本記事について
本記事著者が開発した3色鬼ごっこゲームにおける、ML-Agentsを利用したプレイヤーのAIの作成方法について紹介する記事となります。
本記事の作成目的
- 知識共有
- ML-Agentsを利用した3色鬼ごっこゲーム用のAIの開発方法に関する知識を共有します。
- 自己学習の一環
- 本知識の公開を通じて、著者がその知識を定着させます。
対象読者
- ゲーム開発者や機械学習に興味がある人
本ゲームについて
赤・青・緑の3体のプレイヤーで行う3色鬼ごっこゲームとなります。
具体的には、赤・青・緑には力関係があり、力の弱いプレイヤーが強いプレイヤーから逃げて、強いプレイヤーは弱いプレイヤーを追いかけるゲームとなります。
赤・青・緑の力関係はじゃんけんのような関係にあり、赤 > 青 > 緑 > 赤となります。
ゲームモードには、プレイヤーを全てAIが操作する観戦モード、青を人間、赤と緑をAIが操作するプレイモードの2種類が存在します。
ゲームの面白さとしては、追いかけながら追われるという三つ巴の複雑な状況下で最適な判断を素早く行う必要がある点にあると考えています。
本ゲームは以下のリンクからプレイ可能です。
https://unityroom.com/games/threetaggame
開発環境
- Unity
- Unity 2021.3.15f1
- ML-Agents
- ML-Agents Release 20
- Python
- Python 3.8.16
学習環境
| エージェント | |
|---|---|
| 1 | 赤プレイヤー |
| 2 | 青プレイヤー |
| 3 | 緑プレイヤー |
| 各エージェントが選択できる行動 | |
|---|---|
| 1 | 前進 |
| 2 | 右回転 |
| 3 | 左回転 |
| 報酬を与えるエージェント | 与える報酬(値) | 報酬を与えるタイミング | 報酬を与える根拠 | |
|---|---|---|---|---|
| 1 | 子を捕まえたエージェント | +1 | 捕まえた直後から次の行動を取るまでの間 | 捕まえることを学習させるため |
| 2 | 鬼に捕まったエージェント | -1 | 捕まった直後から次の行動を取るまでの間 | 捕まらないようにすることを学習させるため |
| 各エージェントの観測データ | |
|---|---|
| 1 | 全てのエージェントの位置情報 |
| 2 | 全てのエージェントの進行方向情報 |
| 3 | 壁までの距離情報 |
| 各エージェントのエピソード終了条件 | |
|---|---|
| 1 | 鬼に捕まる |
| 2 | 子を捕まえる |
| 3 | 1000ステップ数経過 |
| 各エージェントのエピソード開始時に行う処理 | |
|---|---|
| 1 | 自分自身を他のエージェントと一定距離を空けたランダムな位置に再配置 |
| 2 | 自分自身をステージ中央付近を向くように設定 |
| 使用学習アルゴリズムや手法 | |
|---|---|
| 1 | POCA |
| 2 | Self-Play |
実装
エージェント関係の独自スクリプト
//青エージェント
public class AgentBlue : AgentBase
{
public override void CollectObservations(VectorSensor sensor){
sensor.AddObservation(transform.localPosition);
sensor.AddObservation(transform.forward);
sensor.AddObservation(otherAgents[0].transform.localPosition);
sensor.AddObservation(otherAgents[0].transform.forward);
sensor.AddObservation(otherAgents[1].transform.localPosition);
sensor.AddObservation(otherAgents[1].transform.forward);
}
public void MoveAgent(ActionSegment<int> act) {
var rotateDir = Vector3.zero;
var rotateAxis = act[0];
switch (rotateAxis) {
case 1:
rotateDir = transform.up * -1f;
break;
case 2:
rotateDir = transform.up * 1f;
break;
}
transform.Rotate(rotateDir, Time.deltaTime * 100f * angularVelocityCoefficient);
selfRidigBody.velocity = Vector3.zero;
selfRidigBody.AddForce(transform.forward * .1f * velocityCoefficient);
}
public override void OnActionReceived(ActionBuffers actionBuffers)
{
MoveAgent(actionBuffers.DiscreteActions);
if(hasTouchedChild){
SetReward(1f);
EndEpisode();
}
if(hasTouchedDemon){
SetReward(-1f);
EndEpisode();
}
}
void OnCollisionEnter(Collision other){
if(other.gameObject.CompareTag("AgentGreen")){
