E-STATのデータを調べてみる
目次
1. 今回調査するデータ
2. 必要な準備
3. APIの仕様を調べる
4. まとめ
- 今日はE-STATのデータを利用して経済産業省企業活動基本調査のデータベースを調べてみましょう!
- E-STATとは:日本政府が公表しているオープンソースデータ
今回調査するデータ
今回調査するデータは2022年に公表された、2021年の企業活動基本調査です。
(ちなみに、今日1/30に2023年最新版の経産省企業活動基本調査が公開されていました!そっちで試しても、面白いかもしれないですね!)
このページの少し下に、DBが用意されていることが分かります。ここをポチると

下のようなページに飛びます。
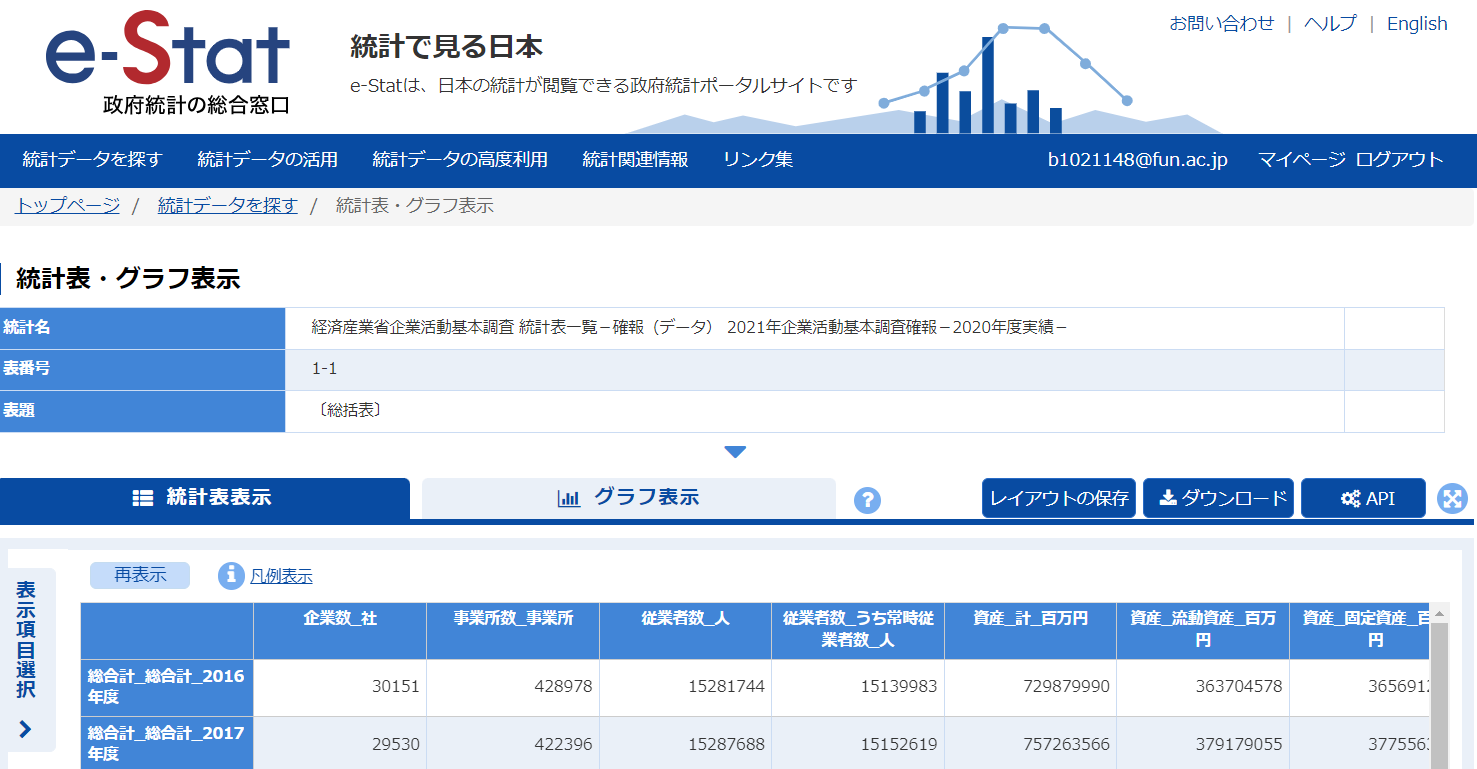
このページでは右のインデックスを選択して、表示するデータを絞り込むことができます
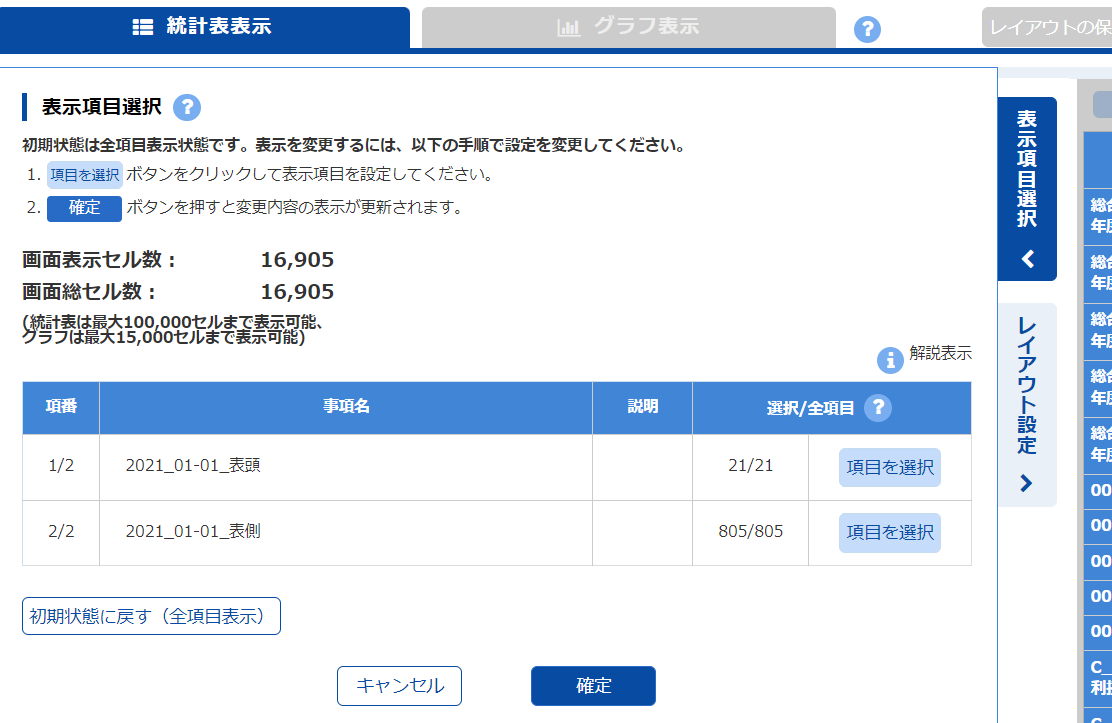
今回は「製造業」の「売上高」と「売り上げ総利益」を選択してみましょう
表頭
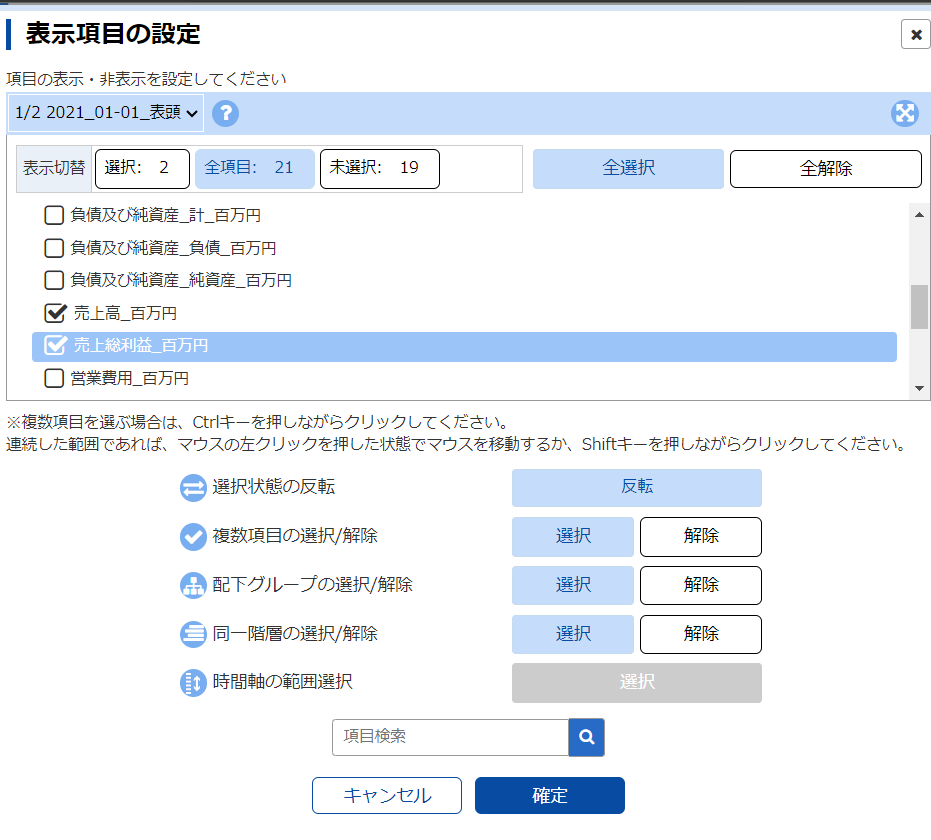
表側
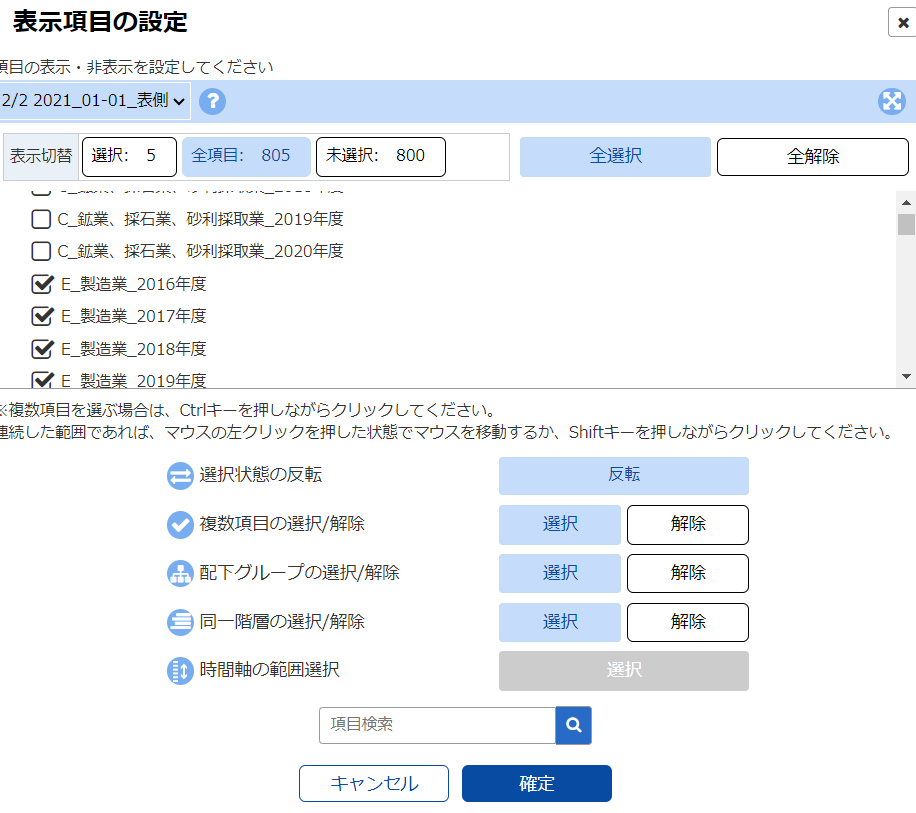
これで確定すると....
