「愚者は経験に学び、賢者は歴史に学ぶ」はビスマルクさんの言葉ですが(ググった)、愚者である私は当然経験から学んでおります。経験から学ぶととかく失敗が多いのですが(これも経験から学んだ)、今回は私が5年くらい取り組んでいるmmcが失敗した話でもしたいなと思います。
はじめに
静的型付けであらずんばプログラミング言語であらず 世はまさに大静的型付け時代なわけですが、動的型付け言語が静的型付け言語と同じとかそれ以上の速度で動作したらどうでしょう?実はそのような言語処理系は既に存在し、Stalinなどはその代表です。まあ、静的型付けがもてはやされるのはプログラムの実行速度だけではないので変わらないかもしれませんが。
mmcもStalinと同じようにとにかくどんなにコンパイル時間がかかっても(ここ重要)高速なコードを生成するという目標で開発したRubyからCに変換するトランスレータです。正確には入力はmrubyのバイトコードでパーサはmrubyの物を使っているのでコード生成だけを行います。なかなか成果良い成果が出て、aoベンチでRuby版がC版より少し速い速度が出ました。CRubyと比べて100倍速くらいでしょうか。
mmcの概要
mmcのソースコードはここに置いてあります。
https://github.com/miura1729/mruby-meta-circular
mrubyのmrbgemの形を取っています。バイトコードのフォーマットが変わってしまったのでmrubyのバージョン1でなければ動きません。ちなみに私の作ったmrubyのJIT (https://github.com/miura1729/mruby )でも一応動きますが、どこかライトバリアの入れ方を間違えたのかたまに変なエラーが起きたりコアを吐いたりします。ちゃんと動くと3倍くらい速いようです。
mmcの内部構造について詳しくは書かないです。興味のある人はこの辺を見てください
-
謎の集まりのためのスライドです。メンバーがつよつよな人たちなのでわかりやすさより情報を詰め込むことに注力しています。比較的初期の型のプロファイルの実装をまとめてあります。
https://docs.google.com/presentation/d/1VKrIMVkSK6kkPHkuDM2GQscnXicvhAQh7LdNjncLDYo/edit?usp=sharing -
2019年に行った名古屋RubyKaigi04で発表したスライドです。Ruby特有の機能に型をつける方法を説明しています。重箱の隅をつつくようなスライドです。
https://docs.google.com/presentation/d/1aa2iYRtkiEqDSYI5eXcWc1KqhLvVCYMxmJ1oUl_kKp0/edit?usp=sharing -
2020年のRubyKaigi takeoutのスライドです。エスケープ解析について説明しています。
https://docs.google.com/presentation/d/1yQUqiMP2fIDyQcbUSEUBBGX3ehd_MN9OinAXj6dsK4Y/edit?usp=sharing -
エスケープ解析のドキュメントです
https://qiita.com/miura1729/items/86018639e649089fa7dc
とはいえ、全く説明しないと話が進まないので、簡単な説明をします。
mmcの概要
mmcは抽象解釈と呼ばれる手法で型やエスケープの情報を得ます。抽象解釈はプログラムで扱う値を実行可能なレベルまで抽象化した上で実際にプログラムを実行してプログラムの情報を得る技法です。mmcはCにトランスレートする前にプログラム全体について抽象解釈を用いて、変数の型とエスケープするかの情報を得ています。
型の情報を得る
mmcでは抽象解釈の際には変数の型のみをデータとして扱います。たとえば、mrubyで1 + 1は次のように実行されます。
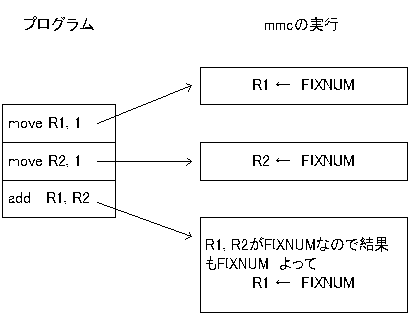
つまり基本的に値を型だと見て実行しているわけです。しかし、例外があって例えばシンボルなどは型として見るより実際の値で実行した方が良いので値をそのまま使っています。そうするしかないのですが、このあと明らかになりますが、これが失敗の原因の多くを占めます。
こんな感じRubyにも関わらず簡単そうな所はほぼすべて、evalとかsendとか可変長引数とか明らかに無理でしょって思われる所もそれなりにコンパイル時に型がわかります1。
エスケープの情報を得る
Rubyが遅いのは、
- コンパイル時に型が分からないのでメソッド呼び出しのたびにメソッドを検索しないといけないこと
- オブジェクトの動的生成を多用するためのアロケーションやGCのコストが大きい。また、メソッド呼び出しやGCのために型を表すタグをきちんと管理する必要がある。
の2つの理由です(今回分かった)。前者は前の節で説明した抽象解釈による型情報の取得で解決しています。ほとんどの場合一切の型チェックなしでメソッド呼び出しを行えます。
一方、後者を解決するための中心となるのがエスケープの情報で、それを得るための方法がエスケープ解析です。
