はじめに
色々とセミナーをさせて頂くことが多くなり、特にAI関連技術のセミナーではあまり知らないで話をしていると、実は間違っていました...なんてことになりかねない。
ということで、勉強のためにAutoEncoderをScikit-learnで実装してみたので、その手順を以下にまとめます。
データセット
手書きの数字データがScikit-learnに用意されているのでこちらを利用します。
読み込んだら、いくつかの画像を表示して、どんな感じか確認します。
from sklearn.datasets import load_digits
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
dig = load_digits()
for i in [10, 230, 450]:
npimg = np.array(dig.data[i])
npimg = npimg.reshape((8, 8))
plt.imshow(npimg, cmap='gray')
plt.show()
実行結果は以下のとおり。
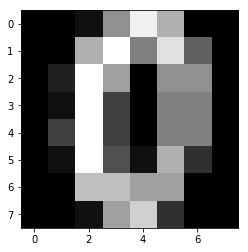
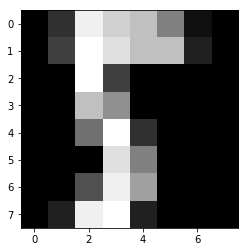
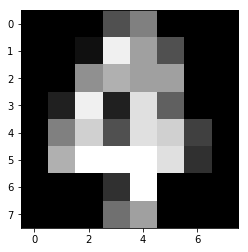
入力データ作成
データセットから入力と出力のデータを取得し、学習用と検証用にデータを分けます。
ここで、エンコーダーの学習にもデータの一部を使うので、半分ずつにわけています。
import pandas as pd
X = pd.DataFrame(dig.data)
y = pd.DataFrame({"y":dig.target})
from sklearn import model_selection
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=.5, random_state=42)
# 後で使うので先にとっておきます
y_proba = pd.DataFrame(X_test)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
学習
先ほどのデータをニューラルネットワークで学習します。
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(random_state=42)
model.fit(X_train, y_train.as_matrix().astype("int").flatten())
model.score(X_test, y_test)
実行してみると、スコアは「0.9699666295884316」でした。
エンコーダー
次にエンコーダーを作ります。
ここで、検証用のデータからpredict_probaを使って10個の配列データを取得し、入力データとします。
そして、教師データとして検証データのセルごとの値をy_proba_cellsに分解します。
モデルをセルの数と同じだけ用意し、それぞれのセルごとに入力値に対する出力を学習させます。
X_proba = pd.DataFrame(model.predict_proba(X_test))
y_proba_cells = []
for col in y_proba.columns:
y_proba_cells.append(y_proba[col])
model_proba = []
for i in range(y_proba.shape[1]):
model_proba.append(MLPClassifier(max_iter=500, random_state=42))
for i in range(y_proba.shape[1]):
model_proba[i].fit(X_proba, y_proba_cells[i])
画像生成
学習後のモデルに、出力したい数値に応じた配列を入力し、得られたセルごとの予測値から、画像を生成してみます。
X_encode = 6
m = [0] * 10
m[X_encode] = 1
X_encode = m
result = []
for i in range(y_proba.shape[1]):
result.append(model_proba[i].predict([X_encode])[0])
npimg = np.array(result)
npimg = npimg.reshape((8, 8))
plt.imshow(npimg, cmap='gray')
実行した結果は、こちらです。
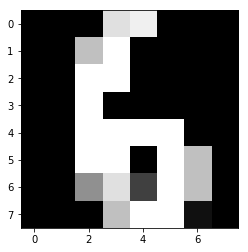
6っぽい(^-^)
次は0と9の確率が0.5づつの場合を試してみます。
X_encode = [0.5,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.5]
result = []
for i in range(y_proba.shape[1]):
result.append(model_proba[i].predict([X_encode])[0])
npimg = np.array(result)
npimg = npimg.reshape((8, 8))
plt.imshow(npimg, cmap='gray')
実行すると...
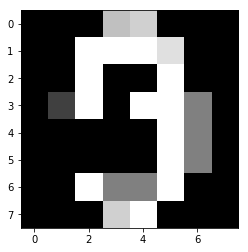
0のような9のような...新しい数字が生まれた感じ(^_^;)
できた!