数値がグラフで表示されています。この状態でグラフ表示を選択すると...
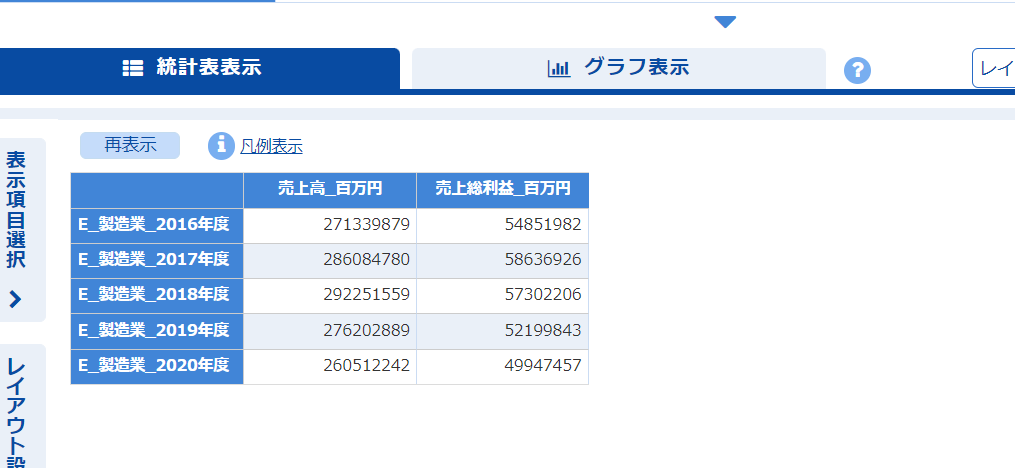
うーん、分かりにくい。
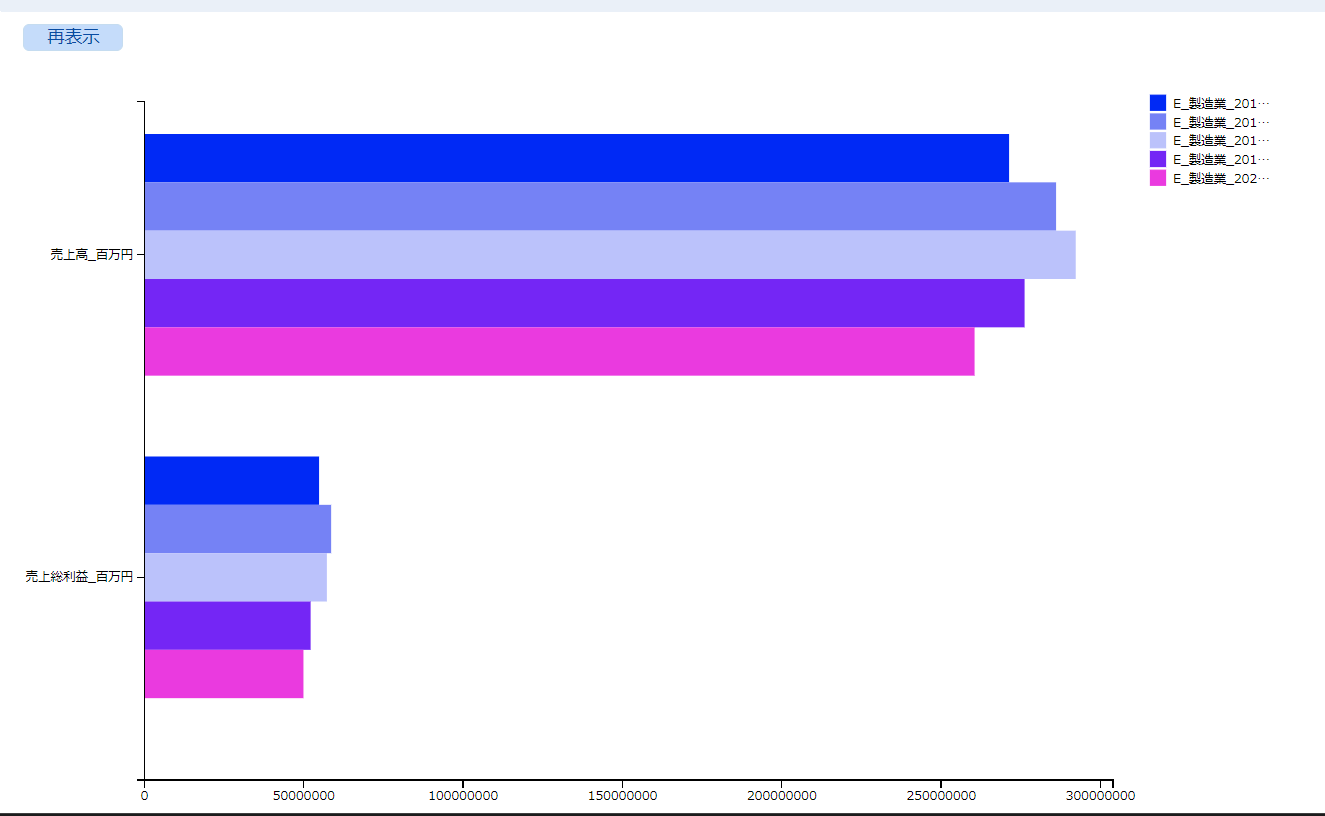
ということで、グラフの形式を変更します。左のグラフ表示設定をクリックして、棒グラフを選択します。
すると、縦の棒グラフになりました!
