Assosiate Cloud Engineer 取得の勉強中にやった内容です。取得してしまうと、1ヶ月くらいで忘れてしまったので、残しておきます。
今回は通知先をSlackにしましたが、メールなど色々と選べますので、好きなものを選ぶのが良いと思います。
Overview
GCEのインスタンスに対して、以下のような項目を監視してみます。
| 項目 | 説明 | 監視内容 |
|---|---|---|
| プロセス監視 | GCEインスタンス内で実行されている プロセスの稼働状態を監視します。 |
ntpdが実行されているか |
| リソース監視 | CPU使用率やメモリ使用率といった OSリソースに対して、しきい値を 設けて監視します。 |
CPU使用率が90%未満か |
| サービス監視 | サービスが正常に提供されているかを 監視します |
WebサービスがHTTP200応答を返しているか |
ToDo
-
構築手順
- 通知チャネルを作る。
- プロセス監視のアラートポリシーを作る。
- リソース監視のアラートポリシーを作る。
- サービス監視のアラートポリシーを作る。
-
確認
- プロセスダウン
- リソース高騰
- サービスダウン
Procedure
Create a new project
あとですぐに消せるように、一時的なプロジェクトを作成します。
- 画面の上にある [Select a project] を選択する。
- [NEW PROJECT] を選択する。
- 「Project Name」に任意の名前を入れる。
グローバルで一意になるように、IDには数字が付与される。 - [Create]を選択する。
Create a VM instance
GCEインスタンスを作成します。
-
ハンバーガーから、「Compute Engine - VM instances」を選択する。
-
[Create]を選択する。
-
任意で設定値を入れる(※今回の設定値は、下表)。
Item Default Value Value Comments Name instance-1 ← 任意の名前 Labels n/a n/a Region us-central1(Iowa) ← とりあえずデフォルト Zone us-central1-a ← 同上 Machine Family General-purpose ← 同上 Series N1 ← 同上 Machine Type n1-standard-1 n1-standard-2 2vCPUのやつにしてみます Container No ← 今回はコンテナは使わないので Boot Disk Debian GNU/Linux 9 (strech) ← とりあえずDebianで。 Service Account Compute Engine default service account ← 今回はデフォルト Access scope Allow default access ← 同上 Firewall None HTTP,HTTPS HTTP(S)通信を許可 -
[Create]を選択する。
-
一覧に「instance-1」が表示されて、
 がついていれば、OK。
がついていれば、OK。
Configure VM instance
GCEインスタンスの設定を行います。今回は、StackDriverエージェントを入れて監視が行えるようにします。
また、リソース系の動作確認を行うために、stressを入れます。
-
ハンバーガーから、「Compute Engine」を選択する。
-
さっき作成したインスタンスの右にある[SSH]を選択する。
-
Stackdriver Monitoring Agent のインストール
$ curl -sSO https://dl.google.com/cloudagents/install-monitoring-agent.sh $ sudo bash install-monitoring-agent.sh -
Stackdriver Monitoring Agent の状態確認(active(running)ならOK)。
$ sudo systemctl status stackdriver-agent -
パッケージの最新化を行う。
$ sudo apt update && sudo apt -y upgrade -
nginxをインストールする。
$ sudo apt -y install nginx -
nginx の状態を確認する(active(running)ならOK)。
$ sudo systemctl status nginx -
HTMLファイルの書き換え
$ echo "OK" | sudo tee /var/www/html/index.nginx-debian.html -
nginx 動作確認(OKと出ればOK)。
$ curl http://localhost/ OK -
sysstatをインストールする。
$ sudo apt -y install sysstat -
stressをインストールする。
$ sudo apt -y install stress
Add a slack notification channel
通知チャネルの追加を行います。
-
ハンバーガーから、「Monitoring - Settings」を選択する。
-
[NOTIFICATION CHANNELS]を選択する。
-
「Slack」の横の[ADD NEW]を選択する。
-
Slack側の承認ページにリダイレクトされるので、[許可する]を選択する。
-
「Add Slack Channel」のダイアログボックスが出るので、以下を入力する。
Item Default Value Value Comments Channel Name - #gcp 任意の名前(Slackに左記チャネルを作成済の前提です) -
[TEST CONNECTION]を選択する。
-
Slackのチャンネルに、Google Cloud Monitoringからの通知が出てくればOK。

