はじめに
以下のサイトで人口の推移をCSVで取得できることを知ったので、早速ダウンロードし、確認した手順をまとめてみます。
環境
- Colaboratory
- Python
準備
ライブラリのインストール
可視化するのに日本語が正しく表示されるようライブラリをインストールします。
!pip install japanize_matplotlib
以下のように表示されれば成功。
Collecting japanize_matplotlib
Downloading https://files.pythonhosted.org/packages/2c/aa/3b24d54bd02e25d63c8f23bb316694e1aad7ffdc07ba296e7c9be2f6837d/japanize-matplotlib-1.1.2.tar.gz (4.1MB)
|████████████████████████████████| 4.1MB 2.8MB/s
Requirement already satisfied: matplotlib in /usr/local/lib/python3.6/dist-packages (from japanize_matplotlib) (3.2.2)
Requirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->japanize_matplotlib) (2.8.1)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->japanize_matplotlib) (2.4.7)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib->japanize_matplotlib) (1.2.0)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib->japanize_matplotlib) (0.10.0)
Requirement already satisfied: numpy>=1.11 in /usr/local/lib/python3.6/dist-packages (from matplotlib->japanize_matplotlib) (1.18.5)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/dist-packages (from python-dateutil>=2.1->matplotlib->japanize_matplotlib) (1.12.0)
Building wheels for collected packages: japanize-matplotlib
Building wheel for japanize-matplotlib (setup.py) ... done
Created wheel for japanize-matplotlib: filename=japanize_matplotlib-1.1.2-cp36-none-any.whl size=4120191 sha256=320f4fbd50cf3f232030ce922031d1c926db2e98033cbc3059fa06e5b28d585d
Stored in directory: /root/.cache/pip/wheels/9c/f9/fc/bc052ce743a03f94ccc7fda73d1d389ce98216c6ffaaf65afc
Successfully built japanize-matplotlib
Installing collected packages: japanize-matplotlib
Successfully installed japanize-matplotlib-1.1.2
環境設定
import matplotlib.pyplot as plt
import japanize_matplotlib
import seaborn as sns
sns.set(font="IPAexGothic")
データ読込
2012年から2019年のデータがダウンロードできるので、以下のコードを実行して読み込む。
import pandas as pd
url_base = "https://satodukuri.pref.shimane.lg.jp/info/opendata/download?nendo=0000&fmt=csv"
df = pd.DataFrame()
for y in range(2012, 2020):
url = url_base.replace("0000", str(y))
df = pd.concat([df, pd.read_csv(url)])
df.shape
色々と入っていて、2384行のデータがあることがわかる。
(2384, 109)
データ確認
df.info()
実行結果
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2384 entries, 0 to 297
Columns: 109 entries, 年度 to 女性90歳以上推計生残率
dtypes: float64(56), int64(47), object(6)
memory usage: 2.1+ MB
109列ある...意外と多いな。
for col in df.columns:
print(col)
実行結果。
年度
地区コード
地区名
市町村名
合併前市町村
地域設定
現場支援地区の指定
注釈
男女人口総数
世帯数
高齢化率
後期高齢化率
人口増減率
4歳以下比率
20~30代女性比率
中学生人口比率
小学生人口比率
生産年齢人口比率
若年齢層比率
小学生人口
中学生人口
人口維持組数
小学生維持組数
男性人口 0~4歳
男性人口 5~9歳
男性人口 10~14歳
男性人口 15~19歳
男性人口 20~24歳
男性人口 25~29歳
男性人口 30~34歳
男性人口 35~39歳
男性人口 40~44歳
男性人口 45~49歳
男性人口 50~54歳
男性人口 55~59歳
男性人口 60~64歳
男性人口 65~69歳
男性人口 70~74歳
男性人口 75~79歳
男性人口 80~84歳
男性人口 85~89歳
男性人口 90~94歳
男性人口 95~99歳
男性人口 100歳以上
女性人口 0~4歳
女性人口 5~9歳
女性人口 10~14歳
女性人口 15~19歳
女性人口 20~24歳
女性人口 25~29歳
女性人口 30~34歳
女性人口 35~39歳
女性人口 40~44歳
女性人口 45~49歳
女性人口 50~54歳
女性人口 55~59歳
女性人口 60~64歳
女性人口 65~69歳
女性人口 70~74歳
女性人口 75~79歳
女性人口 80~84歳
女性人口 85~89歳
女性人口 90~94歳
女性人口 95~99歳
女性人口 100歳以上
男性コーホート変化率(0~4歳)
男性コーホート変化率(5~9歳)
男性コーホート変化率(10~14歳)
男性コーホート変化率(15~19歳)
男性コーホート変化率(20~24歳)
男性コーホート変化率(25~29歳)
男性コーホート変化率(30~34歳)
男性コーホート変化率(35~39歳)
男性コーホート変化率(40~44歳)
男性コーホート変化率(45~49歳)
男性コーホート変化率(50~54歳)
男性コーホート変化率(55~59歳)
男性コーホート変化率(60~64歳)
男性コーホート変化率(65~69歳)
男性コーホート変化率(70~74歳)
男性コーホート変化率(75~79歳)
男性コーホート変化率(80~84歳)
男性コーホート変化率(85~89歳)
男性コーホート変化率(90~94歳)
男性コーホート変化率(95~99歳)
男性コーホート変化率(100歳以上)
男性90歳以上推計生残率
女性コーホート変化率(0~4歳)
女性コーホート変化率(5~9歳)
女性コーホート変化率(10~14歳)
女性コーホート変化率(15~19歳)
女性コーホート変化率(20~24歳)
女性コーホート変化率(25~29歳)
女性コーホート変化率(30~34歳)
女性コーホート変化率(35~39歳)
女性コーホート変化率(40~44歳)
女性コーホート変化率(45~49歳)
女性コーホート変化率(50~54歳)
女性コーホート変化率(55~59歳)
女性コーホート変化率(60~64歳)
女性コーホート変化率(65~69歳)
女性コーホート変化率(70~74歳)
女性コーホート変化率(75~79歳)
女性コーホート変化率(80~84歳)
女性コーホート変化率(85~89歳)
女性コーホート変化率(90~94歳)
女性コーホート変化率(95~99歳)
女性コーホート変化率(100歳以上)
女性90歳以上推計生残率
...結構細かい。
データ表示
市町村名を確認
df["市町村名"].value_counts()
出雲市 344
松江市 256
雲南市 240
大田市 216
浜田市 200
安来市 192
益田市 160
江津市 160
隠岐の島町 120
美郷町 104
邑南町 96
津和野町 96
奥出雲町 72
吉賀町 40
飯南町 40
川本町 24
西ノ島町 8
海士町 8
知夫村 8
Name: 市町村名, dtype: int64
ふむふむ...
