与えられた文字列がランダムかそうでないかを判定したいと試行錯誤した記録です(勉強会で発表した発表スライド の書き起こしです).
追記
- 2019/06/05 PyPIに登録してみた
- 2019/06/12 実験2を追加しました
目的
ランダムな文字列の生成は簡単(本当にランダムなのかなどの面倒な話はなし)だが,ある文字列が与えられたとき、それがランダムな文字列かどうかを判定したい.
今回扱うランダムな文字列の定義
- rand関数などで無作為に生成された文字の列
- 平仮名だったり漢字だったり英数字だったりと様々
- 文字列の長さもランダム(ただし現実的な長さ)
ランダムな文字列の特徴と検証
- 一様分布から生成されるので文字は均一に出現する
- 発音など単語の言語の生成規則やルールには従わない
- 意味がない単語が生成される
出現頻度の検証
- カイ二乗検定を使って,頻度の検定をする
- 長くて10文字程度の文字列では十分な検定できない
- 文字頻度が1ずつの単語だってある(例: word など)
可読可能の検証
- 母音や子音に分けて,その連続性を調べる
- 日本語は基本的に「文字≒発音記号」でした
- 海外(欧米圏)では対応手法あり
意味ありの検証
- 辞書データを作って,テーブルルックアップしよう
- 文字の揺らぎや三単現や軽い誤字の文字変化はどうしよう
- 未知な言葉はどうしよう
状態遷移モデルを用いて考えてみた
- ある状態から次の状態への遷移をモデル化したもの
- 文字を状態とし,文字列を遷移と考える

- 文字 $i$ から文字 $j$ の遷移確率を ${p_{i, \ j}}$ とすると文字列の遷移確率は以下のうように求められる
$P = \prod_{i, \ j}{p_{i, \ j}}$
遷移確率から何がわかるか
- 状態遷移確率は,学習データの文字遷移パターンに従って,学習(計算)される
- 学習データと入力文字列のパターンが近ければ,遷移確率は大きくなり,反対に遠ければ小さくなる
- つまり,学習パターンに正しい単語データを与えれば,ランダムかそうでないかが判定できるはず
やってみた
遷移確率を求めるプログラムと,その評価を行いました.
実装
- Pythonで愚直に頻度を計算してるだけです
- mitsuharu/TextTransProb: It computes a transition probability of a text.
実験
中学英単語一覧で学習して,適当な入力を与えた時の結果です.英単語とその他の適当な文字列は分かれているように見えます.検証は訓練とテストを厳密に分けてやるべきですが,対象が言語であり訓練と大きく異なる新語は頻繁には生成されないという仮定,類似度判定を目的としてるので,ある程度の性能は出ていると思ってます.
| 入力 | 確率 |
|---|---|
| apple | 0.09252656 |
| blue | 0.06042812 |
| difficualt | 0.00774749 |
| nvjhyhjnajas | 0.00018930 |
| zf3cd | 0.00055871 |
| ひらがな | 0.00000661 |
また,英単語に関しては,全ての英単語を集めたリポジトリ dwyl/english-wordsn があったので,英単語に関してはこれで学習すれば問題なさそうでした.なお,日本単語の良さげなリストは見つかっていないです.
