概要
こちらは AWS for Games Advent Calendar 2023 の 8 日目の記事です。
「仕事で困った時、ChatGPTみたいなAIに聞きたい!」
とはいえ、ChatGPTに業務データを読ませるのはセキュリティ的に許容されないことが多いかと思います。
そこで!セキュリティをちゃんとして(くれてるAWSを使って)ツールを作ろうと思います。
普段AIに触らない普通のエンジニアがいろんな資料を頼りに作りながら書いた記事です。
細かいステップに分けて確認しながら実装したので、なぞってもらえれば理解しながら bot を作成できると(いいなって)思います。
コードは微妙なのでリファクタお願いしますmm
調査
まずどんなサービスがあるのか調べてみました。
生成系 AI = Bedrock
Bedrock がおすすめみたいです。
プライバシー、コンプライアンス、セキュリティ周りがいい感じっぽいですね(わかってない)。
業務で扱う情報を元に答えてほしい = Kendra
うーん、Bedrock を Kendra でRAG(Retrieval Augmented Generation) するといい感じらしいです!(わかってない)
※RAGを含めた言い回しって難しいですね。。手法らしいので「RAGする」と言っておけばいいっぽい..??
余談ですが、Knowledge base とかも発表されてRAGの選択肢も増えてるみたいです。
東京リージョン来てほしいですね!
構成案
UIどうするかで構成にバリエーションがありそうです。
- 専用のサイトで質問して答えてもらう
- 多分、Amplify + Cognito + API Gateway + Lambda + Kendra + Bedrock?
- Slack でやりとりする
- 多分、API Gateway + Lambda + Kendra + Bedrock?
※Lambda の部分は他にも沢山選択肢がありそうですね!
どっちも良さそうですが、直前までぼんやりしてたのでこの記事書ききるまでの猶予がありません!!(自業自得)
比較的簡単そうな「2. Slack でやりとりする」方針で作っていきます!
注意
もし作って運用する場合、各サービスの利用料金に注意して下さい。
特に Kendra は業務用のサービスなのでお高めな従量課金となっています。
※2023/12/06時点では下記の記載があるので気にせず使っていきます。使う前にご確認下さい。
最初の 30 日間で最大 750 時間の無料利用枠が提供される Amazon Kendra Developer Edition を無料で始めることができます。
実装
Lambda や API Gateway を使う予定なので、ここからは GitHub リポジトリ作って、AWS のリソースを Terraform で管理しようと思います。
※Kendra data source だけは Terraform の対応状況が怪しかったので手動設定にしています。
※Terraform 用の IAM がローカルにある前提です。
プロジェクト作成
Bedrock,Kendra を使った Bot なので、適当に「bks=(Bedrock Kendra System」とします。
※試される場合は名前を違うのにして頂ければ、S3バケット名とか重複しなくてスムーズです。
まずは Terraform を準備しましょう!
mkdir bks
cd bks
mkdir terraform # 振り返るとこのディレクトリいらんかった...
touch terraform/provider.tf
Terraform プロバイダ設定
※今回 staging 環境で試すので、staging としていますが、適宜変更してください。
Terraform コードはこちら
terraform {
required_version = ">=1.3.5"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~>5.22.0"
}
}
# tfstate を s3 に保存(https://developer.hashicorp.com/terraform/language/settings/backends/s3)
backend "s3" {
bucket = "bks-tfstate-staging" # 適宜変更して下さい。
key = "bks.tfstate" # 適宜変更して下さい
region = "ap-northeast-1" # こだわりなければ東京じゃなくてもいいです
profile = "terraform" # 適宜変更して下さい
}
}
# -----------------------------
# Provider
# -----------------------------
provider "aws" {
profile = "terraform" # 適宜変更して下さい
region = "ap-northeast-1"
default_tags {
tags = {
Env = "stg" # 適宜変更して下さい
System = "bks" # 適宜変更して下さい
}
}
}
tfstate 保存用 S3 作成
適当に作成して下さい。
terraform 初期処理
# `terraform` ディレクトリで実行
# cd terraform
terraform init
Kendra にデータを入れる
Kendra index を作成する
まずはKendraにデータ入れて検索できること確認したいです。
ここでは terraform コードを載せますが、チュートリアルや他の記事見る限り、AWSの検索窓から「Amazon Kendra」で検索して、「Create an Index」を押して index という箱をつくっていくみたいですね!
Terraform で Kendra index 作成
terraform で実施していますが、やっていることはコンソールからほぼデフォルトで作成するのとかわりません。
# プロジェクトルートで実行
touch terraform/main.tf
touch terraform/variables.tf
mkdir -p terraform/modules/kendra
touch terraform/modules/kendra/main.tf
touch terraform/modules/kendra/variables.tf
Terraform コードはこちら
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
module "kendra" {
source = "./modules/kendra"
account_id = data.aws_caller_identity.current.account_id
region_name = data.aws_region.current.name
service_name = var.service_name
environment = var.environment
retention_in_days = var.retention_in_days
}
variable "service_name" {
type = string
default = "bks"
}
variable "environment" {
type = string
default = "stg"
}
variable "retention_in_days" {
type = number
default = 1 # CloudWatchLogs の保存期間(日数)です
}
# -----------------------------
# Kendra index
# -----------------------------
resource "aws_kendra_index" "bks_kendra" {
name = "bks"
edition = "DEVELOPER_EDITION" # これは無料枠のために大事!
role_arn = aws_iam_role.bks_kendra.arn
}
# -----------------------------
# Kendra インデックス IAM ロール
# -----------------------------
resource "aws_iam_role" "bks_kendra" {
name = "${var.service_name}-${var.environment}-kendra-index"
assume_role_policy = data.aws_iam_policy_document.kendra_assume_role.json
}
// assume role
data "aws_iam_policy_document" "kendra_assume_role" {
statement {
actions = ["sts:AssumeRole"]
effect = "Allow"
principals {
identifiers = ["kendra.amazonaws.com"]
type = "Service"
}
}
}
# policy と紐づけ
resource "aws_iam_role_policy_attachment" "bks_kendra" {
role = aws_iam_role.bks_kendra.name
policy_arn = aws_iam_policy.bks_kendra.arn
}
# policy
resource "aws_iam_policy" "bks_kendra" {
name = "${var.service_name}-${var.environment}-kendra-index-policy"
policy = data.aws_iam_policy_document.bks_kendra.json
}
data "aws_iam_policy_document" "bks_kendra" {
statement {
effect = "Allow"
actions = ["cloudwatch:PutMetricData"]
resources = ["*"]
condition {
test = "StringEquals"
values = ["Kendra"]
variable = "cloudwatch:namespace"
}
}
statement {
effect = "Allow"
actions = ["logs:CreateLogGroup"]
resources = ["arn:aws:logs:${var.region_name}:${var.account_id}:log-group:/aws/kendra/*"]
}
statement {
effect = "Allow"
actions = [
"logs:DescribeLogStreams",
"logs:CreateLogStream",
"logs:PutLogEvents"
]
resources = ["arn:aws:logs:${var.region_name}:${var.account_id}:log-group:/aws/kendra/*:log-stream:*"]
}
statement {
effect = "Allow"
actions = ["logs:DescribeLogGroups"]
resources = ["*"]
}
}
# -----------------------------
# log
# -----------------------------
resource "aws_cloudwatch_log_group" "bks_kendra" {
name = "/aws/kendra/${aws_kendra_index.bks_kendra.id}"
retention_in_days = var.retention_in_days
}
variable "account_id" {
type = string
}
variable "region_name" {
type = string
}
variable "service_name" {
type = string
}
variable "environment" {
type = string
}
variable "retention_in_days" {
type = number
}
差分を確認してから実行しましょう!