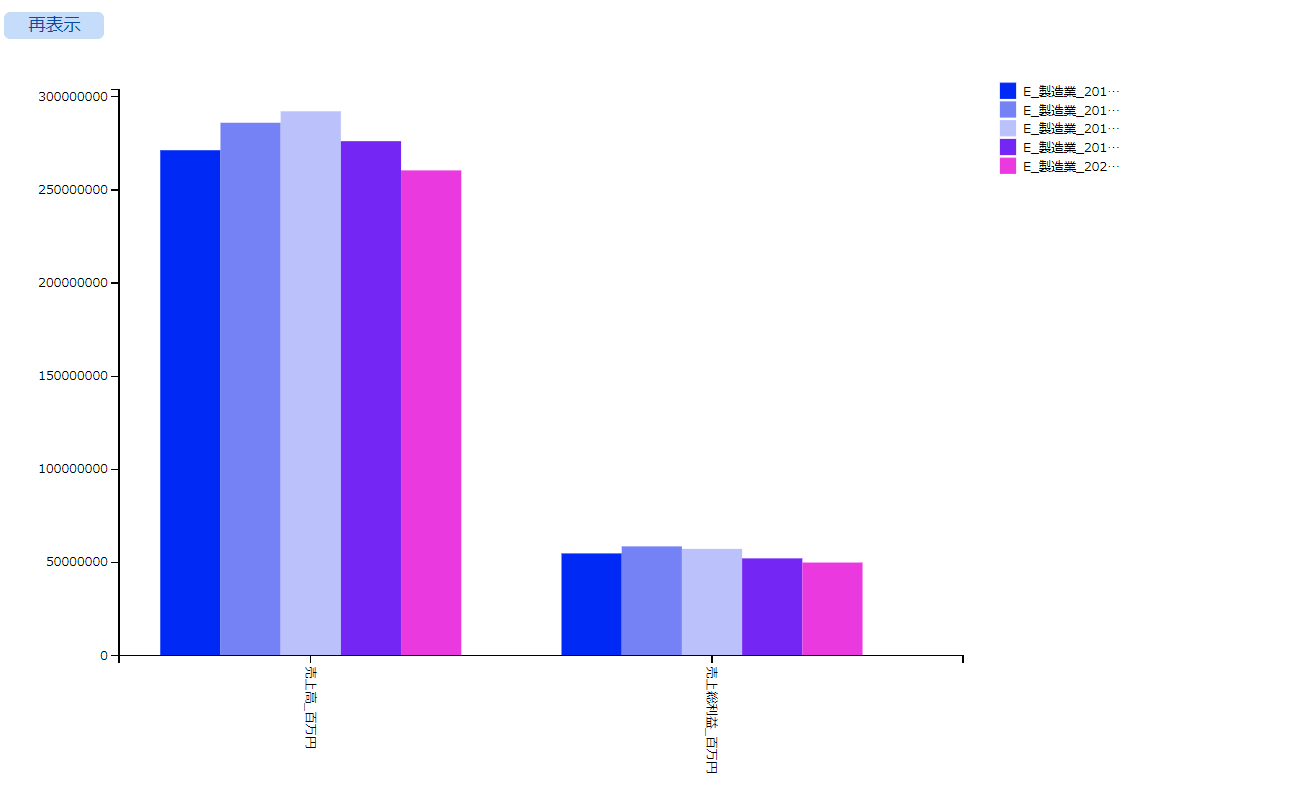
こんな感じで、webサイト上のデータベース表示を使うこともできますが、今回はJupyterNotebook上でこれを利用する方法について考えてみたいと思います。
先に、httpリスポンスで受け取るURLをどこかにコピペしておきましょう!
