先日のに引き続き、Slackの3秒の壁を越えるための施策について、考えてみたいと思います。
今回は、FaaSの特性であるコールドスタートについて、どうにかならないか考えてみます。
概要
Slack Event APIのエラーハンドリング
SlackのEvent APIは、HTTP200を受け取れなかった際にエラーと判定し、都合3回リトライします。
受け付けるこちら側としては、極力エラーを発生させないようにしつつ、リトライが発生して処理が複数
回実行された場合においても、処理結果が問題とならないように、作り込んだ方が良さそうです。
Event APIのエラー判定
| 原文 | 内容 |
|---|---|
| we are unable to negotiate or validate your server's SSL certificate | SSLネゴシエートに失敗など |
| we wait longer than 3 seconds to receive a valid response from your server | 3秒以上待たされたとき |
| we encounter more than 2 HTTP redirects to follow | フォローしなくちゃいけないリダイレクトが2つ以上 |
| we receive any other response than a HTTP 200-series response (besides allowed redirects mentioned above) | HTTP2xx 以外のレスポンス |
エラー判定時のリトライ
| 原文 | 内容 |
|---|---|
| 1. the first retry will be sent nearly immediately | 即時 |
| 2. the second retry will be attempted after 1 minute | 1分後 |
| 3. the third and final retry will be sent after 5 minutes | 5分後 |
対策案の検討
インスタンスをアイドル状態にしておけないか
まずは最小起動数などで、インスタンスをアイドル状態にしておけないか調べてみました。
結論的には、出来なさそうです。
-
Cloud Functions
Cloud Functionsは、最大インスタンス数(--max-instances)はありますが、
最小インスタンス数に該当しそうなパラメタはなさそうですね。また、AWS LamdaのProvisioned Concurrencyのような機能も現時点では無いですね。
-
Cloud Run
Cloud Runの方は、最小インスタンス数を指定する --min-instancesというパラメタがありますが、
フルマネージドでは使うことが出来ないようです。以下はgcloud run deploy の結果。
ERROR: (gcloud.run.deploy) The