エスケープの情報とは生成されたオブジェクトがどこで参照されているかの情報です。特にオブジェクトを生成したメソッドの外で参照されているかの情報は重要です。もし、メソッドの外で参照されていなければそのオブジェクトをメソッド内でしか寿命の無いスタックフレームに割り付けることが出来るからです。
オブジェクトをスタックフレームに割り付けることが出来るとヒープから割り付けることに比べて高速だしGCも関係なくなるなど高速化に効果があるのですが、Rubyの場合さらにうれしいことがあります。それは、データ構造に型に関するタグが必要なくなる(box化しなくてもよくなる)ことです。一般的にRubyでは例え静的に型が分かっていてもGCが混乱しないように型のタグをつける必要があるのですが、オブジェクトをスタック割り付けすればGCからは辿れないようにすることで型タグが必要なくなります。型タグを外したり付けたりする処理はそれなりに重くなります。
一方、このように型タグがあるデータ構造と無いデータ構造が混在する状況は影の面もあります。つまりこれも失敗の一因なのです。
mmcの失敗
逆説的ですが、mmcを始めたそもそもの目的の一つが派手な失敗をして次に生かす教訓を得ると言うものなので失敗すると言うのは良いことではあるのですが、いくつか失敗をしました。これらに付いて説明したいと思います。
Optcarrotが動かない
Rubyの標準的なベンチマークとして、遠藤侑介さんが作成したOptcarrot ( https://github.com/mame/optcarrot )が挙げられます。これはファミコン(NES)のエミュレータでベンチマークとして使うと何FPSで動作したか表示されると言うものです。このプログラムは面白いことをしているのに移植性が高いという優れ物で、いろいろなRuby処理系で動かすことが出来、うちの処理系では○○FPS出たとみんな楽しそうです2。
しかし、mmcでは動かすことが出来ません。なぜでしょう?
@opcode = fetch(@_pc)
@_pc += 1
send(*DISPATCH[@opcode])
@ppu.sync(@clk) if @ppu_sync
Optcarrotは6502 CPUのインタープリトをしているのですが、これがその心臓部です。DISPATCHは命令列のリストでこんな感じで作ります。
DISPATCH = []
def self.op(opcodes, args)
opcodes.each do |opcode|
if args.is_a?(Array) && [:r_op, :w_op, :rw_op].include?(args[0])
kind, op, mode = args
mode = ADDRESSING_MODES[mode][opcode >> 2 & 7]
send_args = [kind, op, mode]
send_args << (mode.to_s.start_with?("zpg") ? :store_zpg : :store_mem) if kind != :r_op
DISPATCH[opcode] = send_args
else
DISPATCH[opcode] = [*args]
end
end
end
# load instructions
op([0xa9, 0xa5, 0xb5, 0xad, 0xbd, 0xb9, 0xa1, 0xb1], [:r_op, :_lda, :alu])
op([0xa2, 0xa6, 0xb6, 0xae, 0xbe], [:r_op, :_ldx, :rmw])
op([0xa0, 0xa4, 0xb4, 0xac, 0xbc], [:r_op, :_ldy, :ctl])
# store instructions
op([0x85, 0x95, 0x8d, 0x9d, 0x99, 0x81, 0x91], [:w_op, :_sta, :alu])
op([0x86, 0x96, 0x8e], [:w_op, :_stx, :rmw])
op([0x84, 0x94, 0x8c], [:w_op, :_sty, :ctl])
# transfer instructions
op([0xaa], :_tax)
op([0xa8], :_tay)
op([0x8a], :_txa)
op([0x98], :_tya)
# flow control instructions
op([0x4c], :_jmp_a)
op([0x6c], :_jmp_i)
op([0x20], :_jsr)
op([0x60], :_rts)
op([0x40], :_rti)
op([0xd0], :_bne)
このような行がさらに80行くらい続く
sendメソッドは第一引数のシンボルと同じ名前のメソッドを呼び出すというメソッドなので、
send(*DISPATCH[@opcode])
に型をつけるのは不可能と思われるかもしれません。しかし、mmcでは力技で型をつけています。その方法とは
- シンボルは名前が異なれば違う型として扱う
- 配列のインデックスごとに型情報を持たせる
これらの方法により、sendメソッドに渡される第一引数(呼び出すメソッド名)の完全なリストが得られ、このsendの型が(おそらく巨大なユニオン型として)得られます。しかし、この力技はタダではありません。極めて巨大なデータ構造(型の表現)を振り回すことになり、事実上プログラムが終わらないかメモリオーバーフローを起こしてしまいます。
