はじめに
これは モチベーションクラウドシリーズ Advent Calendar 2019 11日目の投稿です。
今年の10月にリンクアンドモチベーションへ中途入社して、2ヶ月ちょっとたちました。
久しぶりに関わるサービスが変わったのですが、システム全体を割と細かく理解したいというタイプなので、日々開発しつつ知識を蓄えようと奮闘しています。
オンボーディングでは、インフラ構成を教えてもらったり、マニュアルを読んだり、シナリオテストを実施したり、ソースコードの概要を説明してもらったり・・・色々やってもらいましたが、今回はデータ構造まわりを理解するために自分なりに実施したことについてまとめたいと思います。
データ構造を理解するために、やったことや使ったツール
主要データの構造と関連を把握する
実DBを見たり、ER図だといきなり詳細すぎて、どこから手を付けていいか結構悩みます。
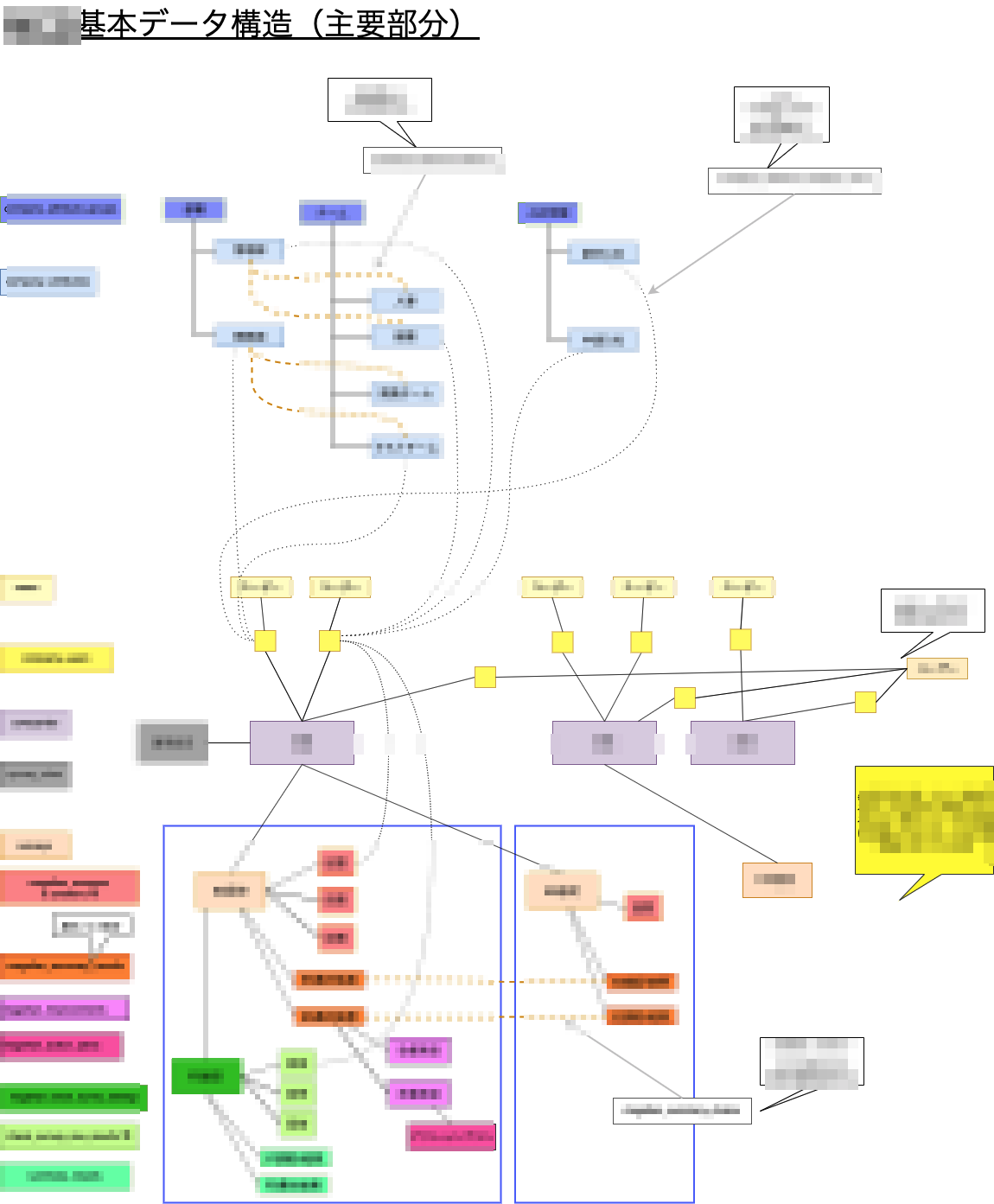
はじめは主要部分のみに絞り、データの親子関係や多重度について、データ構造図を書くと理解が深まります。
気をつけている点は下記です
- 一番左にテーブル名を書いていて、右側の実例データと色を揃えて関連付ける
- 実例データ例は、できるだけ具体的な名称を書いて、イメージしやすいものにする
- テーブルの網羅性や、全てのリレーション・多重度の正確性はある程度諦めて、主要部分がイメージできるようにする
モザイクだらけですが実際に作った図です。
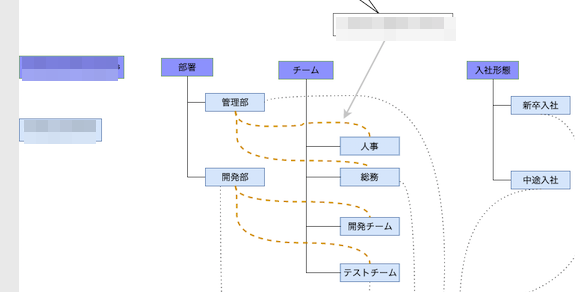
具体的な名称を書くというのは、こんな感じです(抜粋)
今回は https://www.draw.io/ を使用しましたが、特殊な機能は使っていないので、作図ツールなら何でも良いと思います。
機械的に作成できる情報は楽をして手に入れる
schemaspyとhakagiでDB情報を調べやすくする
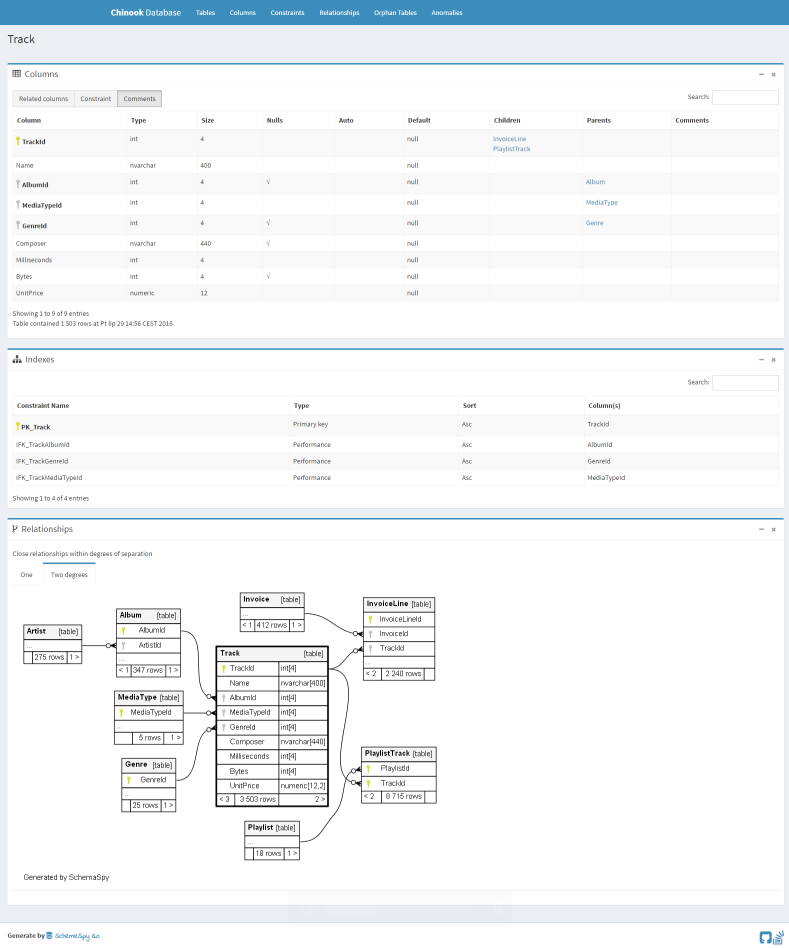
schemaspy というツールを使うと、DBのスキーマ情報からHTMLファイルを生成してくれます。