terraform init # モジュール追加後の1回目は必要!
terraform plan
# よければ
terraform apply
# ここでほんまにデプロイする?と聞かれるので、 yes と答えたらデプロイされます。
作成してから30分くらいかかるみたいなのでここで待ちます。
Kendra data source を作成する
次に作成した index を選択して、data source を追加します。
ここは terraform がまだ対応怪しいのでコンソールから行っていきましょう!
私は自社のホームページを指定してみます。
Web Clawler でやるみたいです。
ドキュメントかなにかに V2.0 使うんやでって書いてた気がするので、V2.0を選択
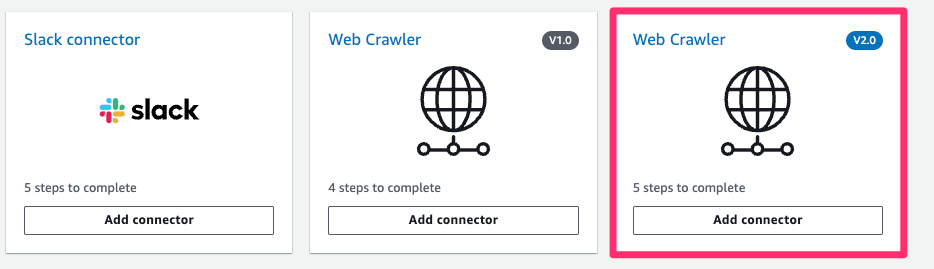
- Data source name:
homepage - Default language:
Japanese(ja) - Source URLs:
(それぞれクロールしても良いURLを指定して下さい) - IAM role:
Create a new role(Recommended) - Role name:
AmazonKendra-(サイト名とか)(任意) - Frequency:
Run on demand
Frequency の指定で自動でデータ更新もできますが、今回は手動でデータ取得する Run on demand で試しています。
Kendra data source を Sync
詳細画面に戻ったら右上の「Sync now」を押しましょう!

数分〜数十分かかるので気長に待ちます。
手動で設定している場合、CloudWatch に /aws/kendra/(kendra index の id)というロググループができてると思うので、保持期間を変更したい場合は設定しておきましょう。
(ロググループ名はぱっとわかるようにしておきたいので、ID じゃなくて Name をユニークにして Name で作って欲しい...)
Kendra でデータ検索の動作確認
サイドバーの「Search indexed content」 をクリックして検索画面を開きます。
いきなり検索するとだめです。
日本語で検索するためには、Settingsで日本語に変更してあげる必要があります。
検索してみましょう!
※画像わすれちゃいました...
上手くいきましたね!
Bedrock を使う
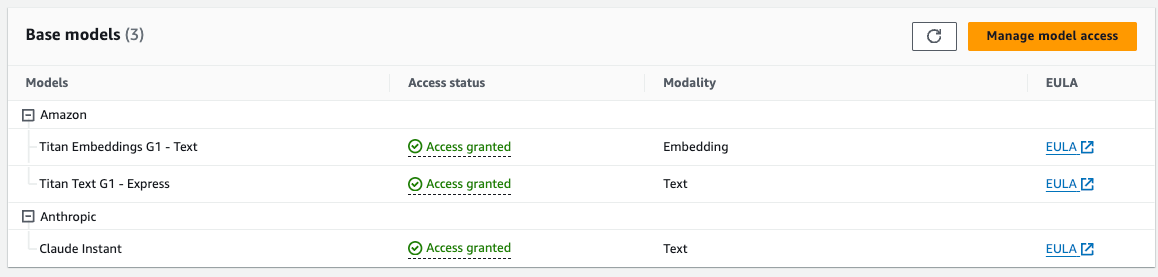
Claude Instant を有効化
モデルについてはよくわかりませんが、
今回は公式のチュートリアルでも使ってた Claude Instant を使います。
Amazon Bedrock を検索窓で検索して、
サイドバーの Model access をクリックして、
右上にある Manage model access を押して、
チェックをつけて Save changes することで有効化します。
※ユースケースを聞かれた場合は適宜入力して下さい。
英語はそこまで正確じゃなくても良いみたいです。
下記は有効化した状態です。
Bedrockと対話してみる
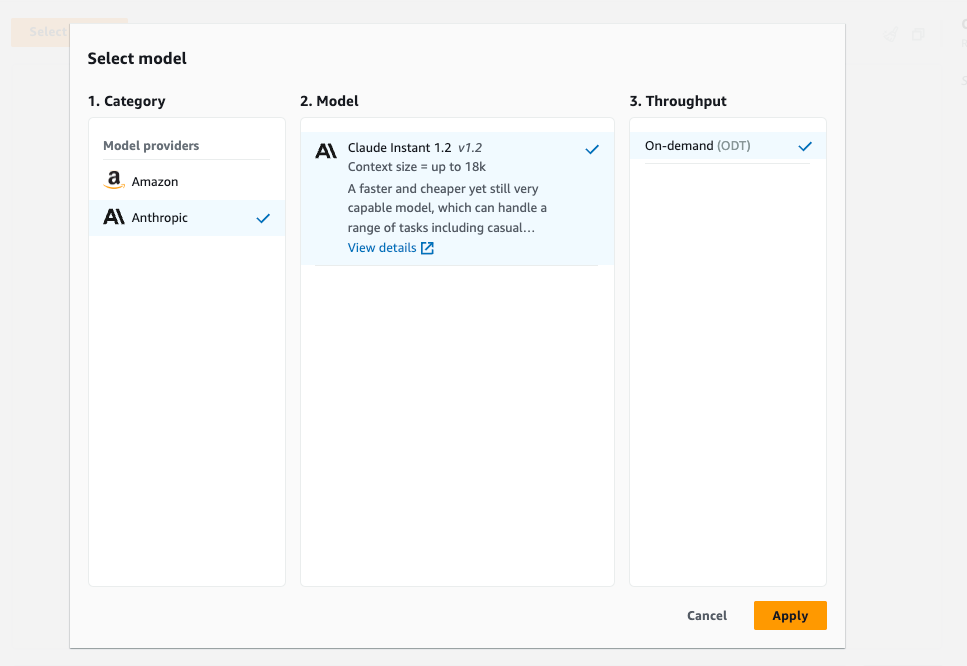
まずちょっと使ってみましょう。
サイドバーの Chat を選択して、
Select model から Anthropic の Claude Instant 1.2を選択します。
さて Kendra で RAG して Bedrock を使いたいのですが、手っ取り早く動作確認できないか聞いていみます。
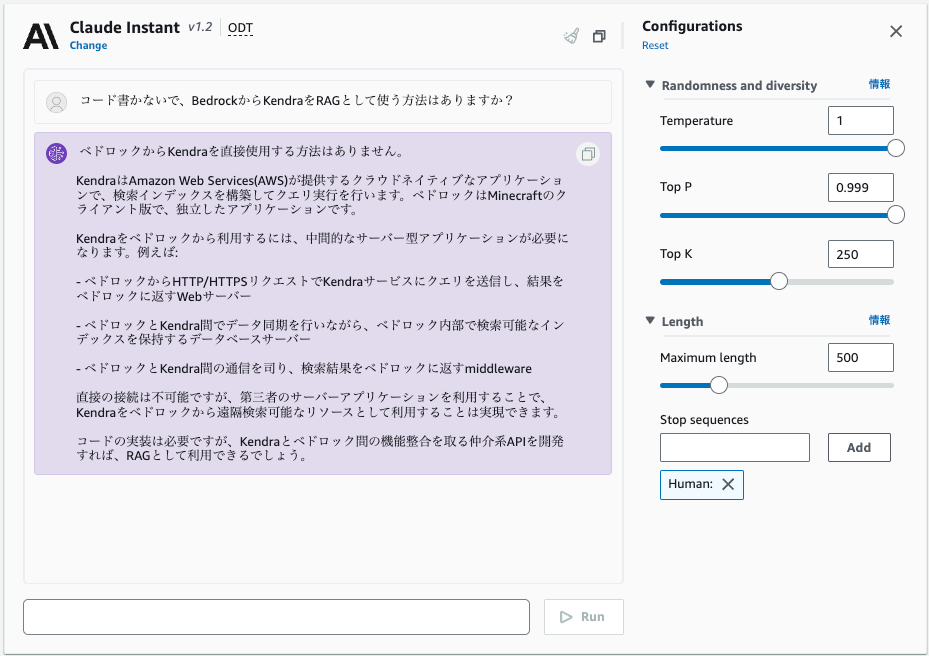
コードは必要みたいですね。
RAGなしでもしっかり答えてくれてそうです。スゴイ!!
Lambda から Bedrock を使う
いきなり Kendra 接続だと動かなかったときテンパるので、まず Bedrock から回答してもらう Lambda を作ってみます。
※参考サイトを元に書きましたが、全然 Python 書かないのでいろんなとこが適当です。
参考:
- https://dev.classmethod.jp/articles/terraform-lambda-deployment/
- https://zenn.dev/not75743/articles/7a7d3a2fc7e788
- https://www.insurtechlab.net/use_amazon_bedrock/
- https://dev.classmethod.jp/articles/invoke-bedrock-form-lambda-function/
Lambda を作成
モジュール分ける必要ない気がしますが、Kendraで分けちゃったので分けます。
※振り返ると絶対わけなくていいやつです。
# `terraform` で実行
# cd terraform
touch main.tf
touch variables.tf
mkdir -p modules/lambda
touch modules/lambda/main.tf
touch modules/lambda/variables.tf
touch modules/lambda/build-lambda.sh
chmod 755 modules/lambda/build-lambda.sh
コードはこちら
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
module "kendra" {
source = "./modules/kendra"
account_id = data.aws_caller_identity.current.account_id
region_name = data.aws_region.current.name
service_name = var.service_name
environment = var.environment
retention_in_days = var.retention_in_days
}
module "lambda" {
source = "./modules/lambda"
service_name = var.service_name
environment = var.environment
retention_in_days = var.retention_in_days
}
variable "service_name" {
type = string
default = "bks"
}
variable "environment" {
type = string
default = "stg"
}
variable "retention_in_days" {
type = number
default = 1
}
resource "null_resource" "run_script" {
triggers = {
file_hashes = jsonencode({
for fn in fileset("${path.module}/src", "**") :
fn => filesha256("${path.module}/src/${fn}")
})
}
provisioner "local-exec" {
command = "${path.module}/build-lambda.sh"
}
}
# -----------------------------
# Lambda layer
# -----------------------------
data "archive_file" "layer_zip" {
depends_on = [
null_resource.run_script
]
type = "zip"
source_dir = "${path.module}/build/layer"
output_path = "${path.module}/build/layer.zip"
}
resource "aws_lambda_layer_version" "bks_lambda" {
layer_name = "${var.service_name}_${var.environment}_bks_lambda"
filename = data.archive_file.layer_zip.output_path