hasTouchedChild = true;
}
if(other.gameObject.CompareTag("AgentRed")){
hasTouchedDemon = true;
}
}
public override void Heuristic(in ActionBuffers actionsOut) {
var discreteActionsOut = actionsOut.DiscreteActions;
discreteActionsOut.Clear();
if (Input.GetKey(KeyCode.A)) {
discreteActionsOut[0] = 1;
}
if (Input.GetKey(KeyCode.D)) {
discreteActionsOut[0] = 2;
}
}
}
- 青エージェント用のクラスとなります。
-
CollectObservationsメソッド:
- 自身が観測する環境情報を定義します。
- 現在の自身の位置(
transform.localPosition)と前方向(transform.forward)を観測させます。 - また、他の2つのエージェント(赤と緑)の位置と前方向も観測として追加しています。
-
MoveAgentメソッド:
- 自身の移動を制御します。
- 具体的には、回転と前進を行います。
- まず、
act[0]の値に基づいて、回転を行います。-
act[0]の値が0の場合は回転しません。 -
act[0]の値が1の場合は左回転します。 -
act[0]の値が2の場合は右回転します。
-
- 回転後は、現在の進行方向に力を加えることで、前進(等速)します。
- 力を加える前に現在のvelocityをVector3.zeroにリセットします。
- リセット後に毎回同一の大きさの力を加えることで、等速移動を行うようになります。
-
OnActionReceivedメソッド:
- 自身が新しい行動を取る度に呼ばれるもので、移動や報酬付与、エピソードの終了を実行します。
- まず、
MoveAgentメソッドを呼び出して自身を移動させます。 - 自身が"子"に触れた場合(
hasTouchedChildがtrue)、報酬として1.0を与え、エピソードを終了します。 - 自身が"鬼"に触れた場合(
hasTouchedDemonがtrue)、報酬として-1.0を与え、エピソードを終了します。 - エピソード終了後は、後述のOnEpisodeBegin()が呼び出され、自身がランダムな位置に再配置されます。
-
OnCollisionEnterメソッド:
- 別のエージェントと衝突したときに呼び出されます。
- 緑色のエージェント(AgentGreen)に衝突した場合、
hasTouchedChildフラグを真に設定します。 - 赤色のエージェント(AgentRed)と衝突した場合、
hasTouchedDemonフラグを真に設定します。
-
Heuristicメソッド:
- 人間が手動で青エージェントを操作するためのものです。
- デバッグ時や人間が手動で青を操作するプレイモードで使用します。
- "A"キーが押されている場合、青は左に回転するための行動を取るように設定され、"D"キーが押されている場合、青は右に回転する行動を取るように設定されます。
//赤エージェント
//AgentBlueと同様のメソッドとメンバー変数を持ちます
public class AgentRed : AgentBase
{
//(省略)
}
- 赤エージェント用のクラスとなります。
- AgentBlueと同等のため省略しています。
//緑エージェント
//AgentBlueと同様のメソッドとメンバー変数を持ちます
public class AgentGreen : AgentBase
{
//(省略)
}
- 緑エージェント用のクラスとなります。
- AgentBlueと同等のため省略しています。
//AgentBlue, AgentRed, AgentGreenの基底クラス
public class AgentBase : Agent
{
[SerializeField]
protected float angularVelocityCoefficient = 1f; //自身の角速度
[SerializeField]
protected float velocityCoefficient = 1f; //自身の速度
public Transform stage; //エージェントが移動する平面のステージ
[SerializeField]
protected List<Transform> otherAgents; //自身以外のエージェント
[SerializeField]
protected Rigidbody selfRidigBody; //自身のRigidbody
[SerializeField]
float top = 12f; //自身の開始位置のz座標の最大値
[SerializeField]
float right = 12f; //自身の開始位置のx座標の最大値
[SerializeField]
float bottom = -12f; //自身の開始位置のz座標の最小値
[SerializeField]
float left = -12f; //自身の開始位置のx座標の最小値
[SerializeField]
float minDistanceBetweenOtherAgentsAtStart = 5f; //自身と他のエージェントとの間の開始位置の最小距離
protected bool hasTouchedDemon = false; //自身の鬼に捕まった?
protected bool hasTouchedChild = false; //自身の子を捕まえた?
