はじめに
機械学習でどのくらい電力需要を予測できるのか試してみたので、その手順を整理します。
追記
この記事を書いてから半年が経ち、いろいろ新しいこともわかってきたので、パート2の記事を書いてみました。
機械学習で電力需要を予測してみる パート2
追々記
2017/12/22に以下の記事も作成したので、あわせてご参照下さい。
TensorFlowで電力使用量予測 with Keras
追々々記
2021/01/31に実際に未来を予測する記事を作成しているので、あわせてご参照下さい。
H2O.aiのAutoMLを使って電気使用量を学習し、気象予報値取得APIを使って数日後の電気使用量を予測してみる
使用した環境
機械: MacBook Air Mid 2012
言語: Python 3.5.1
実行: Jupyter notebook 4.2.1
ライブラリ: scikit-learn on Anaconda 4.1.0
データ収集
電力需要
まずは東京電力のサイトから電力需要のデータをダウンロードします。
http://www.tepco.co.jp/forecast/html/download-j.html
※2016/8/12現在、2016/4/1〜8/11の一時間毎のデータをダウンロードできました。
ファイル名は"juyo-2016.csv"でした。
ダウンロードしたデータは日付、時刻、電力実績のCSVですが、少し余計な文字列が入っているので、修正してUTF-8で保存します。
保存したデータの形式は以下のとおり。
| DATE | TIME | 実績(万kW) |
|---|---|---|
| 2016/04/01 | 00:00 | 234 |
| 2016/04/01 | 01:00 | 235 |
| ... |
気温
次に何か参考資料ないかな〜と探してみると、気象庁から過去の気象データがダウンロードできたので、電力需要のデータと同じ期間・間隔のデータをダウンロードします。
ファイル名は"data.csv"でした。
ダウンロードしたデータは日時、気温、品質情報、均質番号のCSVですが、少し余計な文字列が入っているので、修正してUTF-8で保存します。
保存したデータの形式は以下のとおり。
| 日時 | 気温(℃) |
|---|---|
| 2016-04-01 00:00 | 15 |
| 2016-04-01 01:00 | 16 |
| ... |
データ取り込み
import pandas as pd
import numpy as np
# 電力データの読み込み
kw_df = pd.read_csv("juyo-2016.csv")
# 気温データの読み込み
temp_df = pd.read_csv("data.csv")
※ 電力のデータは以下のようにURLを直接指定し、気温のデータはダウンロードしたものをそのまま読み込むことも可能
import pandas as pd
url = "http://www.tepco.co.jp/forecast/html/images/juyo-2016.csv"
kw_df = pd.read_csv(url, encoding="shift_jis", skiprows=2)
kw_df.head()
file = "data.csv"
temp_df = pd.read_csv(file, encoding="shift_jis", skiprows=4)
temp_df = temp_df[temp_df.columns[:2]]
temp_df.columns = ["日時","気温(℃)"]
データ加工
機械学習にかけるにあたり、データを結合したり、機械学習用に数値データへ変換する作業を行います。
まず、日付データはそのままでは使い物にならないので、曜日データに変換してみます。
[例]
日曜日 -> 0
月曜日 -> 1
...とか
次に、1時間毎のデータなので、時間をデータに変換します。
[例]
0:00 -> 0
1:00 -> 1
...とか
# データの結合
df = kw_df
df["気温"] = temp_df["気温(℃)"]
# 曜日データの取得
import datetime
pp = df["DATE"]
tmp = []
for i in range(len(pp)):
d = datetime.datetime.strptime(pp[i], "%Y/%m/%d")
tmp.append(d.weekday())
df["weekday"] = tmp
# 時間データの取得
pp = df["TIME"]
tmp = []
for i in range(len(pp)):
d = datetime.datetime.strptime(pp[i], "%H:%M")
tmp.append(d.hour)
df["hour"] = tmp
学習データとテストデータの作成
加工したデータから学習用のデータとテスト用のデータを作成します。
ここでは、入力に使用する変数は"気温","曜日","時刻"として、出力される変数を"電力"とします。
加工したデータの並びは、"DATE","TIME","実績(万kW)","気温","weekday","hour"となっているので、入力(説明変数)を3,4,5列目から取得し、出力(出力変数)は2列目の実績(万kw)を利用します。
また、機械学習用にデータを正規化します。
# 入力
pp = df[["気温","weekday","hour"]]
X = pp.as_matrix().astype('float')
# 出力
pp = df["実績(万kW)"]
y = pp.as_matrix().flatten()
# クロスバリデーションのモジュールを読み込む
from sklearn import cross_validation
# ラベル付きデータをトレーニングセット (X_train, y_train)とテストセット (X_test, y_test)に分割
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size=.2, random_state=42)
# 正規化のモジュールを読み込む
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
学習
SVMで機械学習してみます。
# モジュールの読み込み
from sklearn import svm
model = svm.SVC()
# 学習
model.fit(X_train, y_train)
# model.score(X,y)を使って予測精度を出す
print(model.score(X_test,y_test))
予測スコアは、何と「0.00312989045383」!!
あまりのスコアの低さにびっくり!!
ダメじゃん!って思うじゃないですか...
予測結果の確認
どんな感じなのか確認するために、グラフを描画して確認してみました。
# 誤差計算
pp = pd.DataFrame({'kw': np.array(y_test), "result": np.array(result)})
pp["err"] = pp["kw"] - pp["result"]
pp.plot()
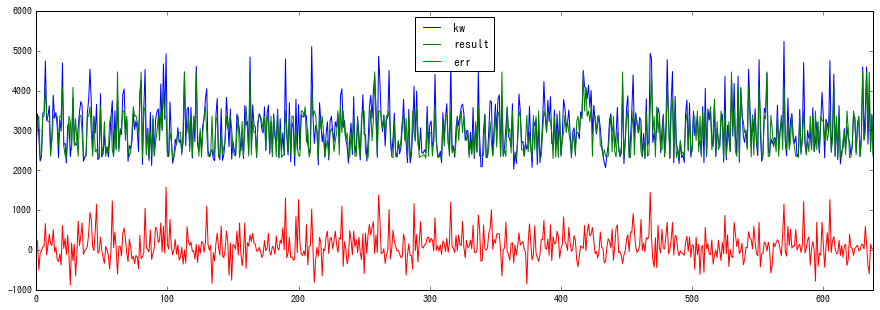
何だか、それなりに追従してそうな感じ(^-^)
予測結果を実際の数値で確認。
err_max = 0
err_min = 50000
err_ave = 0
for i in range(len(pp)):
if err_max < pp["err"][i]:
err_max = pp["err"][i]
if err_min > pp["err"][i]:
err_min = pp["err"][i]
err_ave += pp["err"][i]
print(err_max)
print(err_min)
print(err_ave / i)
実行結果は、以下のとおり。
1571
-879
114.81661442
うーん、この結果はどうなんだろう。良いのか悪いのか、判断できない...(-_-;)
実際はもっと考えないといけないことあるんだろうけど、過去データの少ない状況で電力需要予測をしないといけないようなことがあったら、そこそこ参考になる結果なのではないかと思ったりしました。
ちなみに、Jupyter Notebookのファイルと加工後のCSVファイルをGitHubに公開したのであわせてご参照下さい。