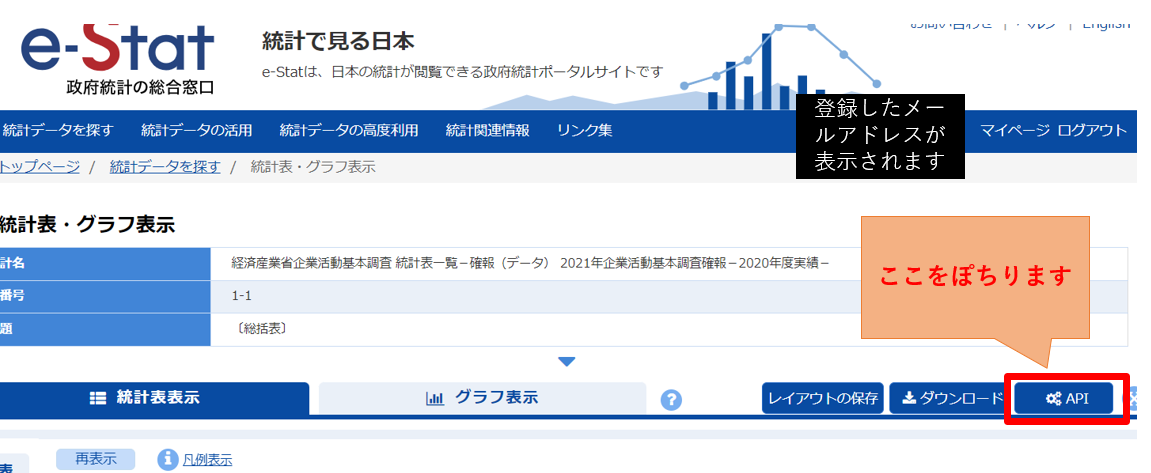
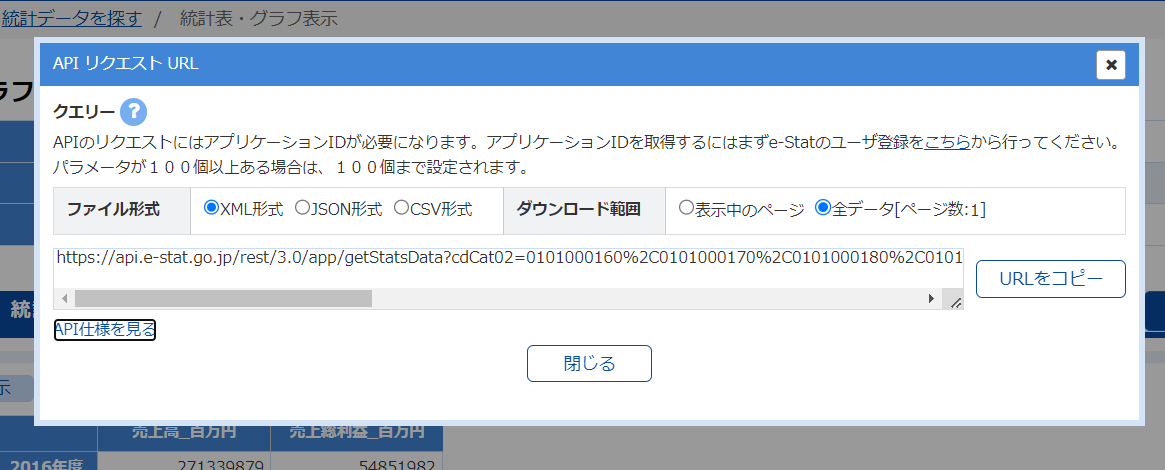
すると、ポップアップ画面でデータベースの情報が取得できるURLをコピペできる画面に遷移します。URLをコピーをクリックしてどこかに保存しておいて下さい。
必要な準備
1.まずはユーザ登録をしてAPIキーを取得しましょう。メールを仮登録して、届いたメールアドレスから本登録し、ログインします。
2.マイページへ飛んで

3.API機能(アプリケーションID発行)

4.APIを発行します

APIの仕様を調べる
下のURLは、E-STATSが提供しているAPIの機能の説明ページです。
2. APIの利用方法
- データベースのwebページで取得したURLからhttpリスポンスで情報を
GETします。 - 2.1 統計表情報取得
- CSVの場合、http(s)://api.e-stat.go.jp/rest/<バージョン>/app/getSimpleStatsList?<パラメータ群>
| パラメータ名 | 意味 | 必須 | 設定内容・設定可能値 |
|---|---|---|---|
| appId | アプリケーションID | 〇 | 取得したアプリケーションIDを指定して下さい。 |
| lang | 言語 | - | 取得するデータの言語を 以下のいずれかを指定して下さい。 ・J:日本語 (省略値) ・E:英語 |
| surveyYears | 調査年月 | - | 以下のいずれかの形式で指定して下さい。 ・yyyy:単年検索 ・yyyymm:単月検索 ・yyyymm-yyyymm:範囲検索 |
| openYears | 公開年月 | - | 調査年月と同様です。 |
| statsField | 統計分野 | - | 以下のいずれかの形式で指定して下さい。 ・数値2桁:統計大分類で検索 ・数値4桁:統計小分類で検索 |
| statsCode | 政府統計コード | - | 以下のいずれかの形式で指定して下さい。 ・数値5桁:作成機関で検索 ・数値8桁:政府統計コードで検索 |
| searchWord | 検索キーワード | - | 任意の文字列 表題やメタ情報等に含まれている文字列を検索します。 AND、OR 又は NOT を指定して複数ワードでの検索が可能です。 (東京 AND 人口、東京 OR 大阪 等) |
| searchKind | 検索データ種別 | - | 検索するデータの種別を指定して下さい。 ・1:統計情報(省略値) ・2:小地域・地域メッシュ |
| collectArea ※1 |
集計地域区分 | - | 検索するデータの集計地域区分を指定して下さい。 ・1:全国 ・2:都道府県 ・3:市区町村 |
| explanationGetFlg | 解説情報有無 | - | 統計表及び、提供統計、提供分類の解説を取得するか否かを以下のいずれかから指定して下さい。 ・Y:取得する (省略値) ・N:取得しない |
| statsNameList | 統計調査名指定 | - | 統計表情報でなく、統計調査名の一覧を取得する場合に指定して下さい。 ・Y:統計調査名一覧 統計調査名一覧を出力します。 statsNameListパラメータを省略した場合、又はY以外の値を設定した場合は統計表情報を出力します。 |