//他エージェントと一定距離離れたステージ上のランダムな位置を取得します
protected Vector3 GetStartPosition(List<Transform> _otherAgents, Transform _stage){
var pos = new Vector3();
var stagePos = _stage.position;
while(true){
var hasDetect = true;
pos = stagePos + new Vector3(Random.Range(left, right), 0.5f, Random.Range(bottom, top));
foreach(var tr in _otherAgents){
if((tr.position - pos).sqrMagnitude < minDistanceBetweenOtherAgentsAtStart){
hasDetect = false;
break;
}
}
if(hasDetect){
break;
}
}
return pos;
}
//ステージ中央付近のランダムな位置を取得します
protected Vector3 GetLookAtTargetPositionAtStart(Transform _stage){
var dx = Random.Range(-3f, 3f);
var dz = Random.Range(-3f, 3f);
var pos = new Vector3(_stage.position.x + dx, 0.5f, _stage.position.z + dz);
return pos;
}
public override void OnEpisodeBegin(){
hasTouchedChild = false;
hasTouchedDemon = false;
transform.position = GetStartPosition(otherAgents, stage);
var pos = GetLookAtTargetPositionAtStart(stage);
transform.LookAt(pos);
}
}
- AgentBlue, AgentRed, AgentGreenの基底クラスとなります。
-
変数:
-
angularVelocityCoefficient, velocityCoefficient- 自身の角速度と速度の係数となります。
-
stage- エージェントが移動する平面のステージを示すTransformオブジェクトです。
-
otherAgents- 他のエージェントのリストとなります。
-
selfRidigBody- 自身のRigidbodyオブジェクトです。
-
top,bottom,right,left- 自身の開始位置の範囲を指します。
- topはz座標の最大値、bottomはz座標の最小値、rightはx座標の最大値、leftはx座標の最小値を表します。
- ステージを真上から見た場合に、ステージの範囲に収まり、かつステージの範囲より若干小さい範囲になるように値を設定しました。
-
