我慢の三連休
「我慢の三連休」を家で過ごしました。主に断捨離とコーディングです。
ライフワークの楽器(ベースギター,DTM)関連機材のお片付けが中心。
シールドケーブル、エフェクタ、楽譜等々ものすごい量でした。不要な物はハードオフしたり、資源ゴミに持ち込んだりかなりスッキリしたので息子にもちょっとだけ褒められました。
元々C言語エンジニアなのでGOTOは避けるのが鉄則。
はじめに
さて、厚生労働省に新コロナに関するオープンデータがあったので、Juliaでグラフ化してみました。
https://www.mhlw.go.jp/stf/covid-19/open-data.html
更に、https://www.mhlw.go.jp/stf/covid-19/kokunainohasseijoukyou.html#h2_1 には綺麗なグラフが並んでいるのですが、バラバラでなんか見づらい。
で、せっかくデータがあるので重ね合わせてみると判ることがあるかとトライしました。
当方の環境は以下です。
OS OSX Catalina
開発環境 ATOM + Juno + Julia 1.5.3になります。
データを見てみる
Webサイトからlinkをクリックしてみると、
https://www.mhlw.go.jp/content/pcr_positive_daily.csv
日付,PCR 検査陽性者数(単日)
2020/1/16,1
2020/1/17,0
2020/1/18,0
2020/1/19,0
・・・・・・・
・・・・・・・
なるほど。
デザイン開始
なるほど、これはCSV.jlとHTTP.jlを組み合わせると簡単にデータを取得できそう。
で、試してみた
CSVを取り込むには、
CSV.File(HTTP.request("GET","https://www.mhlw.go.jp/content/cases_total.csv").body)
で済むのですが、データ加工を考えると DateFrameで処理したい。
Julia> CSV.File(HTTP.request("GET","https://www.mhlw.go.jp/content/cases_total.csv").body) |> DataFrame
293×2 DataFrame
│ Row │ \x93\xfa\x95t │ \x93\xfc\x89@\x8e\xa1\x97Â\xf0\x97v\x82\xb7\x82\xe9\x8e\xd2 │
│ │ String │ Int64 │
├─────┼───────────────┼────────────────────────┤
│ 1 │ 2020/2/4 │ 15
・・・・・・・
・・・・・・・
後はとりあえず力業でコーディング
あれこれあって完成したグラフはこれです。
私の開発環境では日本語フォントが使えない(方針)ので仕方ない
グラフが出来た
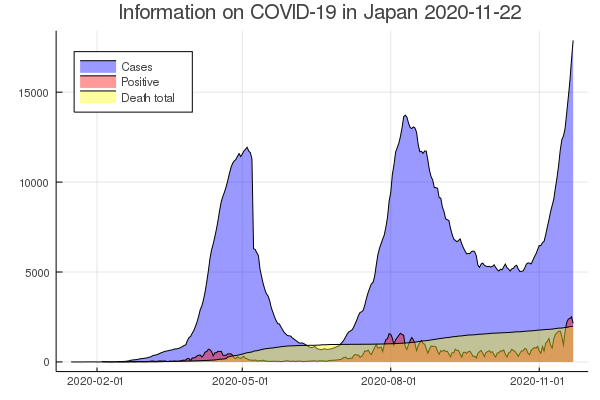
Casesは治療が必要な人数、Positiveは陽性者数合計(正確には感染届出者数でしょうね。右上がりではないので回復した方は引かれていると理解しています)、Dead totalは不幸にも亡くなった方の合計(当然右肩上がり)。ご冥福をお祈り申し上げます。
グラフを見ると第3波の真っ最中とよく分かる。GOTOしてる場合じゃないよねぇ。
従姉妹が看護師をしていますが、第3波のダメージはもっと大きいのではないかとの事。
CaseとPositiveのバランスが悪いのですが、これは厚生労働省のデータなので。
今後の展開
今後の展開としてはquery分析してみようかと思っています(時間が有ればの話です)
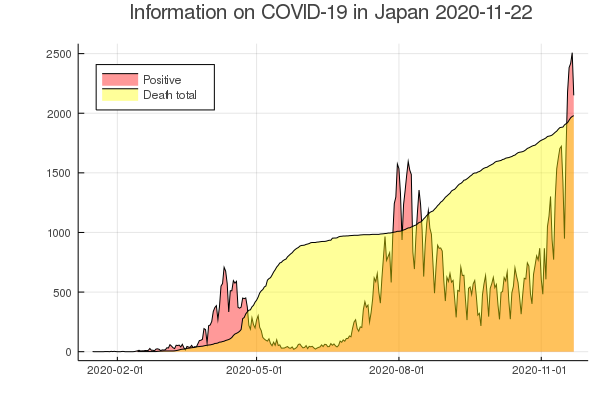
特にDead totalを良く見ると若干ですが急に右上がりになるポイントがあります。
このポイントがCasesの頂点と一致しているようにも見えるし、Positiveのピーク直後に一致しているように見えます。
この部分の近似式を求めると新たな発見があるかもしれません。
試しにPositiveとDead totalだけでグラフを作成してみるとなんか関連がありそうですね。
最適化を求めて見直し
で、力業で書いたので100行近くある。更にグラフを追加したい時にそこそこ直す必要がある。これは情けない。
そういう訳でグラフの追加が若干楽な手法を求めて四苦八苦しました。
こういう時はデータ構造から見直す。データ構造と言えば structを使うのが定石