| startPosition | データ取得開始位置 | - | データの取得開始位置(1から始まる行番号)を指定して下さい。省略時は先頭から取得します。 統計データを複数回に分けて取得する場合等、継続データを取得する開始位置を指定するために指定します。 前回受信したデータの<NEXT_KEY>タグの値を指定します。 |
| limit | データ取得件数 | - | データの取得行数を指定して下さい。省略時は10万件です。 データ件数が指定したlimit値より少ない場合、全件を取得します。データ件数が指定したlimit値より多い場合(継続データが存在する)は、受信したデータの<NEXT_KEY>タグに継続データの開始行が設定されます。 |
| updatedDate | 更新日付 | - | 更新日付を指定します。指定された期間で更新された統計表の情報)を提供します。以下のいずれかの形式で指定して下さい。 ・yyyy:単年検索 ・yyyymm:単月検索 ・yyyymmdd:単日検索 ・yyyymmdd-yyyymmdd:範囲検索 |
| callback | コールバック関数 | △ | JSONP形式のデータ呼出の場合は必須パラメータです。 コールバックされる関数名を指定して下さい。 |
データベースのURLを見ると、何を取得しようとしているのかが確認できます。
import requests
'''
url = 'http://api.e-stat.go.jp/rest/3.0/app/json/
getStatsData?appId=取得したAPIキーをここにコピー
&lang=J 日本語データを取得します
&statsDataId=0003014275:統計データのID
&metaGetFlg=Y :
&cntGetFlg=N
&explanationGetFlg=Y
&annotationGetFlg=Y
§ionHeaderFlg=1
&replaceSpChars=0'
'''
url = 'ここに取得したAPIキーとURLを張り付けてください'
response = requests.get(url)
response = reponse.json()
response
さあ、取得したデータの中身をのぞいてみましょう!↓が出力結果です。
画面が緑なのは...私のvscodeのデザイン仕様なので気にしないでください。
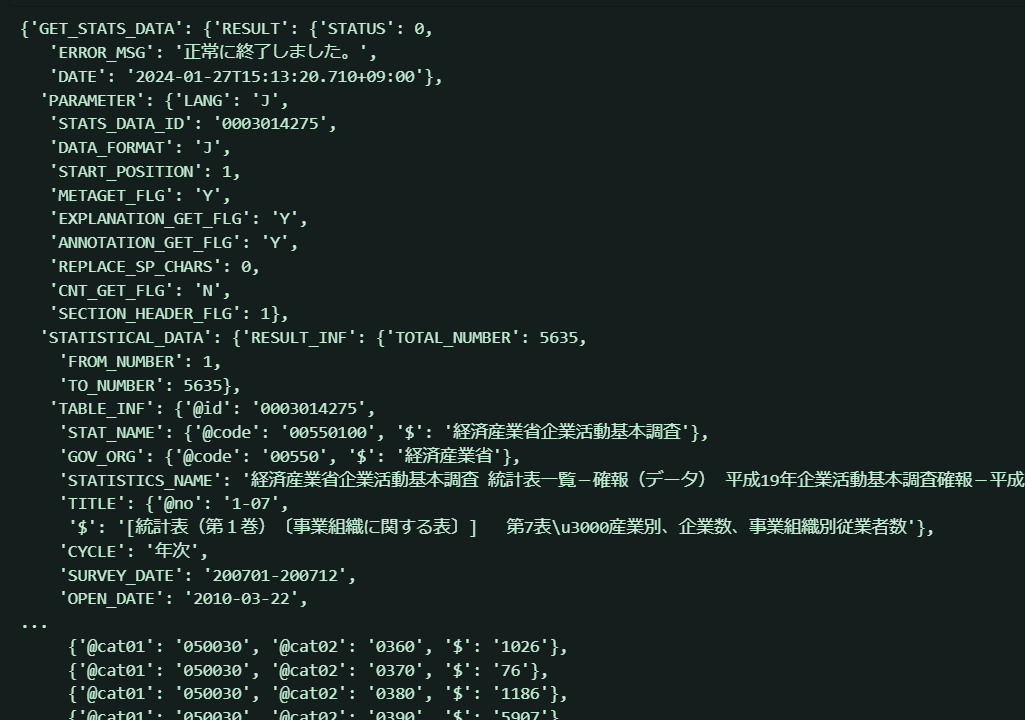
うわあ...なんか....うわあ...
(;'∀')多い
構造解析
データ解析といっても私はど素人なので、とりあえずこの謎の辞書型を一つずつ見ていきます。
個人的に一番気になるのは、恐らく取得したデータだと思われるcat01とcat02だったのでこの二つを調べてみましょう。
cat01にたどり着くまでの辞書の構造は次のようになっているみたいです。
GET_STATS_DATA
└ STATISTICAL_DATA
└ CLASS_INF
│ └ CLASS_OBJ
│ ├ cat01
│ └ cat02
└ DATA_INF
├ NOTE
└ VALUE
ということで、さっそく中身を見てみましょう
cat01 = r['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][0]
cat01
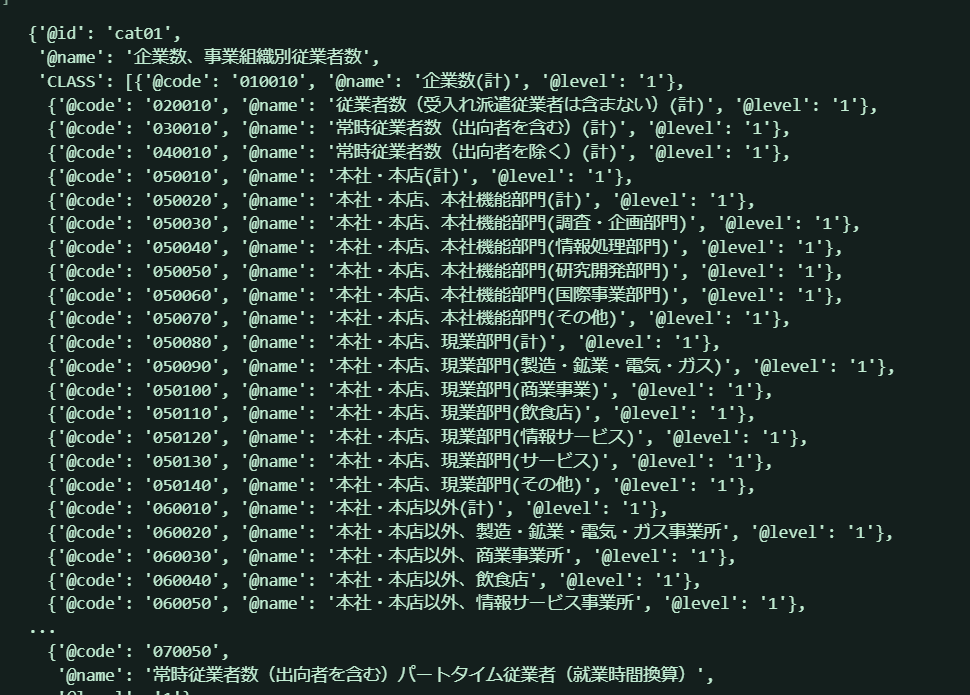
これは...
