つ3つの3×3畳み込みレイヤーと、検出に必要な数の出力を持つ最後の1×1畳み込みレイヤーを追加して検出するために、このネットワークを変更します。 VOCの場合、それぞれ5つの座標と20クラスのペイボックスを持つ5つのボックスを予測し、125のフィルタを使用します。最後に、3×3×512レイヤーから2番目のレイヤーまでのパススルーレイヤーを追加して、レイヤーレイヤーを細かいグレインフィーチャーを使用できるようにします。レイヤーを10-3で始まる160エポックに訓練します。我々は0.0005の重み減衰と0.9のモメンタムを使用する。我々は、YOLOとSSDと同様のデータ増強を無作為の作物、色シフトなどに使用する。我々はCOCOとVOCで同じトレーニング戦略を使用する。
 表2:YOLOからYOLOv2へのパス。 上に挙げた設計上の決定のほとんどは、mAPの大幅な増加につながります。 2つの例外は、アンカーボックスを備えた完全な畳み込みネットワークへの切り替えと新しいネットワークの使用です。 アンカーボックススタイルのアプローチに切り替えると、mAPを変更することなくリコールが増加し、新しいネットワークカット計算を33%使用しました。
表2:YOLOからYOLOv2へのパス。 上に挙げた設計上の決定のほとんどは、mAPの大幅な増加につながります。 2つの例外は、アンカーボックスを備えた完全な畳み込みネットワークへの切り替えと新しいネットワークの使用です。 アンカーボックススタイルのアプローチに切り替えると、mAPを変更することなくリコールが増加し、新しいネットワークカット計算を33%使用しました。
 表3:PASCAL VOC 2007の検出フレームワーク。
YOLOv2は従来の検出方法よりも高速で正確です。 速度と精度のトレードオフを容易にするために、異なる解像度で実行することもできます。 各YOLOv2エントリは、実際には、同じ重みを持つ同じ訓練モデルであり、ちょうど異なるサイズで評価されます。 すべてのタイミング情報は、Geforce GTX Titan X(Pascalモデルではないオリジナル)上にあります。
表3:PASCAL VOC 2007の検出フレームワーク。
YOLOv2は従来の検出方法よりも高速で正確です。 速度と精度のトレードオフを容易にするために、異なる解像度で実行することもできます。 各YOLOv2エントリは、実際には、同じ重みを持つ同じ訓練モデルであり、ちょうど異なるサイズで評価されます。 すべてのタイミング情報は、Geforce GTX Titan X(Pascalモデルではないオリジナル)上にあります。
より強く
 表4:PASCAL VOC2012テスト検出結果 YOLOv2は、ResNetとSSD512を搭載したFaster R-CNNのような最先端の検出器と同等の性能を発揮し、2〜10倍高速です。
表4:PASCAL VOC2012テスト検出結果 YOLOv2は、ResNetとSSD512を搭載したFaster R-CNNのような最先端の検出器と同等の性能を発揮し、2〜10倍高速です。