minDistanceBetweenOtherAgentsAtStart- 自身と他のエージェントとの間の開始位置における最小距離であり、距離の2乗の値となります。
- 他エージェントと接触しないような小さい距離に設定しました。
-
hasTouchedDemon, hasTouchedChild- 自身が鬼または子に接触したかどうかを示すブール変数です。
-
-
GetStartPositionメソッド:- 自身のエピソードの開始時の場所を取得します。
- 他のエージェントから一定の距離を保つ位置をランダムに選択します。
- top, bottom, right, leftの範囲内のステージ上のランダムな位置を選び、仮の自身の位置とします。この仮の位置と他のエージェントの位置との距離のうち、 minDistanceBetweenOtherAgentsAtStart未満であるものが存在する場合は、仮の位置の選択をやり直し、存在しなければ、仮の位置を正式な自身の位置とします。
-
GetLookAtTargetPositionAtStartメソッド:- 自身がエピソードの開始時に向いている方向を決定するための位置を返します。
- その位置をエージェントが向くようになります。
- ステージ中央付近のランダムな位置が選択されます。
-
OnEpisodeBeginメソッド:- 新しいエピソードが開始されるたびに呼び出されるメソッドです。
- エージェントの位置や向きをリセットし、他の関連する変数もリセットします。
Ray Peception Sensor 3D

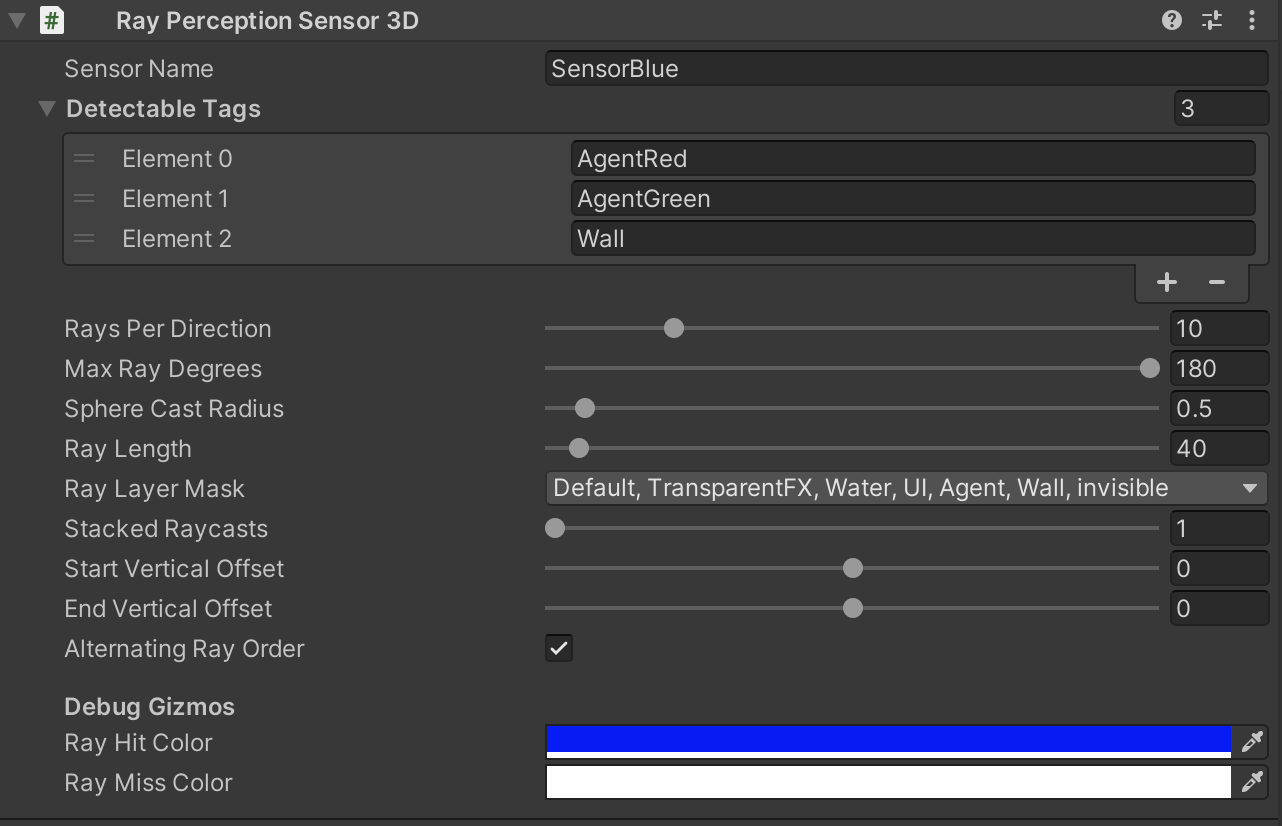
- 青エージェントにアタッチしたRay Perception Sensor 3Dのインスペクターの画像となります。
- Ray Perception Sensor 3Dは自身からレイを発射して、DetectableTagsで指定されたタグを持つ障害物にあたった場合の情報(自身と障害物との距離など)を自身に伝達します。
- このレイで取得された情報は、前述のCollectObservations()の中で指定しなくても、自身に自動的に伝達されます。
- タグとして他エージェントと壁を指定しています。
- 自身と他エージェントまでの距離、および自身と壁までの距離を伝達することが目的です。
- 自身と他エージェント間の距離の伝達は、以下の理由で、もしかしたら不要かもしれません。
- 前述のCollectObservations()の中で、自身も含めた全てのエージェントの位置情報を自身に伝達しています。
- 自身の位置と他エージェントの位置がわかれば、その間の距離もわかります。
- 他エージェントにも同様にRay Perception Sensor 3Dをアタッチしています。
Behavior Parameters
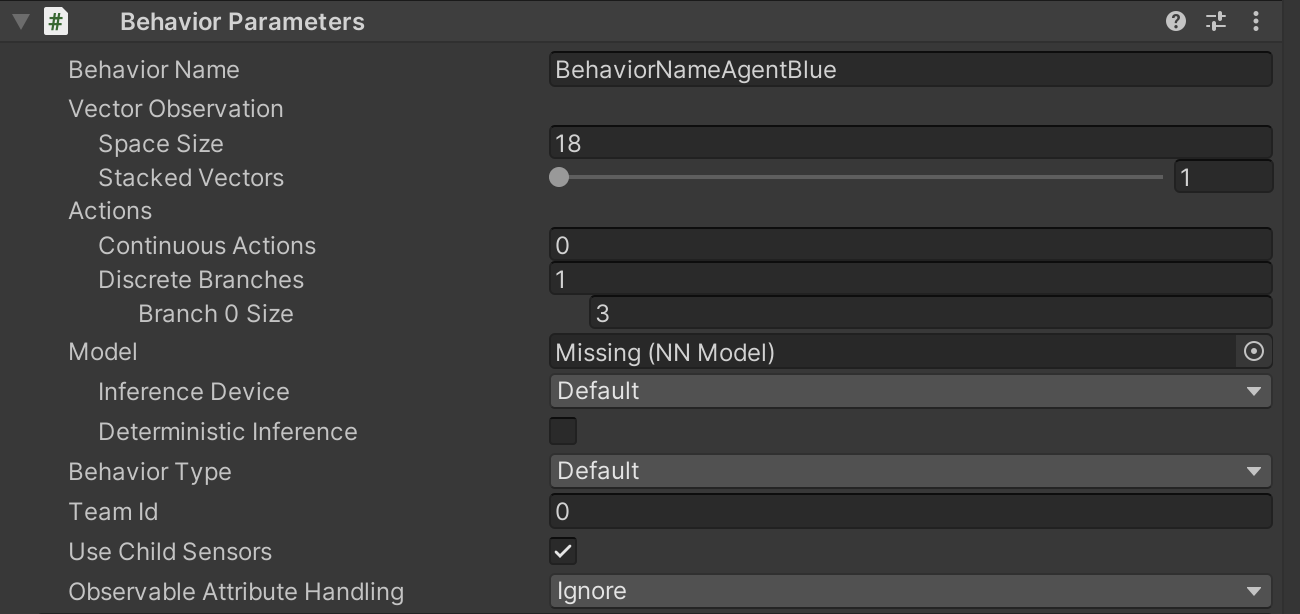
- 青エージェントにアタッチしたBehavior Parametersのインスペクターの画像となります。
- Behavior Parametersはエージェントの名称や観測データの数、行動の数、使用学習モデルなどを指定します。
-
Behavior Name
- このエージェントの名称です。