特に「自動でER図を作ってくれて、テーブル選択時に該当テーブルと関連テーブルのみを表示、テーブル画像をクリックで移動していける」ところが好きです。公式のサンプルをいじってもらうと分かりやすいと思います。
http://schemaspy.org/sample/tables/Track.html
しかしFKが貼ってないテーブルも多く、そのままだと関連付けてくれません。
schemaspy実行時に -rails オプションを付けると、カラム名から推察して生成してくれるのですが、一部うまくいきませんでした。
別途 hakagi というツールでほぼ完璧に推測してくれたので、こちらを実行して実際にFKを貼ってから生成するとうまくいきました。
参考リンク
- https://github.com/schemaspy/schemaspy
- https://tech.mercari.com/entry/2018/05/25/133818
- http://syucream.hatenablog.jp/entry/2018/05/06/201257
schemaspyのドキュメントはCIで常に最新のものを生成すると、みんなで使えるドキュメントになっておすすめです。
詳細を少しずつ埋めていく
Dmemoで、カラムやテーブルのメモを少しずつ増やす
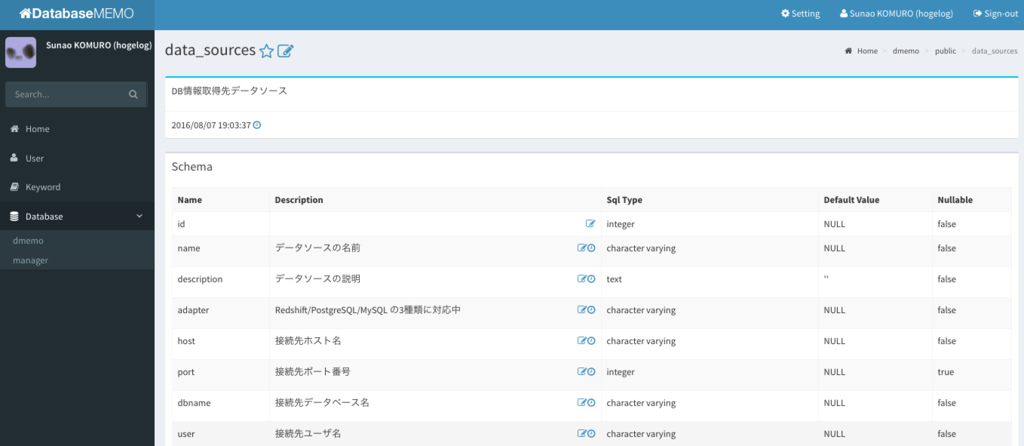
DmemoというツールをローカルにDockerで立てて、一旦自分用のメモとして学んだことや疑問などを記載しています。テーブルやカラムに対してメモを記載できます。
チームに公開してみんなで運用するかは、もう少し慣れてきたら検討したいと思います。
個人的には、外部ツールを運用してメモをみんなで書くよりも、できればDB自体にコメントを追加して、schemaspy等でドキュメント化する方に寄せたいなと思っているのですが、このへんはチームや規模次第かなとも思います。
前職でもDmemoを一部チームが運用していましたが、非開発者もSQLを実行してデータ調査等を行っており、そのようなメンバーがメモを共有するのには結構良かったかなと思います。
参考リンク
- https://github.com/hogelog/dmemo
- https://techlife.cookpad.com/entry/2016/08/08/103906
