はじめに
事務所の窓から正面にある駐車場の映像を5分ごとに撮影して動画を作って遊んでいます。
はじめの頃はそれだけで面白かったのですが、だんだんとつまらくなってきて「何か他にできることないかな〜」って考えていたら表題のようなことを思いついたので取り組んでみました。
また、この結果をWebサイトで常に確認できるようにしてます。
駐車場 状態監視のサンプル
※ 上述のとおり、写真は5分周期で更新されます。
使用するライブラリ
使用するライブラリをインストール。
OpenCV
pip install -U pip
pip install python-opencv
Tensorflow
pip install tensorflow
Keras
pip install keras
準備
まず、以下のフォルダを作成。
├ img
│ ├ 0-多い
│ ├ 1-少ない
│ └ 2-ガラガラ
└ models
次に、img以下のそれぞれのフォルダに分類したい画像を保存。
今回はおよそ1週間分の画像データで、2019枚の画像を使用。
多い


少ない


ガラガラ


学習
フォルダの分類にしたがって画像を学習。
# ライブラリ読込
import glob
import cv2
from matplotlib import pyplot as plt
import numpy as np
import keras
import tensorflow as tf
from sklearn import model_selection
from keras.utils.np_utils import to_categorical
from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D, Dropout
from keras.models import Sequential
import random
# ラベルデータ作成
labels = []
for i in range(3):
labels.append("{}-".format(i))
# 画像ファイル数の取得
n = []
for l in labels:
files = glob.glob("img/{}*/*.jpg".format(l))
print("{} : {}".format(l, len(files)))
n.append(len(files))
# 画像ファイル読込
imgX = []
y = []
k = 0
for l in labels:
print(l)
files = glob.glob("img/{}*/*.jpg".format(l))
files.sort()
print(len(files), end=" -> ")
# 使用する画像は最少分類区分の1.5倍まで
j = int(min(n) * 1.5)
if j > len(files):
j = len(files)
files = random.sample(files, j)
print(len(files))
i = 0
for f in files:
img = cv2.imread(f)
h, w, c = img.shape
# 上半分は車と関係ないので画像を加工
img = img[int(h/2):h, :]
img = cv2.resize(img, (100, 100))
imgX.append(img)
y.append(k)
print("\r{}".format(i), end="")
i += 1
print()
k += 1
# 画像データを配列データに変換
X = np.array(imgX)
X = X / 255
# 学習・検証用データに分割
test_size = 0.2
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=test_size, random_state=42)
X_valid, X_test, y_valid, y_test = model_selection.train_test_split(X_test, y_test, test_size=.5, random_state=42)
y_train = to_categorical(y_train)
y_valid = to_categorical(y_valid)
y_test = to_categorical(y_test)
# 学習モデルの作成
input_shape = X[0].shape
model = Sequential()
model.add(Conv2D(
input_shape=input_shape, filters=64, kernel_size=(5, 5),
strides=(1, 1), padding="same", activation='relu'))
model.add(MaxPooling2D(pool_size=(4, 4)))
model.add(Conv2D(
filters=32, kernel_size=(5, 5),
strides=(1, 1), padding="same", activation='relu'))
model.add(Conv2D(
filters=32, kernel_size=(5, 5),
strides=(1, 1), padding="same", activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(
filters=16, kernel_size=(5, 5),
strides=(1, 1), padding="same", activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(1024, activation='sigmoid'))
model.add(Dense(2048, activation='sigmoid'))
model.add(Dense(len(labels), activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
# 学習
history = model.fit(
X_train, y_train, batch_size=400, epochs=200,
verbose=1, shuffle=True,
validation_data=(X_valid, y_valid))
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
# 学習済みモデルの保存
mdlname = "models/mdl_parking_status.h5"
model.save(mdlname)
途中の出力は割愛して、学習結果は以下のとおり。
validation loss:0.15308915078639984
validation accuracy:0.9653465151786804
学習の過程をグラフで確認すると以下のとおり。
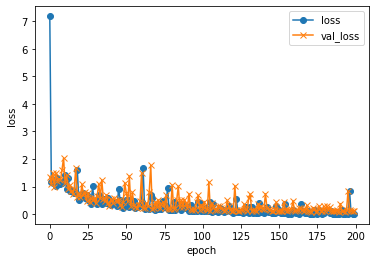
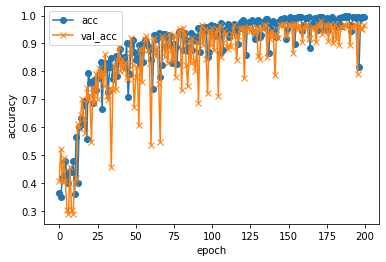
なんとなく学習できてそう。
識別
以下のスクリプトで識別。
# ライブラリ読込
import glob
import cv2
from matplotlib import pyplot as plt
import numpy as np
import requests
import keras
# 学習済みモデルの読込
mdlname = "models/mdl_parking_status.h5"
model = keras.models.load_model(mdlname)
# ラベルデータの作成
labels = []
for lbl in glob.glob("img/*"):
labels.append(lbl.split("/")[-1])
labels.sort()
# 画像読込
img_url = "https://map.blueomega.jp/parking/img.jpg"
req = requests.get(img_url)
img_org = np.fromstring(req.content, dtype='uint8')
img_org = cv2.imdecode(img_org, 1)
h, w, c = img_org.shape
img = img_org[int(h/2):h, :]
img = cv2.resize(img, (100, 100))
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
X = np.array([img])
X = X / 255
# 識別
pred = model.predict(X, batch_size=32)
m = np.argmax(pred[0])
# 結果表示
print(pred)
print(labels[m])
取得した画像はこちら。

識別結果は以下のとおり。
[[9.2753559e-01 7.2361618e-02 1.0272356e-04]]
0-多い
...多分できた!