- BehaviorNameAgentBlueとしました。
-
Vector Observation
-
Space Size
- CollectObservations()内で定義した観測データの数です。
- 座標などのVector3形式のデータはSpace Sizeが3と考えます。
- CollectObservations()内で6つのVector3データを定義しているため、Space Sizeは18となります。
- 前述のRay Peception Sensor 3Dで観測するデータ用のSpace Sizeは必要ありません。
-
Space Size
-
Actions
-
Continuous Actions
- エージェントが選択する行動に対応する実数値を格納する配列のサイズを指定します。
- 配列のサイズはエージェントが取ることができる行動のカテゴリ数を表します。
- 例えば、エージェントが右手に力$F_1$($F_1$は実数)を加える行動と、左手に力$F_2$($F_2$も実数)を加える行動の2カテゴリの行動を選択できる場合、サイズは2となります。
- 異なるカテゴリの行動は同時に取ることができます。
- 例えば、上記の例の場合、右手と左手に同時に力を加える行動を取ることができます。
- しかし、右手に異なる2つの力を同時に加えることはできません。
- エージェントが選択できる行動数が無数に存在する場合に使用します。
- 例えば、エージェントが右手に力$F_1$を加えるカテゴリの行動を取る場合、$F_1$の実数値によって取ることができる行動の数は無数に存在します。
- 今回は使用しないため、0としました。
-
Discrete Branches
- エージェントが選択する行動に対応する整数値を格納する配列のサイズを指定します。
- Continuous Actionsと同様に、配列のサイズはエージェントが取ることができる行動のカテゴリ数を表します。
- 例えば、エージェントに右回転、左回転、前進(無回転)のどれかの行動をとらせるという1カテゴリの行動のみ行わせたい場合、サイズは1となります。
- 同様に異なるカテゴリの行動は同時に取ることができますが、同一カテゴリの行動はそれができません。
- 例えば、上記の例の場合、右回転と前進(無回転)を同時に行わせることはできません。
-
Branch 0 Size
- 配列0番目のカテゴリの行動の行動数を表します。
- 例えば、上記の例の場合、右回転、左回転、前進(無回転)の3つ存在するため、3となります。
- 配列0番目のカテゴリの行動の行動数を表します。
-
Continuous Actions
-
Model
- トレーニング済みのモデルを指定します。
- トレーニング中には使用しません。
-
Team ID
- Team ID は、複数のエージェントをグループとして識別するためのものです。
- 同じTeam IDを持つエージェントは、同じポリシーや報酬を共有します。
- ポリシーとは、エージェントがある状態における行動を選択するためのルールであり、関数として表現されます。
- 今回はエージェントごとに異なるTeam IDを設定しました。
- 青エージェントには0、赤には1、緑には2を設定しました。