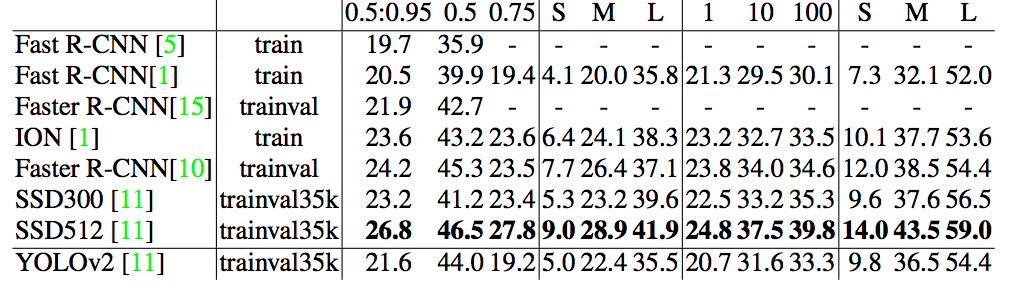 表5:COCOテストの結果 - dev2015。 [11]から適応された表。
表5:COCOテストの結果 - dev2015。 [11]から適応された表。
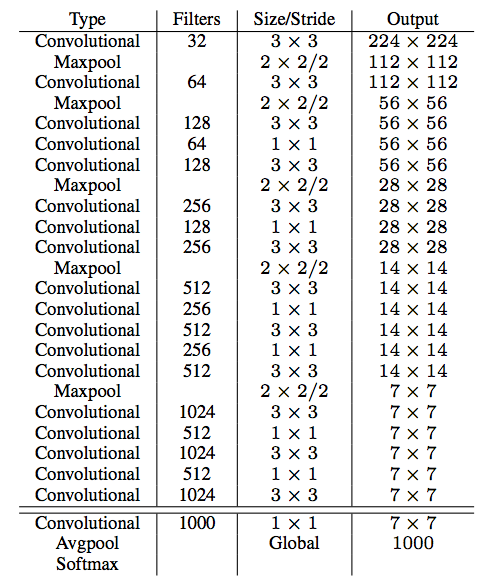 表6:ダークネット-19。
表6:ダークネット-19。
分類と検出データの共同訓練の仕組みを提案する。我々の方法は、検出のためのラベル付けされた画像を使用して、検出に特有の情報、例えば、共通のオブジェクトを分類する方法と同様に、バウンディングボックスの座標予測およびオブジェクト性を学習する。クラスラベルだけの画像を使用して、検出するカテゴリの数を拡張します。
トレーニングでは、検出と分類の両方のデータセットから画像を合成します。
1.私たちのネットワークが検出のために想像線で表示されるのを見ると、完全なYOLOv2損失関数に基づいて逆伝播することができます。
2.分類イメージが表示されると、アーキテクチャの分類固有の部分からの損失のみを逆伝播します。
このアプローチにはいくつかの課題があります。検出データセットには、共通のオブジェクトと一般的なラベル(「dog」や「boat」など)しかありません。分類データセットは、ラベルの幅がより広く、より深い範囲にあります。 ImageNetには、 "Norfolk terrier"、 "Yorkshireterrier"、 "Bedlington terrier"など、数百種類以上の犬がいます。 2つのデータセットを訓練したい場合は、これらのラベルをマージする一貫した方法が必要です。分類のための多くのアプローチでは、可能なすべてのカテゴリに渡ってsoftmaxレイヤを使用して、最終的な確率分布を計算します。 softmaxを使用すると、クラスは相互に排他的です。これは、データセットを結合するための問題を提起します。例えば、 "Norfolk terrier"と "dog"というクラスは互いに排他的ではないため、このモデルを使用してImageNetとCOCOを組み合わせることは望ましくありません。代わりに、相互排除を仮定する。このアプローチでは、データについて知っているすべての構造が無視されます。たとえば、すべてのCOCOクラスは互いに排他的です。
階層的分類
ImageNetラベルは、概念を構成する言語データベースであるWordNetから引き出され、どのように関係しているか[12]。 WordNetでは、 "ノーフォークテリア"と "ヨークシャーテリア"は両方とも、 "犬"の一種である "狩猟犬"のタイプである "テリア"の下位語であり、しかし、データセットを結合するためのラベルにはフラットな構造があります。構造はまさに私たちが必要とするものです.WordNetは木ではなく有向グラフとして構成され、言語は複雑です。例えば、「犬」は、「イヌ」型と「家畜」型の両方であり、どちらもWordNetのsynsetである。