こんにちは〜。
2019/12/23 クリスマス前ですね。
今日はスカッター行列について触れたいと思います。
scatter matrix(スカッター行列) ・・・ 各データ間でどんな相関があるかをざっくり見るために使う図
API
pandas.plotting.scatter_matrix(frame, alpha=0.5, figsize=None, ax=None, grid=False, diagonal='hist', marker='.', density_kwds=None, hist_kwds=None, range_padding=0.05, **kwds)
公式ドキュメント
パラメータの説明
frame → pd.DataFrame 可視化したいデータをDataFrameクラスでいれる。
c → colorのこと。
alpha → 図上のオブジェクトの透明度。
figsize → 図のサイズ
grid → Trueにセットしたならば、グリッドを表示。
diagonal → カーネル密度推定または対角線上のヒストグラムプロットの「kde」と「hist」を選択。
marker → Matplotlibのmarker。デフォルトは'.'
density_kwds → カーネル密度推定プロットに渡される
hist_kwds → hist関数に渡される(ヒストグラムのbins(棒の数)を指定)
range_padding → (x_max-x_min)または(y_max-y_min)に対するxおよびyの軸範囲の相対的な拡張、デフォルトは0.05
サンプルコード
Pythonで始める機械学習から引用。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import mglearn
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
iris['data'], iris['target'], random_state=0
)
fig, ax = plt.subplots()
iris_dataframe = pd.DataFrame(X_train, columns=iris.feature_names)
grr = pd.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15),
ax=ax, marker='o', hist_kwds ={'bins': 20}, s = 60,
alpha=0.8, cmap=mglearn.cm3)
plt.show()
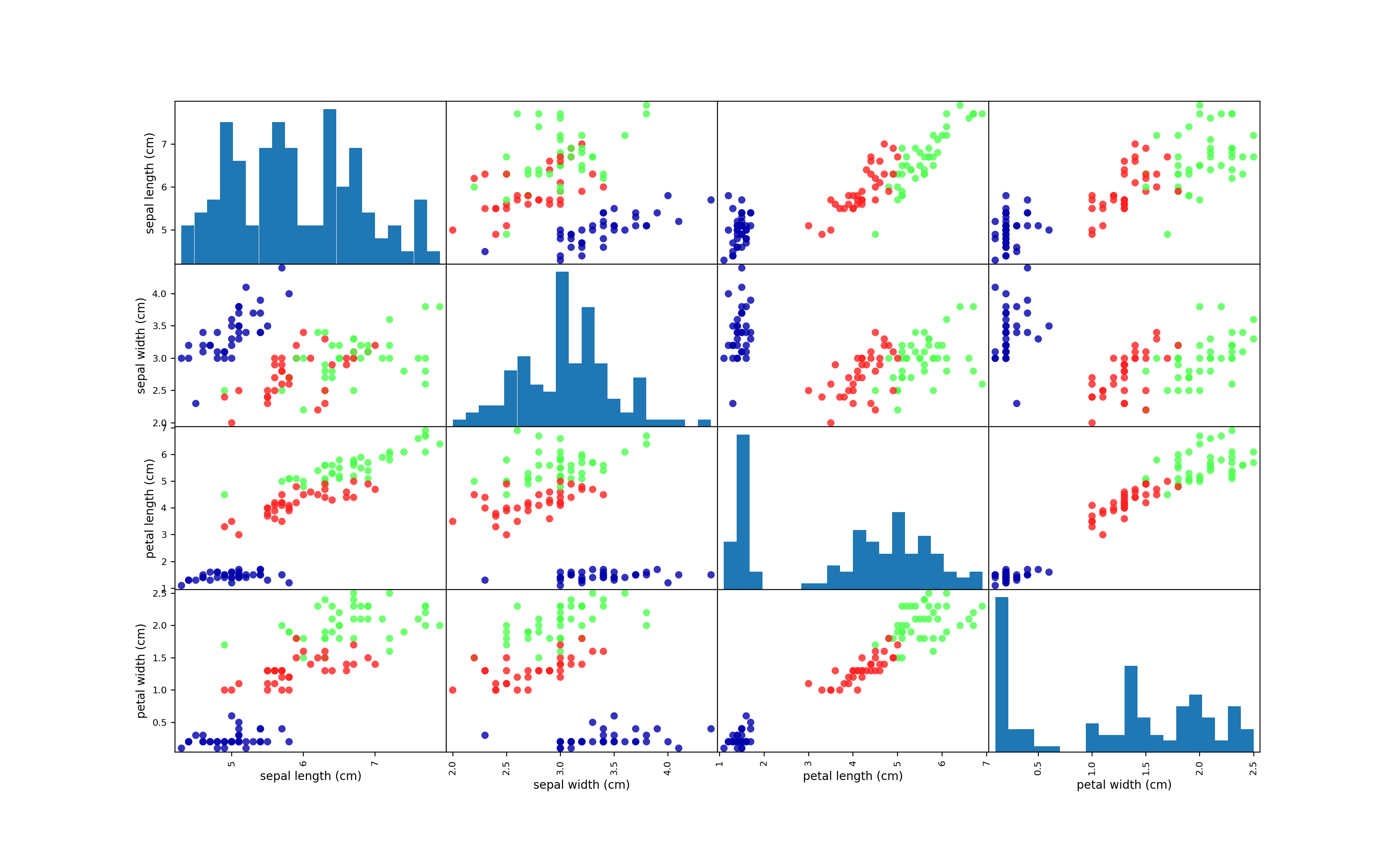
美しいですね。
軽く説明しておくと、基本的にはグラフの行列になっていて、xとyの組み合わせは行列の要素によって変わってくる。
対角部分は個々のヒストグラム(bin : 20)が描写される。
scatter_matcixは全ての変数の組み合わせ可能な特徴量の組み合わせをプロットするための関数。
しかしこの方法では全ての特徴量の同時に見ることができないため、データの興味深い側面が見ることができない場合があることに注意。
とりあえず、データを検査するためには最良の方法かもしれない。