Decision Requester

- 青エージェントにアタッチしたDecision Requesterのインスペクターの画像となります。
- Decision Requesterはエージェントの意思決定(行動選択)プロセスを自動で実行するためのコンポーネントです。
- これを使用しない場合は、エージェントのスクリプト内で
RequestDecision関数を手動で呼び出す必要があります。
- これを使用しない場合は、エージェントのスクリプト内で
-
DecisionPeriod
- エージェントが意思決定をリクエストする間隔(Academyステップ数)を指定します。
- Academyステップとは、観測の伝達、意思決定、行動実行、報酬付与の一連の処理を行うステップです。
- 例えば、
DecisionPeriodが10の場合、エージェントは10のAcademyステップごとに意思決定をリクエストします。 - DecisionPeriodは1-20の範囲で設定可能です。
- あまりDecisionPeriodを小さくすると、頻繁に意思決定を行い、計算負荷が増加するようです。
- 今回は、
Decision Periodを10に設定しました。
- エージェントが意思決定をリクエストする間隔(Academyステップ数)を指定します。
-
TakeActionsBetweenDecisions
- エージェントが意思決定をリクエストしていないAcademyステップの間に行動を実行するかどうかを指定します。
- TakeActionsBetweenDecisionsがtrueの場合、リクエストのないステップでは前回選択した行動と同じ行動をとり続けます。
- 具体的には、リクエストがないステップでは、毎回、AgentBlueのOnActionReceived(ActionBuffers actionBuffers)が実行され、この時、前回のリクエスト時に選択した行動(を表現する数値)が引数actionBuffersに与えられます。
- actionBuffersは意思決定の際に選択した行動(を表現する数値)を格納する配列です。
- この数値に基づいて具体的な行動(回転など)をOnActionReceived()の中で実行させます。
- actionBuffersは意思決定の際に選択した行動(を表現する数値)を格納する配列です。
- 逆に、リクエストがあるステップでは、毎回、通常通り、その時に決定した行動がOnActionReceived()の引数として与えられ実行されます。
- 具体的には、リクエストがないステップでは、毎回、AgentBlueのOnActionReceived(ActionBuffers actionBuffers)が実行され、この時、前回のリクエスト時に選択した行動(を表現する数値)が引数actionBuffersに与えられます。
- TakeActionsBetweenDecisionsがfalseの場合は、リクエストのないステップでは一切行動を実行しません。
- 具体的には、リクエストのないステップでは、毎回AgentBlueのOnActionReceived()が実行されません。
