この記事はフロムスクラッチ Advent Calendar 2016の9日目の記事です。
筋トレ大好き!プログラミング大好き!
あれ?そうすると、、、
筋肉系カレンダーにも投稿しないと、自称筋肉プログラマー失格なのでは!!
と本気で悩んでいます。
mixです。
最近の事件
そう!AWS、ATHENAが発表されました!
Presto信者としては血湧き肉躍るニュースです!
簡単に説明すると、Prestoというfacebookの作ったフレームワークを
AWSで__サーバーレスに使える__という画期的かつ凄すぎる新サービスです!
カレンダー2日連続になっていますが、
AWSの回し者とかじゃないです。。。(>_<)
そもそもPrestoってなんじゃい??
下の説明を正確にしていくと、
分類も定義によったり、
テラバイト処理には対応する大規模構成が必要になったり、
クエリがSQLなのはPrestoの特徴だったりします。が!
難しい説明は頭脳系エンジニアに任せます!
細かいところは__筋肉で感じて下さい!__
端的かつ__極端に__いうと、
テラ単位データを、オンラインで爆速に集計、検索できる基盤です。
分類的にはhadoop、sparkに代表される分散処理の一つです。
の中でも!分散クエリエンジンに分類されるPrestoは、
__SQL投げる感覚で分散処理をできちゃうでござる__系基盤なんです。
hiveとかご存知の方、使い方は同じです。
ただし中身はhadoopキッカーじゃなくて自前の実装を持っています。
SQL投げるって、、、対象はRDB?
なんと、実はコネクタ(catalogとよく呼びます)さえあれば、
MySQLでもS3でも、__複数の結合でも__なんでも可能です。画期的!!
現在、メジャーなカタログはあります。
作ることも可能ですが、
結構時間かかりそうですので気軽に作る感じではありません。
さて、結合可能と書きましたが、使ってみた感じ、
異なるデータソースのデータを結合すると信じられない位遅くなります。
あまり詳しく調査していませんが、
気軽に使うならデータソースは1種類が良いです。
大量データを扱うと思いますので、S3とかファイルサーバになると思います。
記事でどこまで書くかの苦悩
・・・hadoopとかsparkとかhiveとか説明したい、but長いと読みにくい。。。
いろんな人が違いを書いてくれているから興味あればぜひググってね。
じゃあATHENA使ってみるか、と思ったのですが、めっちゃGUIあるし
すでに記事あったので、どうしよう。。。
macに立てる、、のも記事あるし、、、書いてる通りで動きますし。
じゃあAWSのEMRにPresto立てて使ってみましょう。
で終わるとAWSのドキュメントみたいになるので、
rubyで外部から接続するとこまで行きましょう。
想定読者
- 分散処理やってみたい人
- facebookのフレームワークなんで(=・ω・=)キリッ!をしてみたい人
- オンラインで大量のデータをある程度リアルタイムに集計する要件を持っている人
- Prestoってなんだかかっこいい響き!と思って読んでくれている人
やってみよう!