-
[SAVE]を選択する。
-
「Slack」のところに、作成した内容でチャネルが存在すればOK。
Create a process monitoring policy
プロセス監視のポリシーを作成します。
-
ハンバーガーから、「Monitoring - Alerting」を選択する。
-
[CREATE POLICY]を選択する。
-
以下を入力する。
Item Default Value Value Comments Name - ProcessMonitoring 任意の名前(わかりやすいやつ) Condition - ntpd 下記参照。 Notification (optional) - Slack 今回はSlackを使用 Documentation (optional) - ← Condition - ntpd
Item Default Value Value Comments Type - Process Health プロセス監視 Name - ntp 任意の名前(わかりやすいやつ) Resource Type - All GCE VM Instance Command Line - Contains 'ntpd' ntpdを監視する Condtion triggers if Any time series violate ← いつでもあげる Condition, Threshold, For - is below, 1, 1 min 1分間でプロセス起動数が、1を下回ったら -
[SAVE]を選択する。
Create a resource monitoring policy
リソース監視のポリシーを作成します。
-
ハンバーガーから、「Monitoring - Alerting」を選択する。
-
[CREATE POLICY]を選択する。
-
以下を入力する。
Item Default Value Value Comments Name - ResourceMonitoring 任意の名前(わかりやすいやつ) Condition - 下記参照 Notification (optional) - Slack 今回はSlackを使用 Documentation (optional) - ← Condition - GCE VM Instance - CPU utilization for idle
Item Default Value Value Comments Type - Metric 指標 Name - GCE VM Instance - CPU utilization for idle 任意の名前(わかりやすいやつ) Resource Type - GCE VM Instance Metric - CPU Utilization(agent.googleapis.com/cpu/utilization) StackDriverエージェントが取得するCPU使用率 Filter - cpu_state = 'idle' アイドルでフィルタリング Condtion triggers if Any time series violate ← いつでもあげる Condition, Threshold, For - is below, 10, 1 min 1分間でCPU使用率のアイドル値が10%を下回ったら(=CPU使用率90%) -
[SAVE]を選択する。
-
その他、標準的なリソース監視項目もConditionに追加しておきます。
Condition - GCE VM Instance - CPU utilization for userItem Default Value Value Comments Type - Metric 指標 Name - GCE VM Instance - CPU utilization for user 任意の名前(わかりやすいやつ) Resource Type - GCE VM Instance Metric - CPU Utilization(agent.googleapis.com/cpu/utilization) StackDriverエージェントが取得するCPU使用率 Filter - cpu_state = 'user' ユーザ時間でフィルタリング Condtion triggers if Any time series violate ← いつでもあげる Condition, Threshold, For - is above, 80, 1 min 1分間でCPU使用率のuser値が80%を上回ったら Condition - GCE VM Instance - CPU utilization for system
Item Default Value Value Comments Type - Metric 指標 Name - GCE VM Instance - CPU utilization for system 任意の名前(わかりやすいやつ) Resource Type - GCE VM Instance Metric - CPU Utilization(agent.googleapis.com/cpu/utilization) StackDriverエージェントが取得するCPU使用率 Filter - cpu_state = 'system' カーネル時間でフィルタリング Condtion triggers if Any time series violate ← いつでもあげる Condition, Threshold, For - is above, 40, 1 min 1分間でCPU使用率のsystem値が40%を上回ったら Condition - GCE VM Instance - CPU load (15m)
Item Default Value Value Comments Type - Metric 指標 Name - GCE VM Instance - CPU load (15m) 任意の名前(わかりやすいやつ) Resource Type - GCE VM Instance Metric - CPU load (15m)(gent.googleapis.com/cpu/load_15m) ロードアベレージ Filter - cpu_state = 'system' カーネル時間でフィルタリング Condtion triggers if Any time series violate ← いつでもあげる Condition, Threshold, For - is above, 4, 1 min CPU数の2倍を超えたら Condition - GCE VM Instance - Memory utilization
Item Default Value Value Comments Type - Metric 指標 Name - GCE VM Instance - Memory utilization 任意の名前(わかりやすいやつ) Resource Type - GCE VM Instance Metric - Memory utilization(agent.googleapis.com/memory/percent_used) StackDriverエージェントが取得するMemory使用率 Filter - ← Condtion triggers if Any time series violate ← いつでもあげる Condition, Threshold, For - is above, 90, 1 min 1分間でMemory使用率のused値が90%を上回ったら Condition - GCE VM Instance - Disk utilization
Item Default Value Value Comments Type - Metric 指標 Name - GCE VM Instance - Disk utilization 任意の名前(わかりやすいやつ) Resource Type - GCE VM Instance Metric - Disk utilization(agent.googleapis.com/disk/percent_used) StackDriverエージェントが取得するDisk使用率 Filter - ← Condtion triggers if Any time series violate ← いつでもあげる Condition, Threshold, For - is above, 80, 1 hour 1時間でDisk使用率のused値が80%を上回ったら
Create a uptime check
稼働時間チェックのポリシーを作成します。
-
ハンバーガーから、「Monitoring - Uptime checks」を選択する。
-
[CREATE UPTIME CHECK]を選択する。
-
以下を入力する。
Item Default Value Value Comments Title - TestUptimeCheck 任意の名前(わかりやすいやつ) Check Type HTTP ← Resource Type URL ← Hostname - 上で作成したGCEインスタンスの外部IP チェックするURL Path - / 同上 Check every 1 minute ← -
[TEST]を選択する。
-
「
Responded with 200 (OK) in xxx ms.」と返ってくればOK。 -
[SAVE]を選択する。
-
[CREATE ALERT POLICY]を選択する。
-
以下を入力する。
Item Default Value Value Comments Name - ServiceMonitoring 任意の名前(わかりやすいやつ) Condition - 下記参照 Notification (optional) - Slack 今回はSlackを使用 Documentation (optional) - ← Condition - Uptime Health Check
Item Default Value Value Comments Type - UPTIME CHECK 稼働時間チェック Name - Uptime Health Check 任意の名前(わかりやすいやつ) Metric check passed ← Resource Type All ← Uptime check id TestUptimeCheck ← Condtion triggers if Any time series violate ← いつでもあげる Condition, Threshold, For - is above, 1, 1 min 1分間でアカンのが1つ以上あったら -
[SAVE]を選択する。
Confirmation
Process monitoring
プロセス監視の動作チェックをしてみます。
-
ハンバーガーから、「Compute Engine」を選択する。
-
さっき作成したインスタンスの右にある[SSH]を選択する。
-
ntpd の停止
$ sudo systemctl stop ntp -
ntpd のダウンを検知して、Slackに通知が来ます。