--min-instancesflag is not supported on the fully managed version of Cloud Run. Specify--platform kubernetesor rungcloud config set run/platform kubernetesto work with Cloud Run for Anthos deployed on VMware.ドキュメントの以下の部分がそれを表しているのでしょうか。わからんわ。
ただし、Cloud Run(フルマネージド)の場合、CPU は使用できません。
定期的に起こしてあげる。
やり方は色々あると思いますが、今回はCloud Monitoringの稼働時間チェックでやってみました。
完全にコールドスタートを封じ込めることは難しいですが、緩和という意味ではかなり効果があると思います。
-
Cloud Functions
実際に運用しているチーム向けの勤怠管理ボット(Cloud Functions)で試してみました。概要
Monitoringの稼働時間チェックを組み込み、定期的に関数を叩いてもらって、
なるべくインスタンスがお寝んねしないようにします。稼働時間チェックの設定
Monitoring - 稼働時間チェック - 稼働時間チェックの作成 より、作成します。
区分 項目 内容 デフォルト値 設定値 備考 タイトル タイトル 稼働時間チェックの名前 なし 任意 ターゲット Protocol ターゲットのプロトコルを指定 HTTP HTTPS ターゲット リソースの種類 URL ← ターゲット Hostname チェック対象のURLのベース部分(https://bba.com/articleであれば、bba.com) なし Cloud FunctionsのURL ターゲット Path チェック対象のURLのパス部分(https://bba.com/articleであれば、/article) なし 〃 ターゲット Check Frequency チェック間隔 1m 15m 一旦15分間隔で、運用しながらチューニング ターゲット Regions リクエストの送信元 グローバル 米国 Slack APIしか相手にしないので、米国のみでOK レスポンスの検証 Response Timeout リクエストが完了するまでの待機時間 10s 3s Slack APIのタイムアウト値に合わせる アラートと通知 アラートを作成する この稼働時間チェックが失敗したときに通知するアラートを作成するか On Off 稼働時間チェックの効果
稼働時間チェックを適用したボットは、勤怠管理ツールということもあり、
朝と夕方に処理が集中し、それぞれの間の数時間は全く使われないという
特性があります。適用前は朝or夕の最初の人がほぼ毎回タイムアウトを食らう状況でしたが、
適用後はかなり「緩和」することができました。適用前 適用後 タイムアウト発生頻度 1日に2回くらい 10日に1回くらい それでもタイムアウトする要因
パターン1 インスタンスが落ちている
稼働時間チェックで定期的に、関数を叩いてもらっても、インスタンスの居眠りは完全には防げませんでした。
インスタンスがお寝んねする条件については、ドキュメントからは明確な数値を見つけられませんでしたが、