- ほんとはAws cliでコマンド投げて作るのですが、今回は画面で
- 設定も詳細設定とかなしでシンプルにします
- セキュリティも適当にいきます。サンプルなので。
大丈夫!使って問題なければOkですし、
問題あればきっとあなたは調べてカスタマイズして好きな構成を作れるようにいつの間にかなります。
※セキュリティは別途調べてみて下さい。
まずはAWSのアカウントを作りましょう
これはすみません。
ご自身で登録してアカウントを用意してください。
S3にバケット作ります
下記の記事でやってみて下さいね★
http://qiita.com/idobee/items/416b81982944f6068f47
EMRクラスタを作成します
EMR画面に移動
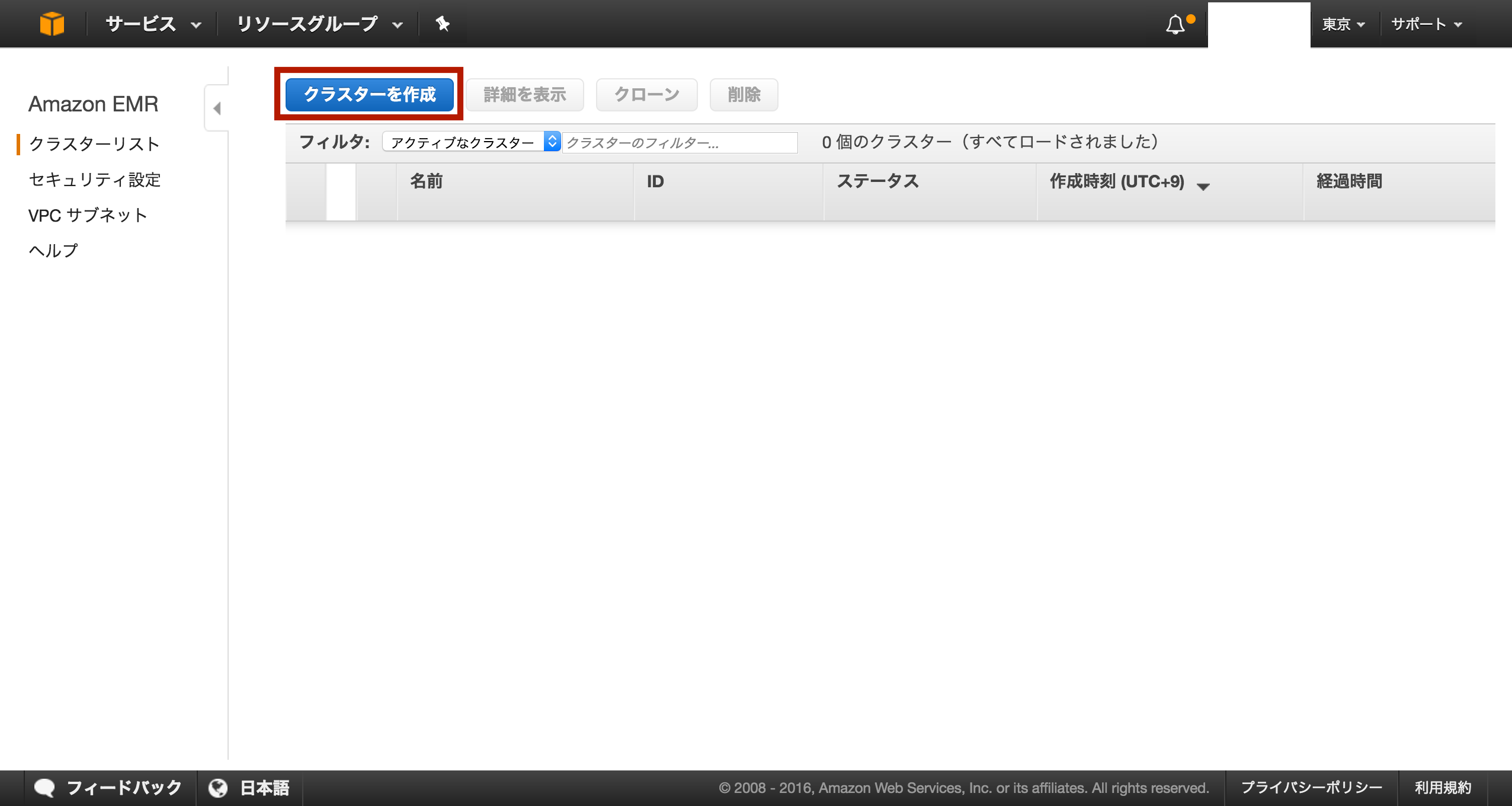
「クラスターを作成」を選択して登録
キーペアはEC2のサービスのサイドメニューに作るところあるので作ってpemファイルを
ダウンロードしておきましょう!
SSH接続で使います!