source_code_hash = data.archive_file.layer_zip.output_base64sha256
}
# -----------------------------
# Kendra の結果を与えて Bedrock を呼び出す Lambda コード
# -----------------------------
data "archive_file" "bks_lambda" {
depends_on = [
null_resource.run_script
]
type = "zip"
source_dir = "${path.module}/build/function"
output_path = "${path.module}/build/function.zip"
}
resource "aws_lambda_function" "bks_lambda" {
function_name = "${var.service_name}-${var.environment}-bks-lambda"
filename = data.archive_file.bks_lambda.output_path
handler = "main.handler"
runtime = "python3.10"
source_code_hash = data.archive_file.bks_lambda.output_base64sha256
timeout = 10
layers = [aws_lambda_layer_version.bks_lambda.arn]
role = aws_iam_role.bks_lambda.arn
environment {
variables = {
KENDRA_INDEX_ID = var.kendra_index_id
}
}
}
# -----------------------------
# IAM
# -----------------------------
resource "aws_iam_role" "bks_lambda" {
name = "${var.service_name}-${var.environment}-bks-lambda"
assume_role_policy = data.aws_iam_policy_document.lambda_assume_role.json
}
# 信頼ポリシー
data "aws_iam_policy_document" "lambda_assume_role" {
statement {
actions = ["sts:AssumeRole"]
effect = "Allow"
principals {
identifiers = ["lambda.amazonaws.com"]
type = "Service"
}
}
}
# ポリシーとの紐づけ
resource "aws_iam_role_policy_attachment" "lambda_bedrock" {
role = aws_iam_role.bks_lambda.name
policy_arn = aws_iam_policy.lambda_bedrock.arn
}
# ポリシー
resource "aws_iam_policy" "lambda_bedrock" {
name = "${var.service_name}-${var.environment}-bks-lambda-policy"
policy = data.aws_iam_policy_document.lambda_bedrock.json
}
data "aws_iam_policy_document" "lambda_bedrock" {
version = "2012-10-17"
statement {
effect = "Allow"
actions = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
]
resources = [
aws_cloudwatch_log_group.bks_lambda.arn,
"${aws_cloudwatch_log_group.bks_lambda.arn}:*"
]
}
statement {
effect = "Allow"
actions = [
"bedrock:*",
]
resources = ["*"]
}
}
# -----------------------------
# log
# -----------------------------
resource "aws_cloudwatch_log_group" "bks_lambda" {
name = "/aws/lambda/${aws_lambda_function.bks_lambda.function_name}"
retention_in_days = var.retention_in_days
}
variable "service_name" {
type = string
}
variable "environment" {
type = string
}
variable "retention_in_days" {
type = number
}
#!/usr/bin/env bash
cd `dirname $0`
if [ -d build ]; then
rm -rf build
fi
# Recreate build directory
mkdir -p build/function/ build/layer/
# Copy source files
echo "Copy source files"
cp -r src/ build/function
# Pack python libraries
echo "Pack python libraries"
pip3 install -r requirements.txt -t build/layer/python
# Remove pycache in build directory
find build -type f | grep -E "(__pycache__|\.pyc|\.pyo$)" | xargs rm
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime', region_name='ap-northeast-1')
def handler(event, _):
# プロンプトに設定する内容を取得
prompt = event.get('prompt')
# 各種パラメーターの指定
model_id = 'anthropic.claude-instant-v1'
accept = 'application/json'
content_type = 'application/json'
# リクエストBODYの指定
body = json.dumps({
"prompt": f"\n\nHuman: ${prompt}.\\n\\nAssistant:",
"max_tokens_to_sample": 300,
"temperature": 0.8,
"top_p": 0.999,
"top_k": 250,
"stop_sequences": ["\\n\\nHuman:"],
"anthropic_version": "bedrock-2023-05-31"
})
# Bedrock APIの呼び出し
response = bedrock_runtime.invoke_model(
modelId=model_id,
accept=accept,
contentType=content_type,
body=body
)
# APIレスポンスからBODYを取り出す
response_body = json.loads(response.get('body').read())
# レスポンスBODYから応答テキストを取り出す
outputText = response_body.get('completion')
print(outputText)
Lambda Layer のための下準備です。
なんとなく venv を使っておきます。
# terraform/modules/lambda で実行
python3 -m venv venv # 一度だけでOK