1分間隔にしても寝るときは寝てしまっていたので、諦めるしかないですね。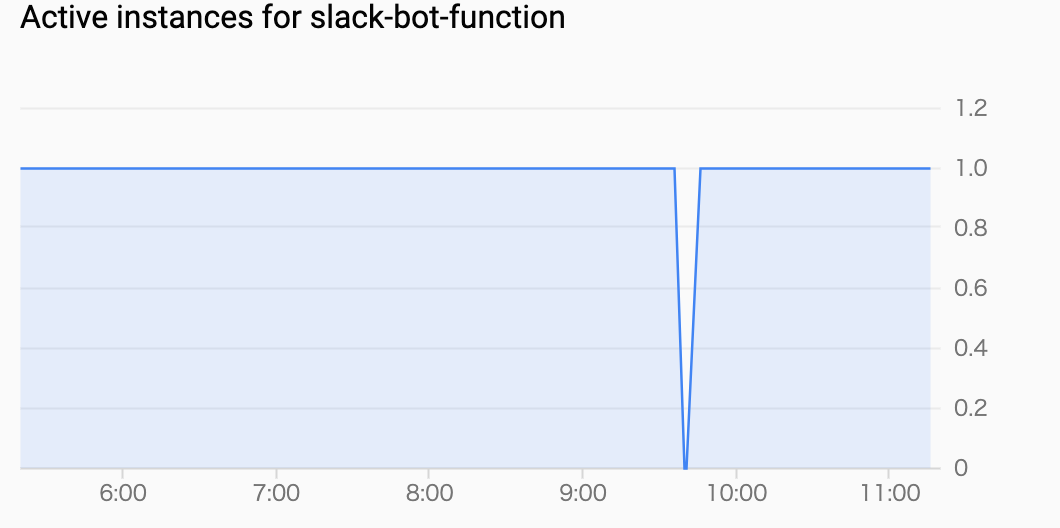
パターン2 新しくインスタンスが生成されている
ユーザのリクエスト同士や、ユーザのリクエストと稼働時間チェックのリクエストがかち合ったりなどして、
新しいインスタンスが生成されるケースも、1インスタンスあたりの多重度が1なので致し方ないですね。
また、最小インスタンス数のようなパラメタも無さそうなので、ある程度許容する他ないですね。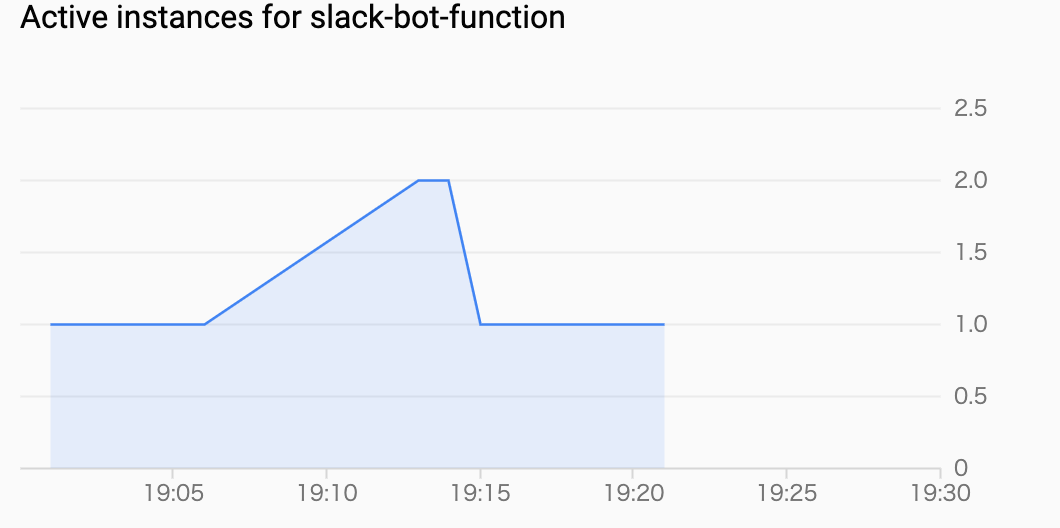
-
Cloud Run
Cloud Runもリクエストがないと勝手にインスタンスがお寝んねしてしまいます。
ただこちらは、少なくとも今回確認した限りにおいては、リクエストが来なくなって15分きっかりにインスタンスの停止処理が始まることがログ上確認できました。
ドキュメント上、明記されている訳ではないので、何とも言えませんが、ひとつの目安とすることはできそうです。Cloud Functionsと異なり、インスタンスごとに多重度の設定が出来ますので、
上記パターン2のような状況にはなりませんので、稼働時間チェックの間隔をなるべく
短くしてあげることで、ほぼほぼコールドスタートを封じ込めることが出来ると思われます。
測定
では実際に、Apache BenchでCloud FunctionsとCloud Runのパフォーマンスを測ってみます。
構成概要
ボットへのメンションを契機にEvent APIを発行し、Web APIでユーザが投稿したチャンネルへ返す感じにのシンプルな構成で、Cloud FunctionsおよびCloud Runをデプロイしてみました。
しかしながら、Apache Benchでの測定では、Event APIへのレスポンスを返すところまでとしました。
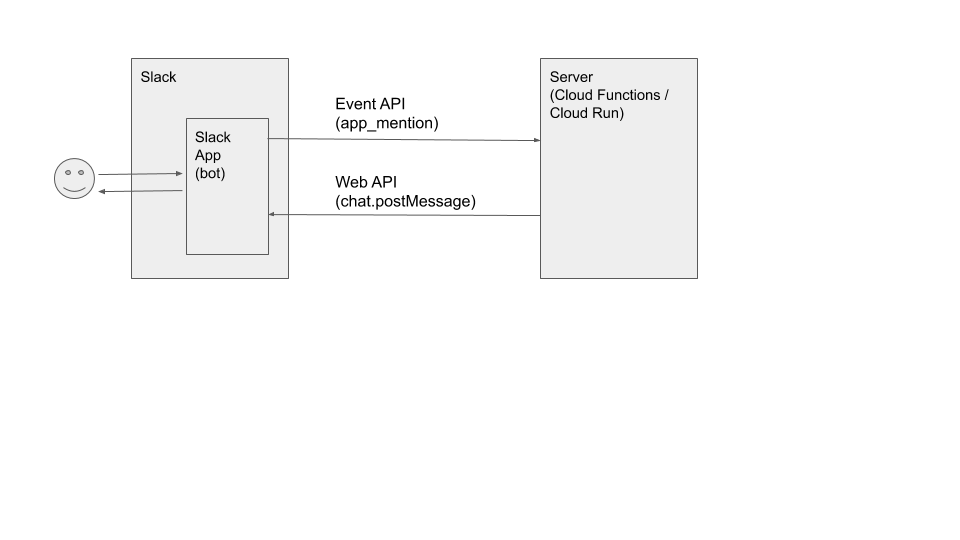
Slack Appsの設定(参考)
上記の構成で必要な権限は以下のとおりです。
| 区分 | 項目 | 設定値 | 備考 |
|---|---|---|---|
| OAuth & Permissions | Bot Token Scopes | app_mentions:read | ボットへのメンションを読み取り可能とする |
| OAuth & Permissions | Bot Token Scopes | chat:write | Web API経由でのチャットへの書き込みを許可 |
| Event Subscriptions | Subscribe to bot events | app_mention | ボットへのメンションを契機にEvent API発砲 |
ランタイムやフレームワークなど
Functionsは素で入っているFlaskとし、Runの方はFlaskと、興味本位でFastAPIで比べてみることとします。
| 項目 | Cloud Functions | Cloud Run (Flask) |
Cloud Run (FastAPI) |
|---|---|---|---|