実験2(追加,2019/06/12)
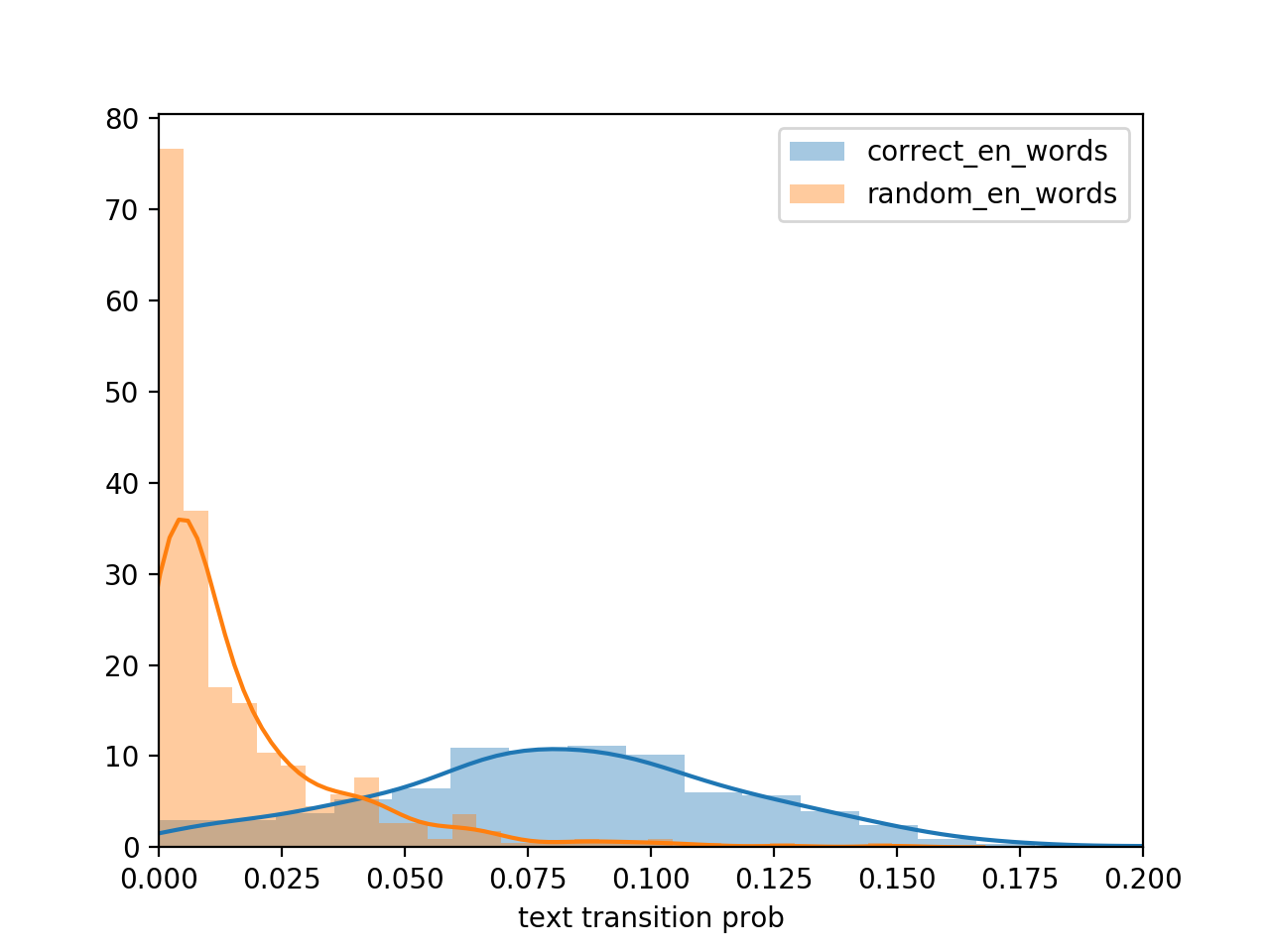
上記の英単語データ dwyl/english-wordsn を使って学習したモデルを使って,中学で習う英語単語(約500語)と同数のランダム生成した英字列の確率を計算しました.下図から,それぞれのピークが異なっていることがわかります.
まとめ
このランダムの判定は,ある他の分類問題のための特徴量の1つにできないかと計算したものです.実際,このランダム判定を組み込んで,分類問題をやってますが,良い結果で出たので,まあ悪い手法ではなかったなと思ってます.
PyPIに登録しました(追記, 2019/06/05)
この遷移確率計算をpip installできるように,texttrans · PyPI に登録してみました.英単語を学習済みで公開してます.日本語は良さげなデータがあれば,おいおい追加します.
$ pip install texttrans
from texttrans.texttrans import TextTrans
p = TextTrans().prob("pen")
print(p) # 0.11640052876679541