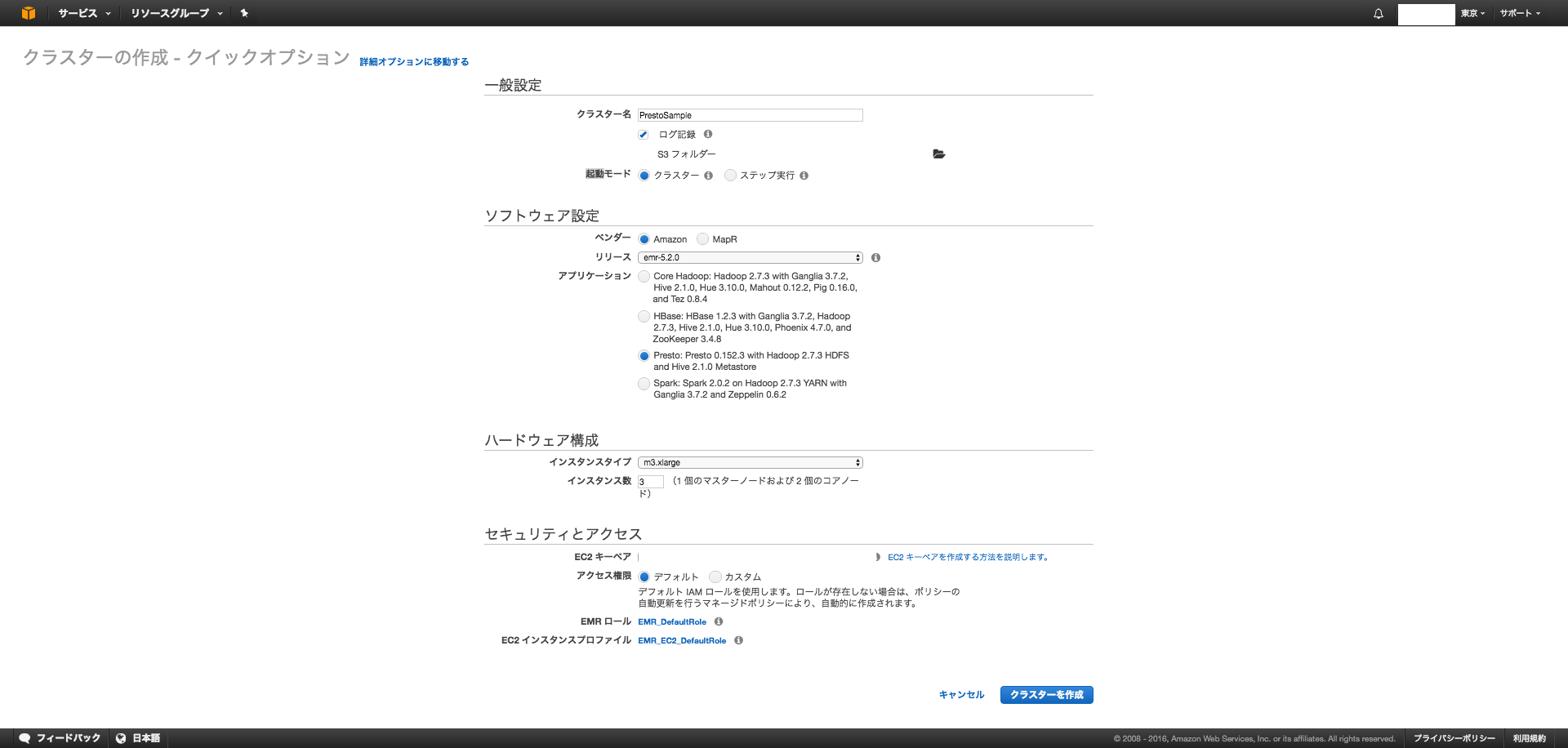
開始中になるので待ちます
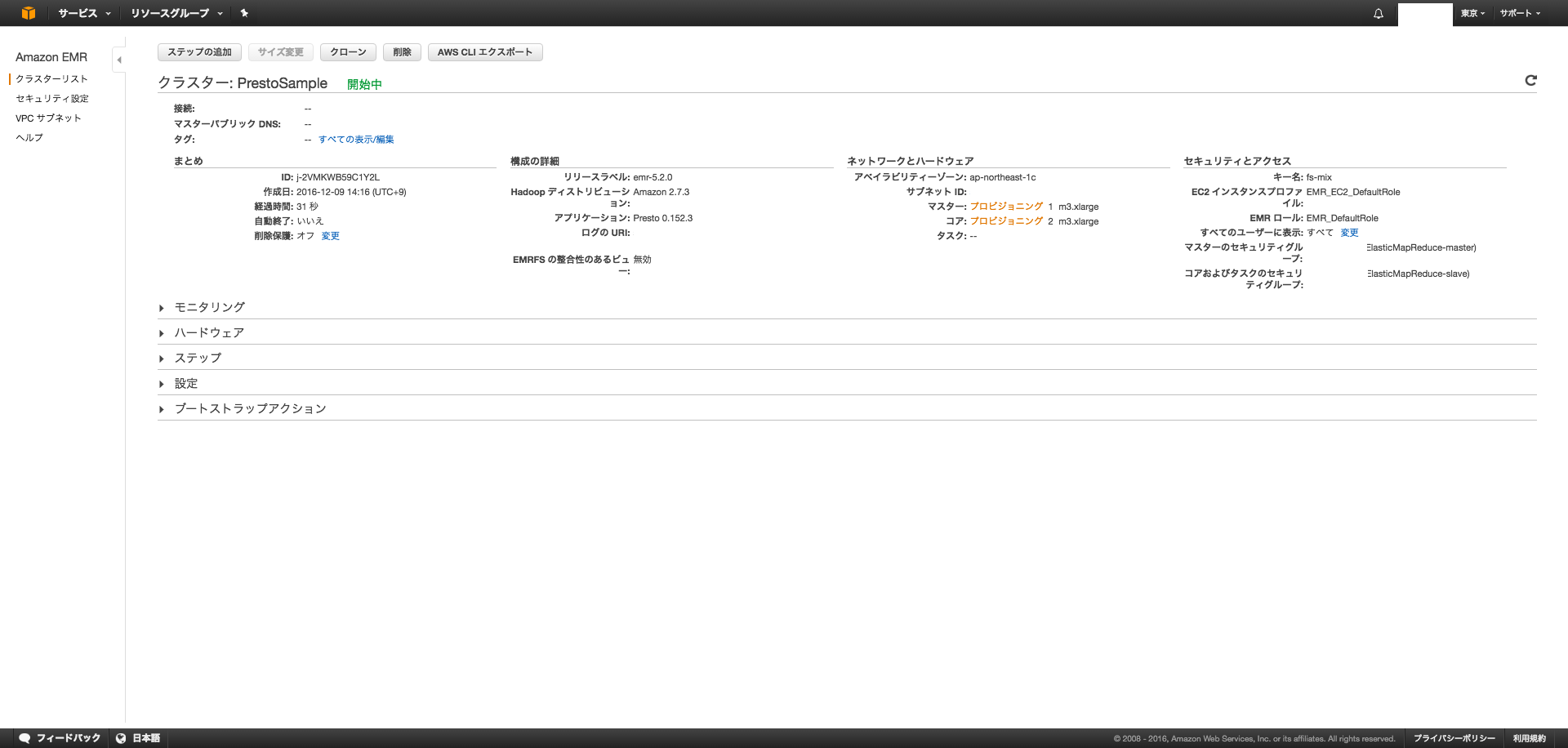
マスターのセキュリティグループの設定
忘れてました。。。先にやっとく方法もあったかもです。
マスタノードのセキュリティグループをクリックして、
①インバウンド→編集→ルールの追加→8889ポートをMYIPに開放します。アプリからの通信用。
①インバウンド→編集→ルールの追加→22ポートをMYIPに開放します。SSH用。
SSHで接続!
キーペアの権限適切に設定して下さいね。
例) sudo chmod 600 ~/.ssh/hoge.pem
EMRのクラスター情報の画面の
「マスターパブリック DNS」の右端にSSHというリンクがあるはずなのでクリックして下さい。
そうするとコマンドの例が載っています。
例)ssh -i ~/.ssh/hoge.pem hadoop@ec2-xx-xxx-x-xx.ap-northeast-1.compute.amazonaws.com
つながりました!!