mutable struct structTargetData
targetURL::String
Label::String
fillcolor::Symbol # :green :orange :black :purple :red :yellow :brown :white
end
arrayTargetDataFrame = [ # from https://www.mhlw.go.jp/stf/covid-19/open-data.html
structTargetData("https://www.mhlw.go.jp/content/cases_total.csv" ,"Cases" ,:blue),
structTargetData("https://www.mhlw.go.jp/content/pcr_positive_daily.csv" ,"Positive" ,:red),
structTargetData("https://www.mhlw.go.jp/content/death_total.csv" ,"Death total" ,:yellow) ]
方針としては、URL、ラベル、色を複数記述するだけで済むという事を目的としました。
こうすれば追加、順番変更も楽と考えました。
更に読み込んだCSVの日付データをキーにしてjoin、一つの表にして処理する方針とした。
後は力業。
結果として、50行程度の記述で済んだ。が・・・・
検討項目と対応内容
以下、検討事項一覧
1.厚生労働省のデータは開始日がバラバラなので統一したい
暫く悩んで、Join(outerjoin)を使うことにした。
一つの表にするメリットは大きいと考えたのです。
2.カラム名の変更を行う
息子にプログラムを見せたところ、なんでここだけ日本語なの?統一感無いねぇと煽られる
だって厚生労働省から取得したカラム名が日本語。outerjoin(df1, df2, on=:日付)みたいな感じ
こういう時はカラム名を変更する必要がある。
何故か指定した一つのカラム名を変更する手段が無い(と思われる)
先頭だけ変えたい。ちょっと悩む。
一度カラム名のリストを配列に取得して、最初の値を書換えてから全体を書き換えることにした
colnames = names(df); colnames[1] = "DATE"; rename!(df, colnames)
これでjoinするときに on=:DATEと書ける。
3. 1画面に収まらない
私はMacBook Air上でATOMを使って書いていますが36行までスクロールせずに見えます。
でもプログラムは50行程度。
息子に、一画面に入らないのは情けないねぇと煽られる。
大体、おまえはプログラム書けねぇじゃねぇかと、むかつきながら最適化を図る。
・using ライブラリ名を複数行書いていたが一行に纏める(そこそこ卑怯)
・ATOMをフルスクリーンにして39行まで見えるようにする。これは息子にかなり卑怯と言われた。
ま、外付けディスプレイ27インチにつなげば解決する話なんですが。
4.Joinとカラム名の処理を再検討した。
ここで問題は日付がString型である事。嫌だなぁ。
後でデータ分析を行うことを考慮するとDate型にしたい
で、dateformat="yyyy/mm/dd"を追加 https://csv.juliadata.org/stable/#DateFormat 参照
CSV.File(HTTP.request("GET","https://www.mhlw.go.jp/content/cases_total.csv").body; dateformat="yyyy/mm/dd") |> DataFrame
293×2 DataFrame
│ Row │ \x93\xfa\x95t │ \x93\xfc\x89@\x8e\xa1\x97Â\xf0\x97v\x82\xb7\x82\xe9\x8e\xd2 │
│ │ Date │ Int64 │
├─────┼───────────────┼────────────────────────┤
│ 1 │ 2020-02-04 │ 15 │
│ 2 │ 2020-02-05 │ 16 │
│ 3 │ 2020-02-06 │ 12 │
│ 4 │ 2020-02-07 │ 12 │
・・・・・・・
・・・・・・・
努力?の結果、読込と同時にカラム名変更、その後outerjoinを行うことに成功(不採用だけど)
function ReadCSV(url::String)