source venv/bin/activate # 仮想環境を有効化(無効にした後は都度実行)
pip install boto3
pip freeze > requirements.txt
デプロイしてみましょう!
terraform init
terraform plan
# この段階では`terraform/lambda/build` にファイルできていません
terraform apply
# ここで yes とすると build にファイルが生成されてデプロイされるはずです。
成功しましたね!
AWS console から Lambda をテスト
せっかくなので、次何すればよいかきいてみました。
えっ、そんなことできるの?と思うくらいそれっぽい内容。
いやいや、RAG なしの Bedrock の言うことは鵜呑みにしてはいけません。アブナイアブナイ..(掌返し)
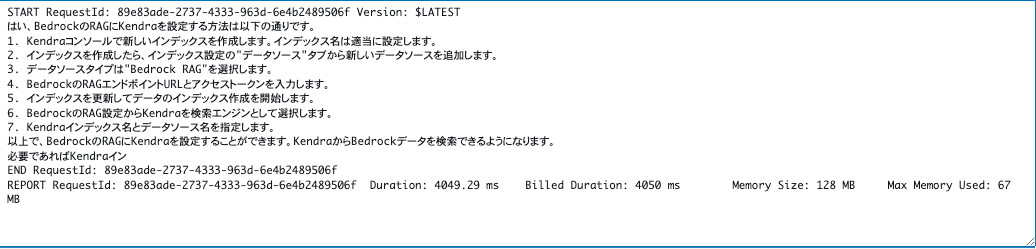
これで Bedrock を Lambda で呼び出すことはできることが確認できました!
Kendra で RAG して Bedrock を呼び出す
次は Kendra の情報を元に Bedrock に答えてもらいましょう!
Lambda コードを編集
参考:
参考サイトがすばらしいので早速コードに入ります。
コードはこちら
Kendra index id を使うっぽいので、module 間で受け渡しします。
touch terraform/modules/kendra/outputs.tf
output "kendra_index_id" {
value = aws_kendra_index.bks_kendra.id
}
--- a/terraform/modules/lambda/variables.tf
+++ b/terraform/modules/lambda/variables.tf
variable "retention_in_days" {
type = number
}
+
+variable "kendra_index_id" {
+ type = string
+}
timeout = 10
layers = [aws_lambda_layer_version.bks_lambda.arn]
role = aws_iam_role.bks_lambda.arn
+
+ environment {
+ variables = {
+ KENDRA_INDEX_ID = var.kendra_index_id
+ }
+ }
}
+# Kendra 利用のために追加
+resource "aws_iam_role_policy_attachment" "lambda_kendra" {
+ role = aws_iam_role.bks_lambda.name
+ policy_arn = data.aws_iam_policy.kendra_full_access.arn
+}
+
+data "aws_iam_policy" "kendra_full_access" {
+ arn = "arn:aws:iam::aws:policy/AmazonKendraFullAccess"
+}
data "aws_caller_identity" "current" {}
data "aws_region" "current" {}
module "kendra" {
source = "./modules/kendra"
account_id = data.aws_caller_identity.current.account_id
region_name = data.aws_region.current.name
service_name = var.service_name
environment = var.environment
retention_in_days = var.retention_in_days
}
module "lambda" {
source = "./modules/lambda"
service_name = var.service_name
environment = var.environment
retention_in_days = var.retention_in_days
kendra_index_id = module.kendra.kendra_index_id # 追加
}
import os
import boto3
import json
kendra = boto3.client('kendra')
bedrock_runtime = boto3.client('bedrock-runtime', region_name='ap-northeast-1')
def get_retrieval_result(query_text, index_id):
response = kendra.retrieve(
QueryText=query_text,
IndexId=index_id,
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
)
# Kendra の応答から最初の5つの結果を抽出
results = response['ResultItems'][:5] if response['ResultItems'] else []
extracted_results = []
for item in results:
content = item.get('Content')
document_uri = item.get('DocumentURI')
extracted_results.append({
'Content': content,
'DocumentURI': document_uri,
})
print("Kendra extracted_results:" + json.dumps(extracted_results, ensure_ascii=False))
return extracted_results
def handler(event, _):
# プロンプトに設定する内容を取得
user_prompt = event.get('user_prompt')
kendra_index_id = os.environ['WEB_HOOK_URL']
prompt = f"""\n\nHuman:
[参考]情報をもとに[質問]に適切に答えてください。
[質問]
{user_prompt}
[参考]
{get_retrieval_result(user_prompt, kendra_index_id)}
Assistant:
"""
# 各種パラメーターの指定
model_id = 'anthropic.claude-instant-v1'
accept = 'application/json'
content_type = 'application/json'
# リクエストBODYの指定
body = json.dumps({
"prompt": f"\n\nHuman: ${prompt}.\\n\\nAssistant:",
"max_tokens_to_sample": 600,
"temperature": 0.8,
"top_p": 0.999,
"top_k": 250,
"stop_sequences": ["\\n\\nHuman:"],
"anthropic_version": "bedrock-2023-05-31"
})
# Bedrock APIの呼び出し
response = bedrock_runtime.invoke_model(
modelId=model_id,
accept=accept,
contentType=content_type,
body=body
)
# APIレスポンスからBODYを取り出す
response_body = json.loads(response.get('body').read())
# レスポンスBODYから応答テキストを取り出す
return response_body.get('completion')
雑談ですが、書いてるうちに Terraform のモジュール間依存強すぎて構成失敗していることがわかりますよね。
はい、素直に分け方まちがえました。
本来なら直すとこですが、このまま進みます!