-
ntpd の起動
$ sudo systemctl start ntp -
ntp ダウンのインシデントが解消したことを告げる通知が、Slackに来ます。

Resource monitoring
リソース監視の動作チェックをしてみます。
-
ハンバーガーから、「Compute Engine」を選択する。
-
さっき作成したインスタンスの右にある[SSH]を選択する。
-
ストレスかける(-cはCPU、2はストレスかけるコア数)
$ stress -c 2 -
CPU使用率がすごくなってることを検知して、Slackに通知が来ます。
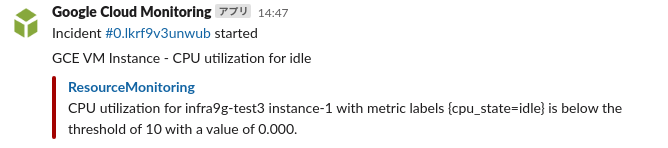
-
[Ctrl]+[C]でストレスかけるのを止める。
-
CPU使用率のインシデントが解消したことを告げる通知が、Slackに来ます。

Service monitoring
稼働時間チェックの動作チェックをしてみます。
-
ハンバーガーから、「Compute Engine」を選択する。
-
さっき作成したインスタンスの右にある[SSH]を選択する。
-
nginx の停止
$ sudo systemctl stop nginx -
稼働時間チェックの異常を検知して、Slackに通知が来ます。

-
nginx の起動
$ sudo systemctl start nginx -
稼働時間チェック異常のインシデントが解消したことを告げる通知が、Slackに来ます。

よくわからない点
1分間隔で監視しているのに、通知が来るのが数分たった後だったりします。
なんでだろう。