- リクエストがあるステップでは、毎回、通常通りOnActionReceived()が実行されます。
- 今回は、TakeActionsBetweenDecisionsをtrueにしました。
- falseにすると、エージェントが常に前進しかしていないように見える行動を続けるようになるためです。
設定ファイル
behaviors:
BehaviorNameAgentBlue:
trainer_type: poca
hyperparameters:
batch_size: 2048
buffer_size: 20480
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: constant
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 20
max_steps: 30000000
time_horizon: 1000
summary_freq: 10000
checkpoint_interval: 25000
self_play:
save_steps: 50000
team_change: 200000
swap_steps: 4000
window: 10
play_against_latest_model_ratio: 0.5
initial_elo: 1200.0
BehaviorNameAgentRed:
trainer_type: poca
hyperparameters:
batch_size: 2048
buffer_size: 20480
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: constant
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 20
max_steps: 30000000
time_horizon: 1000
summary_freq: 10000
checkpoint_interval: 25000
self_play:
save_steps: 50000
team_change: 200000
swap_steps: 4000
window: 10
play_against_latest_model_ratio: 0.5
initial_elo: 1200.0
BehaviorNameAgentGreen:
trainer_type: poca
hyperparameters:
batch_size: 2048
buffer_size: 20480
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: constant
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 20
max_steps: 30000000
time_horizon: 1000
summary_freq: 10000
checkpoint_interval: 25000
self_play:
save_steps: 50000
team_change: 200000
swap_steps: 4000
window: 10