terraform plan
terraform apply
# OKなら yes
デプロイできましたね!
AWS console から Lambda をテスト
自分の手元では、Kendra で収集している情報に関連するものを聞いてみても正しい答えが返ってきました!
これで Kendra と Bedrock の呼び出しは完成です。
すごい整備されてて感動...!!
Slack と接続する
API Gateway の作成
最後は AWS で Slack botを作る作業になります。
構成としては API Gateway の REST API で Slack からのイベントを受けて Lambda にProxyします。
Lambda は後で改修するとして、まずは API Gateway 立てていきましょう!
参考:
コードはこちら
(やっぱモジュール分ける必要なかったか..とここでも公開、RTAあるある)
mkdir terraform/modules/lambda
touch terraform/modules/lambda/api_gateway.tf
# -----------------------------
# Slack からリクエスト受けて Lambda に流す API Gatway
# -----------------------------
resource "aws_api_gateway_rest_api" "bks" {
name = "${var.service_name}-${var.environment}-api"
endpoint_configuration {
types = ["REGIONAL"] # そんなに速度も求めないのでリージョナル
}
body = jsonencode({
openapi = "3.0.1"
info = {
title = "api"
version = "1.0"
}
paths = {
"/slack/events" = {
post = {
x-amazon-apigateway-integration = {
httpMethod = "POST"
payloadFormatVersion = "1.0"
type = "AWS_PROXY"
uri = aws_lambda_function.bks_lambda.invoke_arn
credentials = aws_iam_role.api_gateway_role.arn
}
}
}
}
})
}
resource "aws_api_gateway_deployment" "deployment" {
depends_on = [
aws_api_gateway_rest_api.bks
]
rest_api_id = aws_api_gateway_rest_api.bks.id
stage_name = var.environment
triggers = {
redeployment = sha1(jsonencode(aws_api_gateway_rest_api.bks))
}
}
data "aws_iam_policy_document" "api_gateway_policy" {
statement {
effect = "Allow"
principals {
type = "*"
identifiers = ["*"]
}
actions = ["execute-api:Invoke"]
resources = ["${aws_api_gateway_rest_api.bks.execution_arn}/*"]
}
}
resource "aws_api_gateway_rest_api_policy" "policy" {
rest_api_id = aws_api_gateway_rest_api.bks.id
policy = data.aws_iam_policy_document.api_gateway_policy.json
}
# -----------------------------
# IAM
# -----------------------------
resource "aws_iam_role" "api_gateway_role" {
name = "${var.service_name}-${var.environment}-apigateway-role"
assume_role_policy = data.aws_iam_policy_document.api_gateway_assume_role.json
}
resource "aws_iam_role_policy_attachment" "api_gateway_policy_logs" {
role = aws_iam_role.api_gateway_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AmazonAPIGatewayPushToCloudWatchLogs"
}
resource "aws_iam_role_policy_attachment" "api_gateway_policy_lambda" {
role = aws_iam_role.api_gateway_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaRole"
}
data "aws_iam_policy_document" "api_gateway_assume_role" {
statement {
actions = ["sts:AssumeRole"]
effect = "Allow"
principals {
type = "Service"
identifiers = ["apigateway.amazonaws.com"]
}
}
}
それではデプロイします!
terraform plan
terraform apply
# OK なら yes
動作確認してみると、エラー。。

event の中身吐き出して、 CloudWatchLogs でログ見てみるとリクエストボディに body フィールドがあるという構成のようです。
API Gateway 経由でテストできるように Lambda を書き直す
書き直します!