ターミナルでそのままPresto体験
Prestoクライアントから操作してみます!
$ presto-cli
presto>show catalogs;
Catalog
---------
hive
system
(2 rows)
Query 20161209_053659_00001_5e39d, FINISHED, 1 node
Splits: 1 total, 1 done (100.00%)
0:02 [0 rows, 0B] [0 rows/s, 0B/s]
デフォルトではhiveのカタログがあるのでhiveで作成したデータを操作できます。
ただ、今はHDFSにもS3にもデータがありません。
S3にファイルをおいてhiveからアクセスできるようにしましょう。
S3にファイル配置
作ったバケットに以下のサンプルファイルをアップロードします。
1000,mix
1,mix2,fs
2,mix3,test
33,fromscratch,mi
333,bdash,aaa
適当にデータ増やしてみて下さいね。
hiveでテーブル作成
じゃあ置いたファイル読み込むテーブルを作成しましょう。
$ hive
これでhiveが起動します。
ファイルおいたS3の階層を使います。
今回は「バケット名/presto」以下においたとします。
CREATE EXTERNAL TABLE sample
(
id INT,
first_name STRING,
last_name STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
LOCATION 's3n://バケット名/presto';
S3に実体を持つhiveテーブルができました。
実運用ではパーティションとかつけると良いです★
例) PARTITIONED BY (ts INT)
hiveでselectしてみよう!
hive> select * from sample;
OK
1000 mix NULL
1 mix2 fs
2 mix3 test
33 fromscratch mi
333 bdash aaa
Time taken: 2.0 seconds, Fetched: 5 row(s)
prestoでselectしてみよう!
$ presto-cli
presto> select * from hive.default.sample;
id | first_name | last_name
------+-------------+-----------
1000 | mix | NULL
1 | mix2 | fs
2 | mix3 | test
33 | fromscratch | mi
333 | bdash | aaa
(5 rows)
Query 20161209_062527_00022_5e39d, FINISHED, 1 node
Splits: 2 total, 2 done (100.00%)
0:03 [5 rows, 63B] [1 rows/s, 22B/s]
カタログ.スキーマ.テーブルと設定します。
presto-cli立ち上げの際にカタログなどを設定しておくこともできます。
prestoくんの力を見るためにはデフォルトのしょぼいマシンじゃだめですね。
本番は作るテーブルもORC形式にして、圧縮すると高速になります。
ま、今回はサンプルなので。
最後にrubyから接続してみよう!
presto-clientを使うと簡単です。
require 'presto-client'
client = Presto::Client.new(
server: 'パブリックIP:8889',
catalog: 'hive',
schema: 'default',
user: 'ec2-user', #or hadoop
time_zone: 'US/Pacific',
language: 'English',
#http_debug: true,これ設定すると結構ログが出る
)
# 全テーブル名表示
columns, rows = client.run("show tables")
rows.each {|row|
p row # row is an array
}
# sampleテーブルの全件表示
columns, rows = client.run("SELECT * FRoM sample")
rows.each {|row|
p row # row is an array
}
javaもクライアントあるので使ってみて下さい。
あっさり動きます!
まとめ
な、長くなってしまった。。。
すみません!!!!
最後に、Prestoは適切にクラスターを構成すると爆速になります。
大量データの処理に対して、富豪的アプローチが可能なんです。
例えば1テラのデータを
RedShift、Bigquery、RDBなどで爆速に処理したい!
といっても限界があります。それはどうしようもない限界です。
逆に、Prestoは使うメモリ量に耐えきれて、
更にCPU性能の高いサーバーを与えれば与えるほど、純粋に高速化できます。
プロテインを飲んで筋トレすればするほど強くなる
筋肉プログラマーのために作られたフレームワークといっても過言じゃないですね!
(これが言いたかった!)
結論
こじつけてごめんなさい。
メリクリまであと16日!