完全なグラフ構造を使用するのではなく、ImageNetの概念から階層ツリーを構築することで問題を簡略化します。このツリーを構築するために、ImageNetの視覚名詞を調べ、WordNetグラフからルートノード、 "多くのsynsetは、グラフの中に1つのパスしか持っていないので、最初にすべてのパスをツリーに追加します。次に、我々が残した概念を繰り返し検査し、できるだけツリーを成長させる経路を追加する。コンセプトに2つのルートがあり、1つのパスが3つのエッジをツリーに追加し、もう1つのエッジが1つしか追加しない場合は、より短いパスを選択します。最終結果は、視覚的概念の階層モデルであるWordTreeです。 WordTreeで分類を実行するためには、synsetを与えられたそのsynsetの各下位の確率について、各ノードで条件付き確率を予測する。例えば、「テリア」ノードにおいて、我々は予測する:

特定のノードの絶対確率を計算したい場合は、ルートノードまでのツリーのパスに従い、条件付き確率に掛けます。 だから、絵がノーフォーク・テリアであるかどうかを知りたければ、私たちは次のように計算します。

この目的を達成するために、ImageNetは1000クラスのImageNetを使用して構築されたWordTreeのDarknet-19モデルを訓練します。 buildWordTree1kには、ラベルスペースを1000から1369に拡張するすべての中間ノードが追加されています。トレーニング中に、ツリーの上にグラウンドトゥルーラベルが広がり、画像に「ノーフォークテリア」というラベルが付けられていれば、 "哺乳動物"など。条件付き確率を計算するために、我々のモデルは1369値のベクトルを予測し、同じ概念の下位であるすべてのsysnsetsに対してsoftmaxを計算する。図5を参照。前と同じトレーニングパラメータを使用して、hierarchicalDarknet- %top-1精度と90.4%top-5精度です。 369の追加コンセプトが追加されたにもかかわらず、私たちのネットワークがツリー構造を予測すると、正確性はわずかに低下します。この方法で分類を実行することはまた、いくつかの利点を有する。新規または未知のオブジェクトカテゴリでは、パフォーマンスが著しく低下します。例えば、ネットワークが犬の絵を見ているがそれがどんなタイプの犬であるか不明である場合、それは依然として高い信頼度を有する「犬」を予測するが、より低い信頼度をその下位句の間に広げている。さて、すべての画像に物体があると仮定するのではなく、我々はP r(物理物体)の値を与えるためにYOLOv2の物体の予測子を使用する。検出器はバウンディングボックスと確率木を予測します。ツリーをたどって、すべての分割で最も高い信頼度のパスを取得し、そのしきい値に達するとオブジェクトクラスを予測します。
WordTreeとのデータセットの組み合わせ
WordTreeを使用すると、複数のデータセットを合理的な方法で組み合わせることができます。ツリー内のsynsetにあるデータセットのカテゴリをマップするだけです。図6は、ImageNetとCOCOのラベルを組み合わせるためのWordTreeの使用例を示しています.WordNetは非常に多様なので、ほとんどのデータセットでこの技術を使用できます。