コードはこちら
書き直して動作確認します。
Lambda のコンソール画面からのテストも通るようにしたいので、ボディだろうがボディのbodyフィールドだろうが動くようにしてみます。
振り返りコメント
Slack連携する際には消すのでいらないかもですが、途中までローカルデバッグしやすかったです。
import os
import boto3
import json
kendra = boto3.client('kendra')
bedrock_runtime = boto3.client('bedrock-runtime', region_name='ap-northeast-1')
def get_retrieval_result(query_text, index_id):
response = kendra.retrieve(
QueryText=query_text,
IndexId=index_id,
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
)
# Kendra の応答から最初の5つの結果を抽出
results = response['ResultItems'][:5] if response['ResultItems'] else []
extracted_results = []
for item in results:
content = item.get('Content')
document_uri = item.get('DocumentURI')
extracted_results.append({
'Content': content,
'DocumentURI': document_uri,
})
print("Kendra extracted_results:" + json.dumps(extracted_results, ensure_ascii=False))
return extracted_results
def handler(event, context):
# プロンプトに設定する内容を取得
body = json.loads(event["body"]) if 'body' in event else event
print(body)
user_prompt = body.get('user_prompt')
kendra_index_id = os.environ['KENDRA_INDEX_ID']
prompt = f"""\n\nHuman:
[参考]情報をもとに[質問]に適切に答えてください。
[質問]
{user_prompt}
[参考]
{get_retrieval_result(user_prompt, kendra_index_id)}
Assistant:
"""
# 各種パラメーターの指定
model_id = 'anthropic.claude-instant-v1'
accept = 'application/json'
content_type = 'application/json'
# リクエストBODYの指定
body = json.dumps({
"prompt": f"\n\nHuman: ${prompt}.\\n\\nAssistant:",
"max_tokens_to_sample": 600,
"temperature": 0.8,
"top_p": 0.999,
"top_k": 250,
"stop_sequences": ["\\n\\nHuman:"],
"anthropic_version": "bedrock-2023-05-31"
})
# Bedrock APIの呼び出し
response = bedrock_runtime.invoke_model(
modelId=model_id,
accept=accept,
contentType=content_type,
body=body
)
# APIレスポンスからBODYを取り出す
response_body = json.loads(response.get('body').read())
answer = response_body.get('completion')
print(answer)
response = {
"statusCode": 200,
'body': json.dumps({"text": answer}, ensure_ascii=False)
}
return response
# ローカルデバッグ用
# print(handler({"user_prompt": "富士山ってなに?"}, None))
それではデプロイします!
terraform plan
terraform apply
# OK なら yes
無事答えが返ってくるようになりましたね!
Slackのサイトでアプリのためのキーを取得
ここからは参考にさせて頂いたサイトをもとにそのまま設定していきます。
まずここを開いて...
https://api.slack.com/apps
Create an App して...
From scratch 選んで...
アプリの名前を適当に bks にして、対象のワークスペース選択
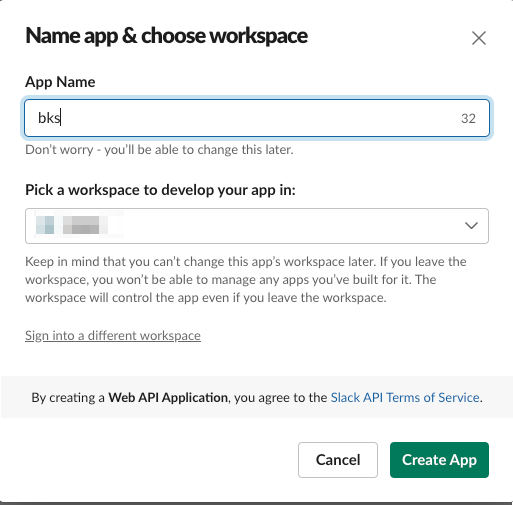
設定画面の左の「OAuth & Permissions」をクリック
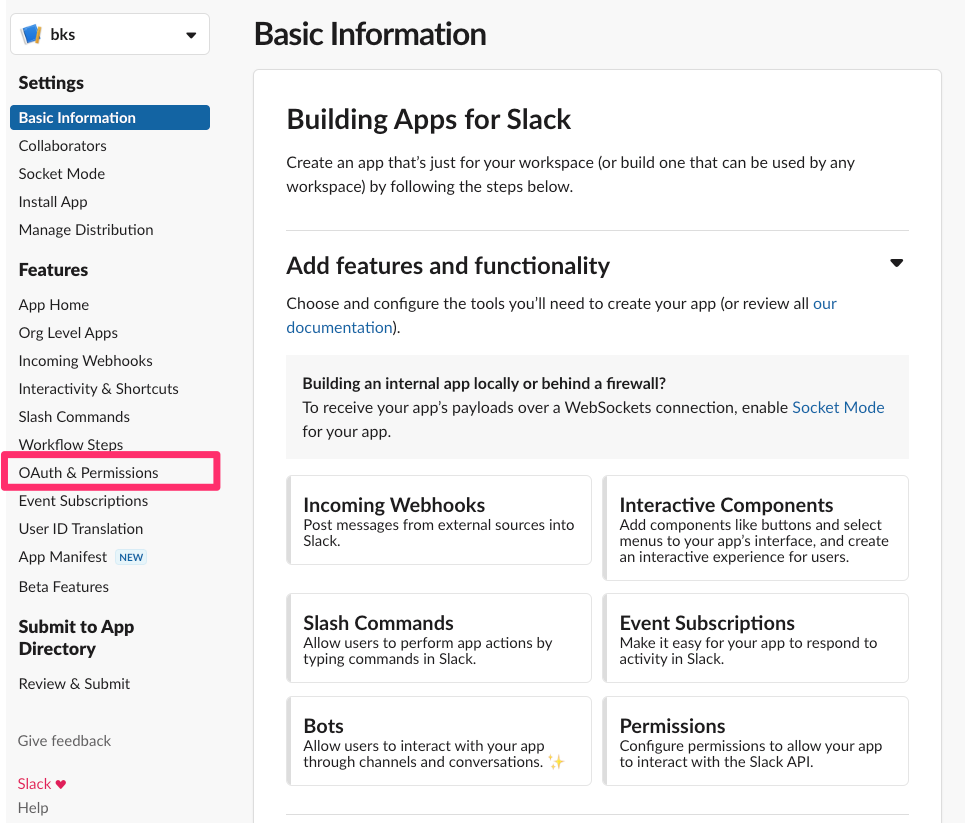
Scopes の Bot Token Scopes で下記を許可する権限として選択...
chat:writeapp_mentions:readchannels:history
Basic infromation に戻って...
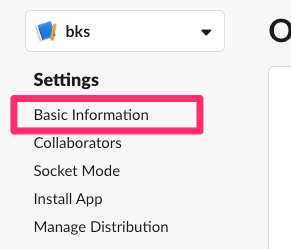
Install to Workspace

OAuth & Permissions で Bot User OAuth Token を控えて...
Basic infromation で App Credentials の Signing Secret を控える
これで Slack 単体の設定は終わりです!
Slack のイベントを受け取る設定を行う
次は Slack と AWS のサービス(API Gateway + Lambda)をつないでいきます!
まず Event Subscriptions を開いて...
