はじめに
世の中にあるお仕事の中に「図面の中に描かれている特定の記号の数を数える」という作業があるらしく、これを機械学習で解決できないだろうかという相談があった。
それはそんなに難しくなくできるだろうなぁ〜なんて思ったら意外とはまったので、手順を整理してメモしておく。
必要なもの
- 図面のデータ
電気工事士の過去問にいくつか図面があったのでそれを使用。
データはJPEG形式 - Python
3系を使用 - OpenCV
ちなみにMacを使用して行いました。他の環境ではコマンド名などが若干異なるかもしれません。
環境構築については、いつも手前味噌ではありますが以下の記事をご参照下さい。
また、バージョンについても適宜修正してご利用下さい。
Macで深層学習の環境をさくっと作る手順 with TensorFlow and OpenCV
概要
以下のような図面があります。

この中から以下の記号を抽出できるようにしてみます。
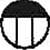


準備
抽出したい画像
まずは、以下のように抽出したい記号だけが入った画像を用意します。
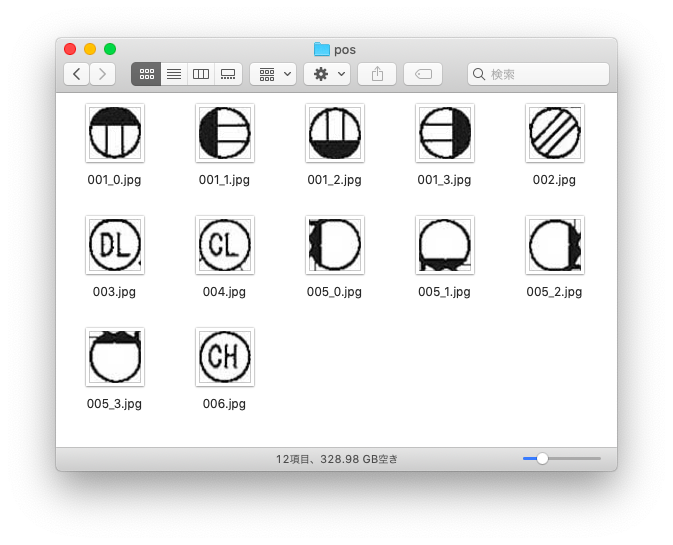
ここでは画像のサイズを幅50、高さ50としました。
抽出しない画像
次に、抽出したい記号が入っていない画像を用意します。
これには特に制約がないので、適当に記号のない範囲を選んで切り出したものを数個用意します。
以下のように適当に切り出したものを10数個作成しました。

フォルダ構成
以下のフォルダを作成します。
- pos
抽出したい記号の画像を入れるフォルダ - neg
抽出したい記号の入っていない画像を入れるフォルダ - vec
途中で生成するベクトルデータを保存するフォルダ - work
作業用に使用するフォルダ - cascade
学習結果を保存するフォルダ - sample
図面の画像を保存するフォルダ - detected
抽出結果の画像を保存するフォルダ
ベクトルデータの作成
作成した記号の画像から20個ずつのベクトルデータを作成し、それを結合して一つのベクトルデータを作成します。
ベクトルデータの結合には以下のライブラリを使用します。
mergevec.pyというファイルをダウンロードして同じフォルダに入れておいて下さい。
from glob import glob
import subprocess
from mergevec import merge_vec_files
n = 20
files = glob("pos/*.jpg")
for i in range(len(files)):
file = files[i]
vec = "work/{}.vec".format(i)
cmd = ["opencv_createsamples", "-vec", vec, "-img", file, "-num", str(n), "-bgcolor", "255"]
res = subprocess.call(cmd)
merge_vec_files("work", "vec/pos.vec")
抽出するものが入っていない画像の一覧を作成
以下のコマンドでテキストファイルを作成します。
ls neg | Xargs -I {} echo neg/{} > neglist.txt
抽出する記号の学習
OpenCVのopencv_traincascadeというコマンドを使って記号を学習させます。
opencv_traincascade -data cascade -vec vec/pos.vec -bg neglist.txt -numPos 190 -featureType LBP
それなりに時間がかかりますが、学習が終わるとcascadeフォルダにcascade.xmlというファイルが作成されます。
記号の抽出
学習結果を利用して、記号の抽出を実施します。
from glob import glob
import matplotlib.pyplot as plt
import cv2
def marking(img, cascadeFileName):
cascade_path = cascadeFileName
cascade = cv2.CascadeClassifier(cascade_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
marker = cascade.detectMultiScale(gray)
for (x,y,w,h) in marker:
penned_img = cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
return penned_img
imgFileNames = glob("sample/*.jpg")
for filename in imgFileNames:
print(filename)
img = cv2.imread(filename)
cascadeFileName = "cascade/cascade.xml"
img = marking(img, cascadeFileName)
cv2.imwrite("detected/{}".format(filename.split("/")[-1]), img)
上記スクリプトを実行するとsampleフォルダの中にある画像から記号を抽出して四角で囲み、detectedフォルダに保存します。
実行結果。

誤検出や未検出も見受けられますが、とりあえず最初のステップは完成!
後は抽出精度を向上させ、誤検出したものは別途TensorFlowなどで正しいものとそうでないものを識別させれば良いかなと思います。
...ということで、できた!!