df = CSV.File(HTTP.request("GET",url).body) |> DataFrame
colnames = names(df); colnames[1] = "DATE"; rename!(df, colnames) # Change the name of the first column.
return df
end
dfs = []
for s in arrayTargetDataFrame
push!(dfs,ReadCSV(s.targetURL))
end
df = DataFrame(:DATE => Date("2000-01-01")) # Create an old date record for outerjoin.
for i = 1:length(arrayTargetDataFrame)
global df = outerjoin(df, dfs[i], on=:DATE)
end
sort!(df)
delete!(df,1) # remove old date record.
dfs = []
は、読み込んだDataFrame型のデータを配列に纏める為に、空の配列を用意した。
Juliaはこういう処理が簡単に書けるので便利
df = DataFrame(:DATE => Date("2000-01-01"))
は苦肉の策。空っぽのDetaFrame型はjoin出来ないので、一個だけ作り全てjoin後削除した
非常にかっこ悪い。(不採用だけど)
日付をDate型にしたメリットが最適化に生きてきた
一応、完成して満足していたのです。この時点でちょうど39行。素晴らしいと自画自賛。
息子に見せると、「へー」だけ。なにやら彼女にLineしている。
そりゃ親父より彼女の方が大事だろう。
しかし、どうせPlotに渡すのだから順番は関係ないんじゃ無いかと気がつく。
という事はjoinしたデータを作る必要は無い。数時間の検討が無駄になった。
結果、join関連はカット。
現時点では31行。
fillalpha = 0.4と透過率をハードコーティングしているが、データ化しようかと思っている
心残りは表示用の日付の処理。最初に読み込んだCSVの最終行の日付を採用しているがモヤモヤする。
やはりjoinを復活させて読み込んだCSVの最終的なDATEを採用すべきか・・・
結論としてはこの規模で自動化する必要が無いならExcelが良いかな。
作成したバージョンは31行ですが、投稿用にコメントを追加したので112行です。
どうでも良い話ですが。
#=
「厚生労働省掲載 新型コロナウイルス感染症について > オープンデータ」 グラフ化プログラム
https://www.mhlw.go.jp/stf/covid-19/open-data.html
2020/11/22
Julia 1.5.3 on MacBook Air 10.15.7
Qiita投稿用にコメントを大幅に追加したバージョン
=#
using HTTP, CSV # Webサイトからデータを取得するために使用
using DataFrames # 取得したCSVを加工用にDataFrameとして扱うために使用
using Plots # グラフ描画用
#=
データ取得元に対しての情報を纏めるための struct を定義する
最低限の目的としては、サイトを追加してラベル、色を指定可能とする
今後機能、パラメータの追加はここに行い、参照側で機能拡張を実装する
=#
mutable struct structTargetData
targetURL::String # ターゲット URL
Label::String # 表示用ラベル
fillcolor::Symbol # 表示グラフの色を指定する。 :green :orange :black :purple :red :yellow :brown :white
end
#=
ターゲットURLと関連情報を配列として定義
今後グラフを追加する場合には、このデータを追加定義する。
グラフは定義された順に描画される。
一般的に大きな数値データを先に描画すると良い結果が得られると思うので、目的に応じて順番,色を決定する
=#
arrayTargetDataFrame = [
structTargetData("https://www.mhlw.go.jp/content/cases_total.csv" ,"Cases" ,:blue),
structTargetData("https://www.mhlw.go.jp/content/pcr_positive_daily.csv" ,"Positive" ,:red),