Enable Events を On にして、Request URL に API Gateway のエンドポイントを設定します。
今回は https://xxxx.amazonaws.com/stg/slack/events のような URL になると思います。
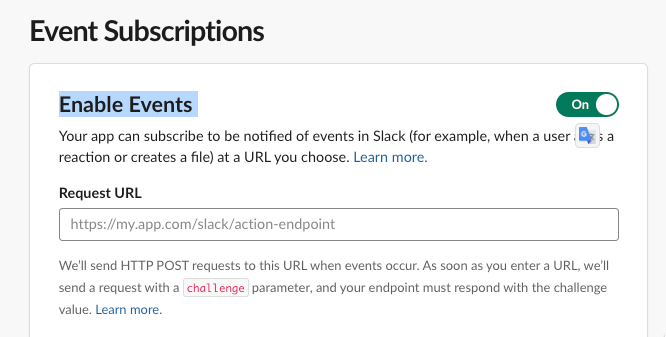
とここで、challenge パラメータが返って来ないと怒られるので一旦返すようにします。
def handler(event, context):
# プロンプトに設定する内容を取得
body = json.loads(event["body"]) if 'body' in event else event
print(body)
+ if "challenge" in body:
+ return {
+ "statusCode": 200,
+ 'body': body.get('challenge')
+ }
デプロイしましょう。
terraform apply
デプロイ完了したら、先程の Slack の設定画面の Request URL の横の Retry のボタンをおします。
Verified になりましたね!
イベントとして何を受け取るか選ぶとのことなので、メンションのイベントを受け取るようにしましょう。
Event Subscriptions の Subscribe to bot events で app_mention を選択して、右下の Save Changes をクリックします。
ここまで終わったらもう一度設定を保存しましょう(念のため)
左側の「Basic Information」を選択し、「Install your app to your workspace」を展開し、「Install App to Workspace」クリック、「許可する」をクリックしておきます。
Slack に追加して動作確認
ここで適当なチャンネルにアプリを招待して、メンションつけて話してみます。
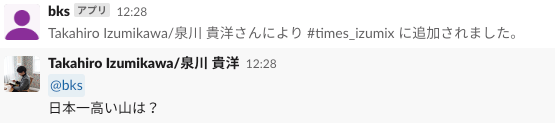
返ってきません。
あまりに返ってこなさすぎて、リーダーがスタンプで答えてくれました。ヤサシイセカイヤデ
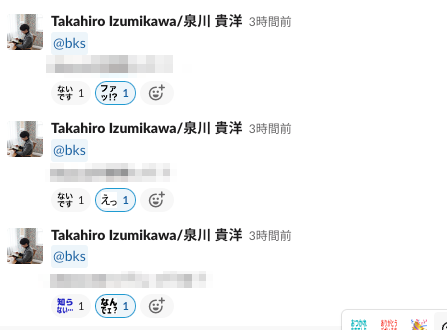
ログを見ると、 受け取りたい文字列はちょっと複雑なとこにあるみたいです。
また、 Slack Bot を調べてみるとイベントのリクエストに返信しても Slack 上で返信されないみたいです。
(Slack bot 5年くらい作ってないから bot 作成も新しい発見で一杯です。。。もっと色々作らないと...!!)
Slack からのリクエストに合わせてコードを修正
Slack からのイベントを受け取った後、postする必要があるので、ライブラリ追加しておきます。
# terraform/modules/lambda の venv 環境で実行
pip install requests "urllib3<2"
pip freeze > requirements.txt
受け取ったリクエストの解釈を変更し、チャット投稿を追加します。
※ぐちゃぐちゃなコードですがリファクタする時間もないのでそのまま載せます。ご容赦頂ければmm
本題と外れますが、ここで、Bedrockからエラーが返ってくるようになったため、Bedrockだけリージョンを変更しました。
発生したエラーはこちらです。
The provided model identifier is invalid
aws cli で確認したところ、名前もあっていて active でした。
aws bedrock list-foundation-models --profile terraform
AWS Console で chat を実行するとエラーが発生しました。
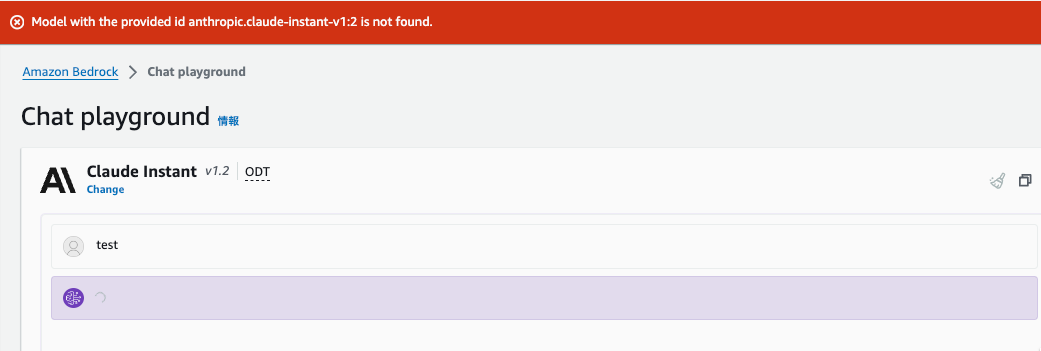
原因はわかりませんが、今すぐは復旧する術なさそうなので、この先はオレゴンのBedrockを使っています。
ただ、リージョン変更といっても、Lambda コード1行だけです。
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-west-2')
全然手間がありません。すごい。。
コードはこちら
import os
import boto3
import json
import requests
kendra = boto3.client('kendra')
bedrock_runtime = boto3.client('bedrock-runtime', region_name='us-west-2')
url = "https://slack.com/api/chat.postMessage"
# 控えてた slack の Bot User OAuth Token,ホントは environment で渡す方がよさそう!すみません。
token = "xoxb-xxxxxxxxxxxxx"
def get_retrieval_result(query_text, index_id):
response = kendra.retrieve(
QueryText=query_text,
IndexId=index_id,
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
)
# Kendra の応答から最初の5つの結果を抽出
results = response['ResultItems'][:5] if response['ResultItems'] else []
extracted_results = []
for item in results:
content = item.get('Content')
document_uri = item.get('DocumentURI')
extracted_results.append({
'Content': content,
'DocumentURI': document_uri,
})
print("Kendra extracted_results:" + json.dumps(extracted_results, ensure_ascii=False))
return extracted_results
def handler(event, context):
print("event is " + json.dumps(event))
# 3秒以内に返さないとリトライされるので無視する
# https://dev.classmethod.jp/articles/slack-resend-matome/
if ('X-Slack-Retry-Num' in event['headers']
and 'X-Slack-Retry-Reason' in event['headers']
and event['headers']['X-Slack-Retry-Reason'] == "http_timeout"):
return {
'statusCode': 200,
'body': json.dumps({'message': 'No need to resend'})
}
# プロンプトに設定する内容を取得
body = json.loads(event["body"]) if 'body' in event else event
print("body is" + json.dumps(body))
# 接続のためのコード(後で消す)
if "challenge" in body:
return {
"statusCode": 200,
'body': body.get('challenge')
}
# 必要な情報を取得
user_prompt = body.get('user_prompt') \
if 'user_prompt' in body else body['event']['text'].replace("メンションの文字列", "")
user_prompt = user_prompt.replace('\n', ' ')
print("user_prompt: " + user_prompt)
channel = body['event']['channel'] if 'event' in body else ''
event_ts = body['event']['event_ts'] if 'event' in body else 0
kendra_index_id = os.environ['KENDRA_INDEX_ID']
prompt = f"""\n\nHuman:
[参考]情報をもとに[質問]に適切に答えてください。
もし、答えのために利用した[参考]情報にURLがあれば、答えの後にリスト形式で返して下さい。
ただし、重複したURLは絶対に返さないようにして下さい。
[質問]
{user_prompt}
[参考]
{get_retrieval_result(user_prompt, kendra_index_id)}
Assistant:
"""
# 各種パラメーターの指定
model_id = 'anthropic.claude-instant-v1'
accept = 'application/json'
content_type = 'application/json'
# リクエストBODYの指定
body = json.dumps({
"prompt": f"\n\nHuman: ${prompt}.\\n\\nAssistant:",
"max_tokens_to_sample": 600,
"temperature": 0.8,
"top_p": 0.999,
"top_k": 250,
"stop_sequences": ["\\n\\nHuman:"],
"anthropic_version": "bedrock-2023-05-31"
})
# Bedrock APIの呼び出し
response = bedrock_runtime.invoke_model(
modelId=model_id,
accept=accept,
contentType=content_type,
body=body
)
# APIレスポンスからBODYを取り出す
response_body = json.loads(response.get('body').read())
answer = response_body.get('completion')
print(answer)
# 返信
header = {
"Authorization": "Bearer {}".format(token)
}
data = {
"channel": channel,
"text": answer,
"thread_ts": event_ts,
}
res = requests.post(url, headers=header, json=data)
print(res.json())
return {
"statusCode": 200,
"body": "OK"
}
さて、それでは Slack から質問してみます!