共同分類と検出。
WordTreeを使用してデータセットを結合できるようになったので、分類モデルと検出モデルを組み合わせてトレーニングすることができます。非常に大規模な検出器を訓練したいので、COCO検出データセットと完全なImageNetリリースのトップクラス9000クラスを使用して、組み合わせたデータセットを作成します。私たちはメソッドを評価するために同意しました。ImageNetの検出チャレンジから、まだ含まれていないクラスを追加しました。このデータセットの対応するWordTreeには9418のクラスがあります。 ImageNetははるかに大きなデータセットですので、ImageNetは4:1の倍率になるようにCOCOをオーバーサンプリングしてデータセットを分散します。このデータセットを使用して、YOLO9000を訓練します。基本的なYOLOv2アーキテクチャを使用しますが、出力サイズを制限するために5ではなく3つのプリオリを使用します。私たちのネットワークが検出画像を見ると、通常のようにバックプロパゲーションによる損失が発生します。分類喪失の場合、ラベルの対応するレベル以上で損失をバックプロパゲーションします。たとえば、ラベルが「犬」の場合、「GermanShepherd」と「Golden Retriever」の2つの予測には、その情報が含まれていないため、さらに下の予測にエラーが割り当てられます。
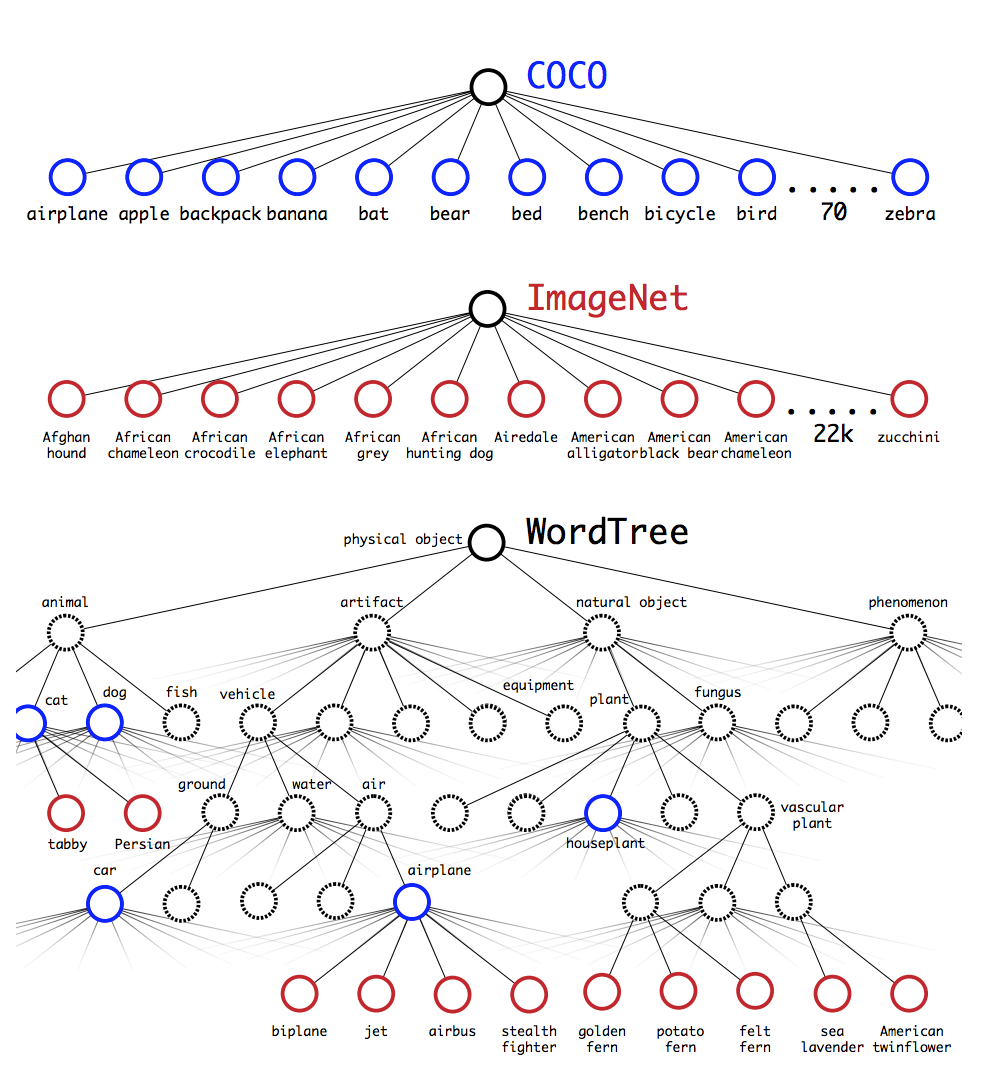 図6:WordTree階層を使ったデータセットの結合 WordNetの概念グラフを使用して、視覚的な概念の階層ツリーを構築します。 次に、データセットのクラスをツリーのsynsetにマッピングすることによって、データセットを結合することができます。 これは、説明の目的でWordTreeを単純化したものです。
図6:WordTree階層を使ったデータセットの結合 WordNetの概念グラフを使用して、視覚的な概念の階層ツリーを構築します。 次に、データセットのクラスをツリーのsynsetにマッピングすることによって、データセットを結合することができます。 これは、説明の目的でWordTreeを単純化したものです。
分類画像が見えるときは、分類の損失のみを逆伝播する。これを行うには、そのクラスの最高確率を予測するバウンディングボックスを見つけて、その予測木だけで損失を計算します。また、推定されたボックスが地上真理値ラベルと少なくとも0.3UのIOUだけオーバーラップしていると想定し、この仮定に基づいてオブジェクトの損失をバックプロパゲーションします。この共同トレーニングを使用して、COCOの検出データとitlearnsを使用して、 ImageNetのデータを使用してこれらのオブジェクトの幅広い種類を検出します。ImageNetの検出タスクでYOLO9000を評価します.YOLO9000には検出データではなくテスト画像の大半の分類データのみが含まれています。 