structTargetData("https://www.mhlw.go.jp/content/death_total.csv" ,"Death total" ,:yellow)
]
#=
渡された URLからデータを取得する
(面倒なのでインターネット未接続などのエラートラップは行っていない)
1.データの取得
2.DeataFrame型に格納
3.カラム名変更
=#
function ReadCSV(url::String)
# CSV中の日付データをDate型で扱いたいため、dateformat="yyyy/mm/dd"を追加。
# 得られたCSV型を pipingを使ってDetaFrame型に変換。
df = CSV.File(HTTP.request("GET",url).body; dateformat="yyyy/mm/dd") |> DataFrame
# 厚生労働省のデータのカラム名が "日付" だったので "DATE" に変更
# 今回使用した開発環境はコメントも含めて全て英語で記述したい方針にした為に日本語を避けた。
# サブ機は日本語OKなのでそちらを使えば問題ないのだが・・・
# カラム指定には別の方法もあるが、明確にしたかったのでカラム名変更を採用(要は後で忘れないようにした)
colnames = names(df) # カラム名を配列で取得
colnames[1] = "DATE" # 厚生労働省データの先頭は "日付" なので、"DATE" に変更
rename!(df, colnames) # 配列を使ってカラム名変更を行う
# 直前の rename!は df を返すので、シンタックスとしては returnは不要です。
# 私は戻り値を明確にしたい方針なので必ず return 文を書くようにしています。
return df
end
#=
メインルーチン
=#
#
# データ取得と格納
# 取得したCSVから生成された DetaFrame型データを配列に追加する
#
dfs = [] # 配列追加用の Place holder
for i in arrayTargetDataFrame
push!(dfs,ReadCSV(i.targetURL)) # 取得したCSVから生成された DetaFrame型データを配列に追加する
# 以上の処理によりDataFrames型が格納された配列が生成される
# dfs[1] : 感染者数のデータセット
# dfs[2] : 治療が必要な人の数のデータセット
# dfs[3] : 死亡者数合計のデータセット となる。
# 順番,要素数は最初に定義した URL順と数になる。
end
#
# グラフ描画
#
# 最初にグラフ全体に影響するパラメータを定義する
# ここでは、数字表示を:plain(指数表示で無い)、データラベル表示位置を左上、タイトルを指定
# string(last(dfs[1]).:DATE)は、取得したデータの日付データの最終ライン(最新日付)を取得してタイトルに追記した
# この方法で十分だが、なにかモヤモヤする。将来変更する第一候補
ps = plot(
formatter = :plain,
legend = :topleft,
title = "Information on COVID-19 in Japan " * string(last(dfs[1]).:DATE),
)
#
for i = 1:length(arrayTargetDataFrame)
plot!(
ps,
dfs[i][!, :DATE], # 最初が日付 カラム番号でも良い dfs[i][!, 1]
dfs[i][!, 2], # 表示する数値データ
fillrange = 0, # 色を塗る開始位置
fillalpha = 0.4, # 塗る色の透過度 適当に試して値を決めた。将来は URL 関連情報を一緒に纏める予定
color = :black, # 一応目立つように
fillcolor = arrayTargetDataFrame[i].fillcolor, # 指定されてた色で描画
label = arrayTargetDataFrame[i].Label, # ラベルを指定
)
end
# png形式で保存
savefig("Covid-19"*string(last(dfs[1]).:DATE)*"-plot.png")
# 画面に描画
plot(ps)
# That's all folks.
以上