play_against_latest_model_ratio: 0.5
initial_elo: 1200.0
- 訓練用の設定ファイルとなります。
- この設定ファイルは既存のself-playを利用するML-AgentsのサンプルゲームであるSoccerTwosのものをベースに作成しています。
- 3つのエージェント(青、赤、緑)の設定があり、それぞれの設定はほぼ同一のものとなっています。
-
BehaviorNameAgentBlue, BehaviorNameAgentRed, BehaviorNameAgentGreen
- 青、赤、緑エージェントの名称です。
-
trainer_type
- 使用するアルゴリズムとしてすべてのエージェントで
poca(Proximal Policy Optimization for Centralized Critics)を指定しました。
- 使用するアルゴリズムとしてすべてのエージェントで
-
self_play
- self-playをすべてのエージェントに対して行わせるようにしました。
-
その他のパラメータ
- ベースの設定ファイルとほぼ同一となっています。
学習結果
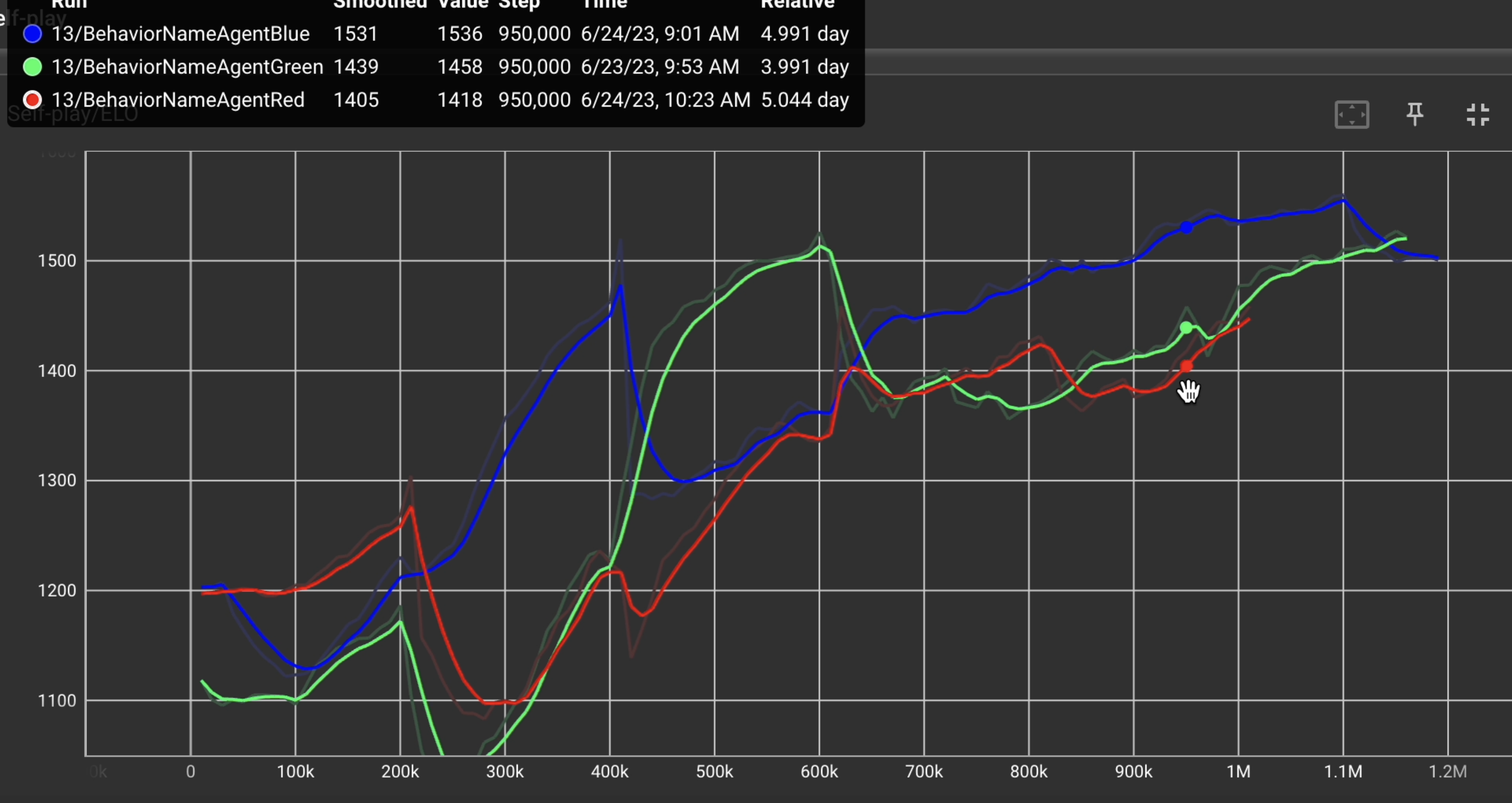
上の画像はこの学習環境下で各エージェントに100万ステップ数以上学習させて得られたELOレーティングのグラフとなります。青、赤、緑の曲線はそれぞれ、青、赤、緑エージェントのELOレーティングを表しています。
概ね右肩上がりで向上して、スムーズに学習が進みました。
上の動画は、学習後の赤緑青AIのプレイ動画となります。
具体的には、赤は1.01M、青は1.19M、緑は1.17Mステップ数学習させた学習モデルとなります。
動画前半は青を人間が手動で操作し、中盤は全てをAIが操作しています。
青を手動で操作して、実際に上記の赤緑AIと対戦してみた印象ですが、非常に強いと感じます。
下のリツイートされた動画は、赤緑青に対してそれぞれ0.4Mステップ数程度学習させた場合のプレイ動画となります。
動画前半は青を人間が手動で操作し、後半は全てをAIが操作しています。
上記の1Mステップ数以上学習させたAI程ではないにせよ、ある程度強いAIと感じます。
まとめ
本記事では、ゲーム開発者や機械学習に興味がある人を対象に、3色鬼ごっこゲーム用のAIの開発方法の知識の共有などを目的に、その知識を公開しました。
具体的には、本記事の「学習環境」の項目で、報酬の与え方や観測データ、エージェントの行動などについて触れました。
また、「実装」の項目で、実装したエージェント関係のスクリプトや訓練用の設定ファイルについて公開しました。
最後に、「学習結果」の項目で、ELOグラフを公開し、本学習環境で学習させた結果、良好な学習モデルが生成されたことを触れました。
変更履歴
- ver.0.1.0 初稿を作成しました。 2023/10/30
- ver.0.2.0 省略されていたAgentBaseクラスのGetStartPosition()メソッドとGetLookAtTargetPositionAtStart()メソッドのソースコードとその解説を記載しました。 2023/11/10