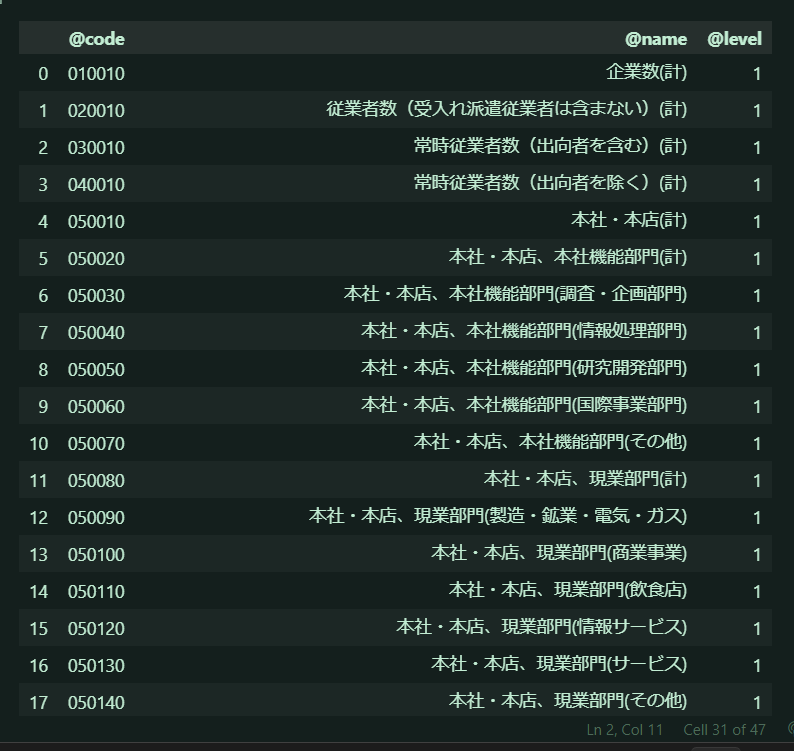
idが「企業数、事業組織別従業者数」になっています。これは前にデータベースのweb画面で見た表頭の項目ですね。この辞書型は後で処理に使うかもしれないので、pandasのデータフレームにしておきましょう!
enterprise = cat01["CLASS"]
enterprise_df = pd.DataFrame(enterprise)
enterprise_df
(出力)
で、cat02の方も同じように見ていきましょう。おそらく、こちらは表側の項目になっていることでしょう。
cat02 = r['GET_STATS_DATA']['STATISTICAL_DATA']['CLASS_INF']['CLASS_OBJ'][1]
cat02
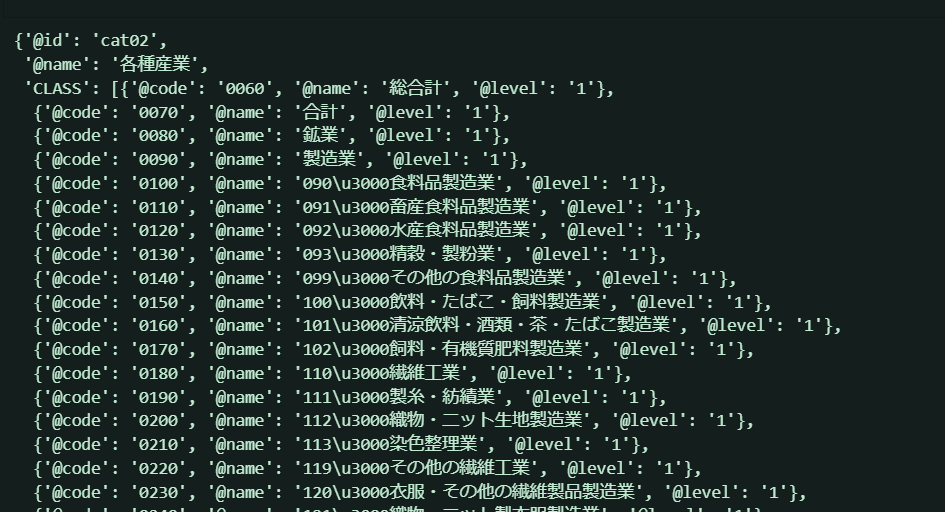
やっぱり、@id = '各種産業' ...表側項目のようです。
production = cat02['CLASS']
production_df = pd.DataFrame(production)
production_df
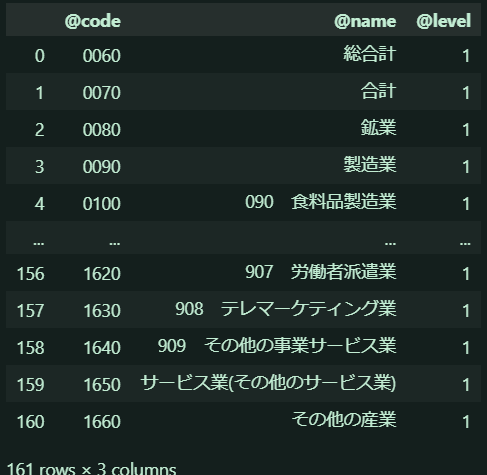
お!私が欲しがっていた「製造業」の部分は@codeなる要素が0090のようです。
次に、DATA_INFの中身を見てみましょう!こちらは、実際の数値データのようです。
value_df = pd.DataFrame(r['GET_STATS_DATA']['STATISTICAL_DATA']['DATA_INF']['VALUE'])
value_df
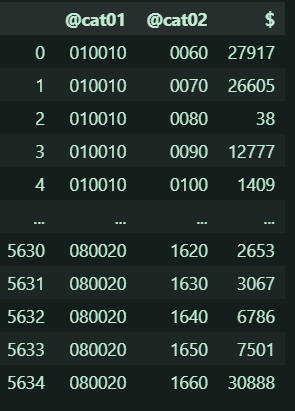
カラム$って数値データってことかな(;'∀')?