プログラムコードが膨れ上がる
C言語版より速い速度を達成することが出来たaoベンチなのですが、生成したCコードとオリジナルのC版のコードの行数を比べてみましょう。
|C版 | mmc版|
|:-----|-----:|-----:|
|行数|343|4547|
|文字数|8454|152175|
このように10倍以上に膨れ上がります。合理的な理由で膨れ上がるのならまだ分かるのですが、次のように同じようなものを沢山定義しているのです。
struct cls2_104 {
mrb_float2 v3010; /* @x */
mrb_float2 v3011; /* @y */
mrb_float2 v3012; /* @z */
};
struct cls2_106 {
mrb_float2 v3010; /* @x */
mrb_float2 v3011; /* @y */
mrb_float2 v3012; /* @z */
};
struct cls2_107 {
mrb_float2 v3010; /* @x */
mrb_float2 v3011; /* @y */
mrb_float2 v3012; /* @z */
};
これはRubyの
class Vec
# include Inline
def initialize(x, y, z)
@x = x
@y = y
@z = z
end
def x=(v); @x = v; end
の部分のCに変換した物の定義で、RubyのオブジェクトがCの構造体というとても軽い定義になるので良い話なのですが、同じような定義が複数並んでしまいます。これは、インスタンス変数の型が普通のFloatと具体的な値を持つFloatのリテラルのユニオンになっているからです。もちろん、普通のFloatとリテラルのユニオンなら普通のFloatにまとめればいいような気がするのですが、どうもそれだとうまくいかないことがあるようです。
結局、あまりにも複雑になり過ぎて私の手に負えなくなっているわけです。
分割コンパイル出来ない
プログラム全体を抽象実行して全部の変数・メソッドの型を確定してコンパイルするので、当然プログラムが全部そろっていなければコンパイルできません。ちょっとプログラムを変更するとただでさえ長い時間のかかるコンパイルを初めからやらないといけません。
抽象実行を高速に実行するために部分評価したコードを生成するとか考えたのですが、ほとんど作り直すレベルの工数が必要そうです。
今後に向けて
CRAY1については、そういう心配はなかった。プログラムの目標がそれほど野心的ではなかったからである。クレイが最初にしたことは、8600で目標としていた8ナノ秒のクロック速度を12ナノ秒に下げたことだった。 「チャールズ・マーレー著 小林達監訳 スーパコンピュータを創った男」
このようにmmcの一定の成果と限界が見えた所で新しいプロジェクトを考えています。新しいプロジェクトの目標はつぎの2つです。
- Optcarrotを動かして、他の処理系の開発者と○○FPS出た話でキャッキャウフフする
- 抽象解釈に基づくプログラム解析の結果に基づく最適化は、強力で強烈な万能感をもたらすので引き続き採用する
この2つを同時に満たす方法ですが、今の所次のような方針を考えています。
-
mmcはAOTであったが、次のプロジェクトではJITにする。つまり、コンパイル時・実行時に中間表現、コンパイラが常に存在するようにする
-
型解析やエスケープ解析に完璧を求めない。時間がかかりそうだと判断したら躊躇せずANYに型付けする。一方、実行時に時間がかかることが判明したら改めて型解析等を行う
-
2の理由から生成コードの入れ替えが頻発することが考えられる。そのためあえてネイティブコードではなくバイトコードインタプリタを採用する。これでコード領域をGCしたりするのが色々やりやすくなることが期待できる。
-
型解析やエスケープ解析の結果を生かすためにバイトコードの命令は非常に低レベルな物になる。普通はバイトコード命令は型チェックなどが命令の機能として入るが、それらは必要に応じて別の命令として生成する。命令の組合わせによってはコアを吐くかもしれないがそれはコンパイラの責任。
-
mmcでは非常にリッチな内部表現を用いて、たとえばあるレジスタがどこでその値を代入されたか(SSAを用いているので一部の例外を除いてそれは1箇所)、どこで参照されているか、今後参照されうるのか などの情報が簡単に得られるようになっているが、内部表現を構築するのがとても重い。これを軽くする方法が求められる。ここ数カ月悩んでいるのがここ
と感じです。前人未到の挑戦は続く。
-
余談ですが、どうしても型がつけられないプログラムも存在します。https://github.com/ruby/ruby/blob/master/benchmark/app_lc_fizzbuzz.rb まあ、これに型がつけられたら宇宙の法則が乱れるけど。 ↩
-
前作mrubyのJITでは動かすことが出来てmrubyの10倍くらいの速度が出たとtwitterに記録があります。ベンチマークの結果を見る限りCRubyとかと同じくらいの速度でしょうか ↩