松江市の地区名を確認
df[df["市町村名"] == "松江市"]["地区名"].value_counts()
秋鹿 8
忌部 8
生馬 8
鹿島 8
城北 8
意東 8
上意東 8
大野 8
出雲郷 8
本庄 8
法吉 8
美保関 8
津田 8
古志原 8
持田 8
川津 8
島根 8
雑賀 8
大庭 8
朝日 8
城東 8
宍道 8
乃木 8
八束 8
揖屋 8
朝酌 8
玉湯 8
竹矢 8
古江 8
白潟 8
八雲 8
城西 8
Name: 地区名, dtype: int64
ふむふむ...
可視化
とりあえず、面白そうな「男女人口総数」「小学生人口」「中学生人口」「高齢化率」をグラフで書いてみる。
df_area = df.groupby(["市町村名", "年度"]).sum()
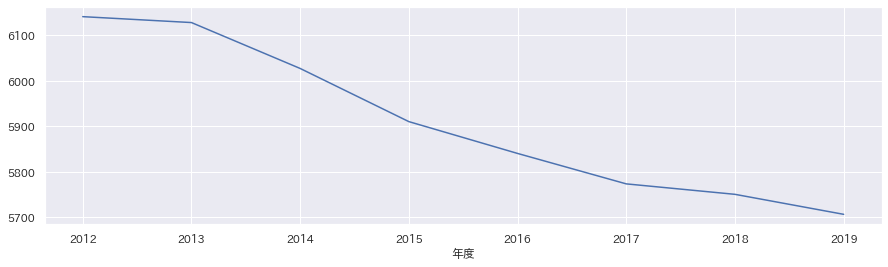
df_area.loc["松江市"]["男女人口総数"].plot(figsize=(15,4))
plt.show()
df_area.loc["松江市"]["小学生人口"].plot(figsize=(15,4))
plt.show()
df_area.loc["松江市"]["中学生人口"].plot(figsize=(15,4))
plt.show()
df_area = df.groupby(["市町村名", "年度"]).mean()
df_area.loc["松江市"]["高齢化率"].plot(figsize=(15,4))
plt.show()
実行結果。
男女人口総数
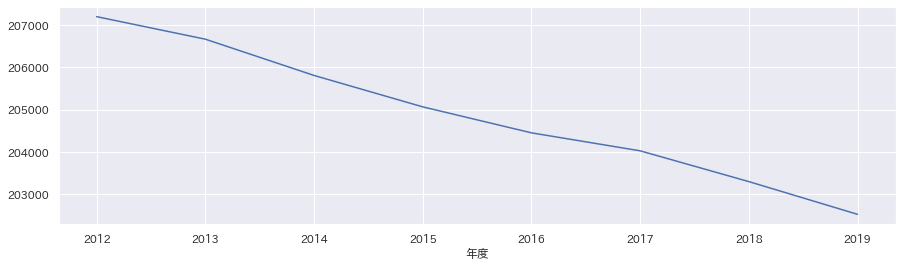
小学生人口
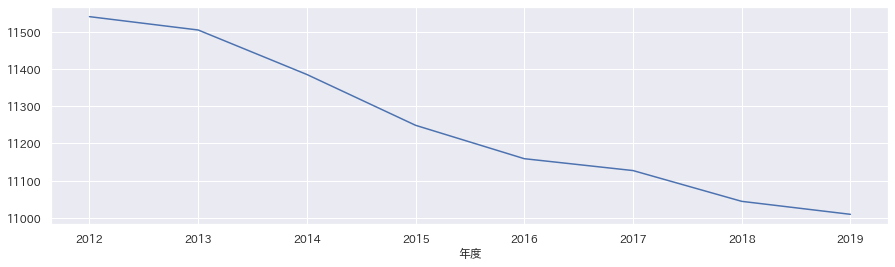
中学生人口
高齢化率
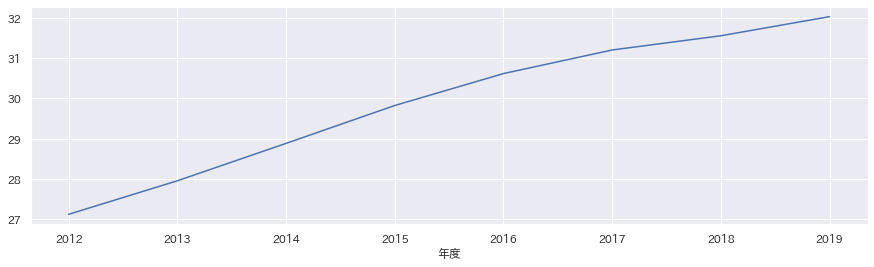
...芳しくないな。