- https://dev.classmethod.jp/tool/launch_dmemo/
開発時にDBアクセスを確認する
DBアクセスのログをエンドポイントごとに分割する
画面を動かしながらDBアクセスを把握したかったのですが、1画面で複数のAPIが呼ばれるためデバッグログが混ざってしまい把握しにくかったです。
なので、エンドポイントごとにログファイルが分かれるようにし、共通部分の呼び出しを一旦除外しました。
(まだrailsに慣れてないので、もっといい方法があれば教えて下さい)
before_action :separate_log_file
def separate_log_file
# ヘッダーなどから共通で呼ばれるエンドポイントを除外
return if request.original_url.include?('api/notifications') \
|| request.original_url.include?('api/users/hoge')
t = Time.new
time_str = t.strftime("%Y%m%d_%H%M%S")
fullpath_str = sanitize_filename(request.fullpath)
ActiveRecord::Base.logger = Logger.new("#{Rails.root}/log/actions/#{time_str}__#{fullpath_str}.log")
end
def sanitize_filename(filename)
filename.strip.tap do |name|
name.gsub! /[^\w\.\-]/, '_'
end
end
少し画面を動かしたら複数のログファイルが生成されるので、呼ばれるエンドポイントごとに確認することができます。
もう少し頑張ればエンドポイントごとのCRUD表の生成とかもできるかもしれません。
まとめ
サービスも開発組織も大きくなってきましたが、引き続き品質もスピードを落とさずに継続的に価値を届け続けられるよう、色々仕組みを取り入れて頑張っていきたいと思います。
今回はまだ、自分で試してみた範囲に収まってしまっているので、少しずつチームに展開して運用していきたいと思います。