で、でも@cat02 = '0090' が産業だという事実は変わらないので、とりあえず@cat02が0090の部分を抽出してみましょう!
value_df = value_df.loc[value_df['@cat02']=="0090"]
value_df
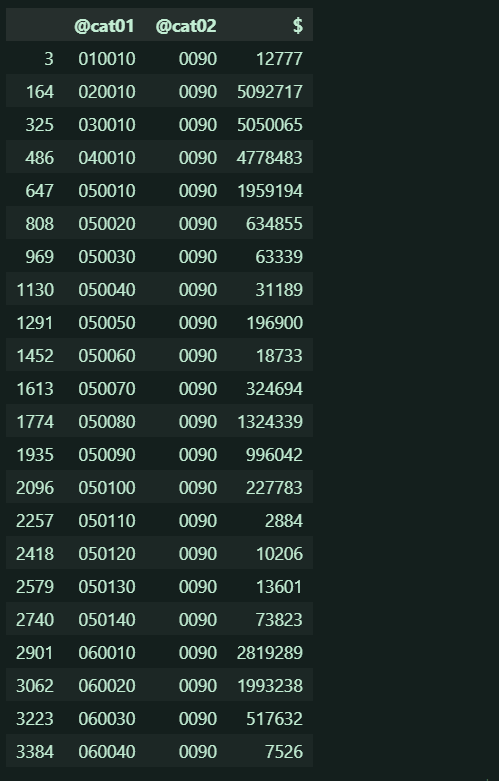
製造業に対する要素@cat01が値順で並んでいるので、valueデータは@cat01と@cat02の直積データのようです。
つまり、このテーブルデータは(最初のデータで解説すると)@cat02=0090(製造業)に関わっている@cat01 = 010010(企業数)は、$ = 12777 社という見方をするみたいですね!
製造業に関するデータをもっと見やすくするために、このデータをcat01とマージして各項目を表中に同時に示します。先ほど作ったenterprise_dfは@cat01のコードを示すカラム名が(@cat01ではなく)@codeになっていたので、これを@cat01に書き換えて、value_df とマージします。
enterprise_df["@cat01"] = enterprise_df["@code"]
enterprise_df = enterprise_df.drop("@code", axis=1)
# データカタログ情報取
pd.merge(value_df, enterprise_df, on="@cat01", how="left")
(出力)
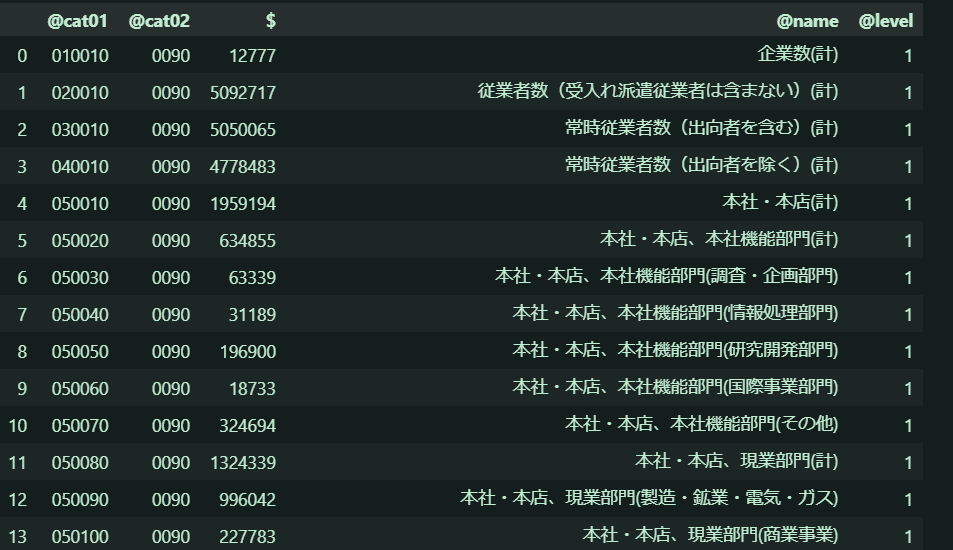
結構面白いですね...
まとめ
まだまだe-statsは掘れば深そうですね...APIの解説記事をちゃんと読めば、もうちょっと面白そうなことが分かりそうです