※中身は業務内容なので伏せてますmm
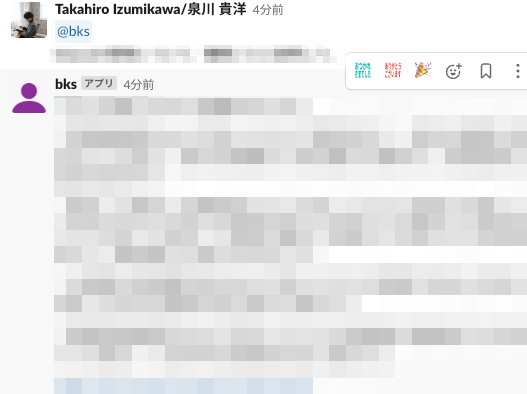
いい感じです!
Slack からのリクエストであることを検証
動作的には問題ないので完成といいたいところです。。
しかし、 API Gateway は何も認証なし、むき出し状態です。(結果はSlackにPostされるとはいえ...)
叩けば勝手に Slack に Post する可能性を秘めた爆弾システムなので、Slack からほんとにリクエストが来ているか検証しましょう。
Signing Secret を使います。
参考
‐ https://zenn.dev/t_kakei/articles/f61196a47f9b14
コードはこちら
参考のサイトでは AWS Secrets Manager に格納して呼び出す方法も解説してくれています。
実際に作る際はそうしましょう!
ここでは一旦 terraform.tfstate においておきます。
(環境変数で渡すとこだけ書きます)
environment {
variables = {
KENDRA_INDEX_ID = var.kendra_index_id
+ SLACK_API_SIGNING_SECRET = var.slack_api_signing_secret
}
}
※変更箇所のみ記載します
TIMESTAMP_DIFFERENCE_THRESHOLD = 60 * 5
def is_valid_request(headers, body):
slack_api_signing_secret = os.environ["SLACK_API_SIGNING_SECRET"]
try:
request_ts = int(headers["X-Slack-Request-Timestamp"])
current_timestamp = int(datetime.datetime.now().timestamp())
if abs(request_ts - current_timestamp) > TIMESTAMP_DIFFERENCE_THRESHOLD:
return False
signature = headers["X-Slack-Signature"]
message = f"v0:{headers['X-Slack-Request-Timestamp']}:{body}"
expected = create_hmac_hash(slack_api_signing_secret, message)
except Exception:
return False
else:
return hmac.compare_digest(expected, signature)
def create_hmac_hash(secret, message):
message_hmac = hmac.new(
bytes(secret, "UTF-8"), bytes(message, "UTF-8"), hashlib.sha256
)
return f"v0={message_hmac.hexdigest()}"
def handler(event, context):
print("event is " + json.dumps(event))
# 3秒以内に返さないとリトライされるので無視する
# https://dev.classmethod.jp/articles/slack-resend-matome/
if ('X-Slack-Retry-Num' in event['headers']
and 'X-Slack-Retry-Reason' in event['headers']
and event['headers']['X-Slack-Retry-Reason'] == "http_timeout"):
return {
'statusCode': 200,
'body': json.dumps({'message': 'No need to resend'})
}
# プロンプトに設定する内容を取得
body = json.loads(event["body"])
print("body is" + json.dumps(body))
# Slack からの通信か検証
if not is_valid_request(event["headers"], event["body"]):
print("Slack リクエストの検証に失敗しました")
return {
'statusCode': 200,
}
終わりです!それでは Slack から質問してみます!
先程同様応答がかえってきましたね!
これでKendra で RAG した Bedrock に問い合わせる Slack bot 完成です!
まとめ
利用した主なサービス
色々使った気がしますが、主要なものは4つだけです。
シンプル...!!
- API Gateway
- Lambda
- Kendra
- Bedrock など
AWS で生成系 AI ツール作るのってどう?
AIとか何にも知らなくても、ちゃんと使えそうなツールがお手軽に作れるのがすごいです。
セキュリティとコンプライアンスが業務利用にフィットしているということがモチベーションでしたが、機能的にも使いやすくて、モデルの変更や data source の拡張が手軽なところも魅力だと思います。
今後の利用について
検証環境で立てたので、このままみんなに触ってもらい、data source 増やしたりモデル変えたり、パラメータ変えてみて、フィットしそうというフィードバックがもらえたら、本運用環境に移行して本格的に使っていこうと思います。
作ってみて...
簡単とはいえ、普段使わないものばかり使ったので、いろんなとこで躓いて超大変だったーー
※意外と Slack bot にハマったかも...
作りもやばやば...
変にモジュールつくっちゃったり、terraformという唯一のディレクトリつくっちゃったり、、Secret 管理もしなきゃ、、エラー検知できるようにSNSと連携しなきゃ、、、
何より肝心のpythonコードもやばやばなので忘れる前に整理します。。