YOLO9000は、ラベルの付いた検出データがないと分かっている、互いに素な156個のオブジェクトクラスに対して、19.7 mAP全体で16.0 mAPを取得します。このmAPはDPMによって達成された結果よりも高いが、YOLO9000は部分的な監督だけで異なるデータセットで訓練される[4]。また、同時に9000の他のオブジェクトカテゴリをリアルタイムで検出します。ImageNetweでYOLO9000のパフォーマンスを分析すると、動物の新しい種をよく知ることができますが、衣類や装備などの学習カテゴリでは苦労します。オブジェクトの予測は一般的にココの動物。逆に、COCOにはあらゆるタイプの衣類のための境界ボックスラベルがありません。そのため、YOLO9000は「サングラス」や「スイミングトランク」などのトモデルカテゴリに苦労しています。
 表7:YOLO9000 ImageNetのベストクラスとワーストクラス。
156人弱の監督してるクラスの中から、最も高いAPと最も低いAPを持つクラス。 YOLO9000は様々な動物の良いモデルを学習しますが、衣類や装備のような新しいクラスでは苦労します。
表7:YOLO9000 ImageNetのベストクラスとワーストクラス。
156人弱の監督してるクラスの中から、最も高いAPと最も低いAPを持つクラス。 YOLO9000は様々な動物の良いモデルを学習しますが、衣類や装備のような新しいクラスでは苦労します。
5。結論
リアルタイム検出システムであるYOLOv2とYOLO9000を紹介します。 YOLOv2は、さまざまな検出データセットにわたる最先端かつ高速な検出システムです。さらに、速度と精度のトレードオフを滑らかにするために、さまざまな画像処理を実行できます.YOLO9000は、検出と分類を共同して最適化することにより、9000種類以上のオブジェクトを検出するためのリアルタイムフレームワークです。 WordTreeを使用して、さまざまなソースからのデータと共同最適化技術を組み合わせて、ImageNetとCOCOを同時に連携させます。 YOLO9000は、検出と分類の間のデータセットサイズのギャップを閉じるための激しい一歩です。私たちの技術の多くは、オブジェクト検出の外で一般化します。ImageNetのWordTree表現は、画像分類のためのより詳細な、より詳細な出力空間を提供します。マルチスケールのトレーニングのような技術は、様々な視覚的なタスクにわたって利点を提供する可能性があります。将来の仕事のために、我々は、よく分化されたイメージセグメンテーションのための同様の技術を使用することを望みます。また、弱いラベルを分類データ管理訓練に割り当てるためのより強力な一致戦略を使用して、検出結果を改善する予定です。コンピュータビジョンは膨大な量のラベル付きデータに恵まれています。私たちは、ビジュアルワールドのより強力なモデルを作るために、さまざまな情報源と構造のデータを一緒に持って来る方法を探し続けていきます。
参考