| ベースイメージ | Ubuntu 18.04 | python:3.8-slim-buster | ← |
| ランタイム | Python3.8 | ← | ← |
| Webフレームワーク | Flask 1.0.2 | Flask 1.1.2 (gunicorn20.0.4) |
FastAPI 0.61.1 (uvicorn0.11.8) |
| サードパーティライブラリ | Requests 2.21.0 | Requests 2.24.0 | ← |
拙いですが、検証用コードです。
一応、ちゃんと動作します。
チューニングパラメタ
Functionsはインスタンス数を自動 or 1、Runの方はインスタンスは1で固定とし、インスタンスあたり20多重で比べてみることとします。
| 項目 | Cloud Functions | Cloud Functions | Cloud Run (Flask) |
Cloud Run (FastAPI) |
|---|---|---|---|---|
| リージョン | us-east4 | ← | ← | ← |
| CPU(インスタンスあたり) | 500ms | ← | 1 | ← |
| メモリ(インスタンスあたり) | 128MiB | ← | 256MiB | ← |
| 最小起動インスタンス数 | - | ← | - | ← |
| 最大起動インスタンス数 | auto | 1 | 1 | ← |
| 多重度(インスタンスあたり) | 1 | ← | 20 | ← |
負荷がけ条件
以下のような組み合わせで、Apache Benchから負荷がけしてみます。
| 同時実行数 | リクエスト数 |
|---|---|
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
| 5 | 500 |
| 10 | 1,000 |
結果
負荷がけにあたっては、以下のようにコールドスタートから始まるようにしています。
- Cloud Functions : 毎回デプロイしなおしてから
- Cloud Run : 毎回15分以上待って、インスタンスが停止したことを確認してから
-
スループット(秒あたりレスポンス)
大体想定とおりの結果となりました。
Cloud Functionsは、同時実行数が増えるに従い、新たなインスタンスを起動してスケーリングしますので、
同時実行数が増加に伴い、劣化していきます。
FlaskとFastAPIでは、ややFastAPIの方が良さそうです。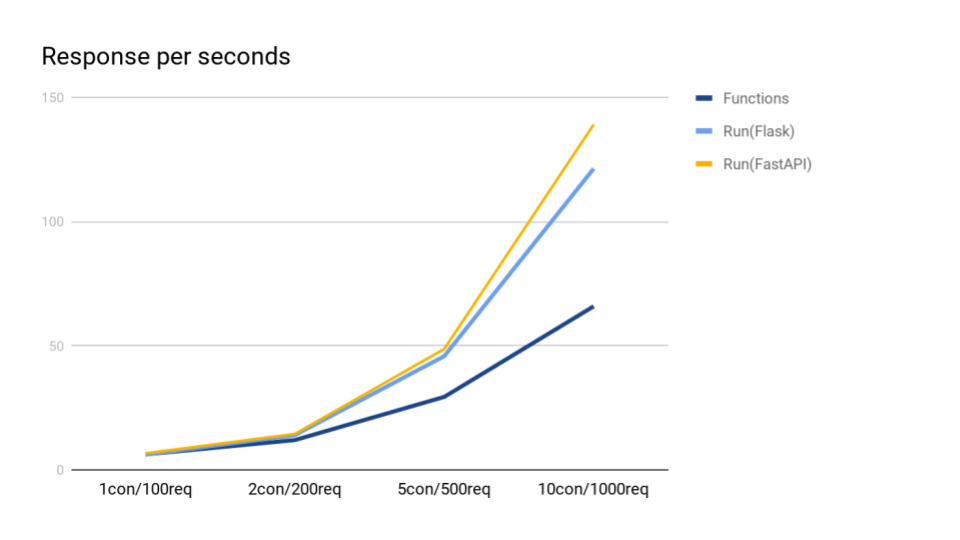
-
平均レスポンス(ミリ秒)
スループットと同様です。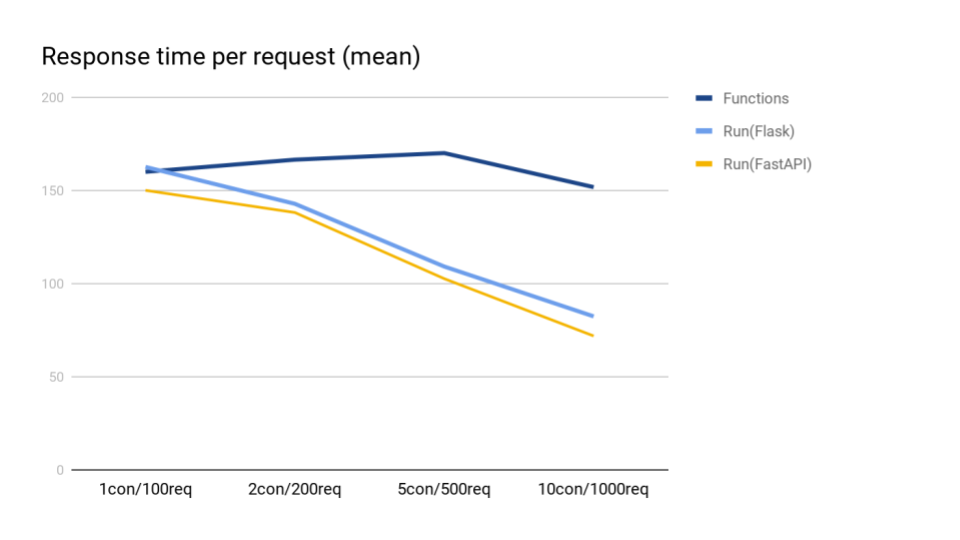
-
99パーセンタイル(ミリ秒)
あくまで今回の環境設定においてですが、インスタンス数を増加して同時実行数を増やすしかない
Cloud Functionsと比較して、Cloud Runでは最初のコールドスタートさえなんとかすれば、
以下のようにかなりの低レイテンシーを実現することができそうです。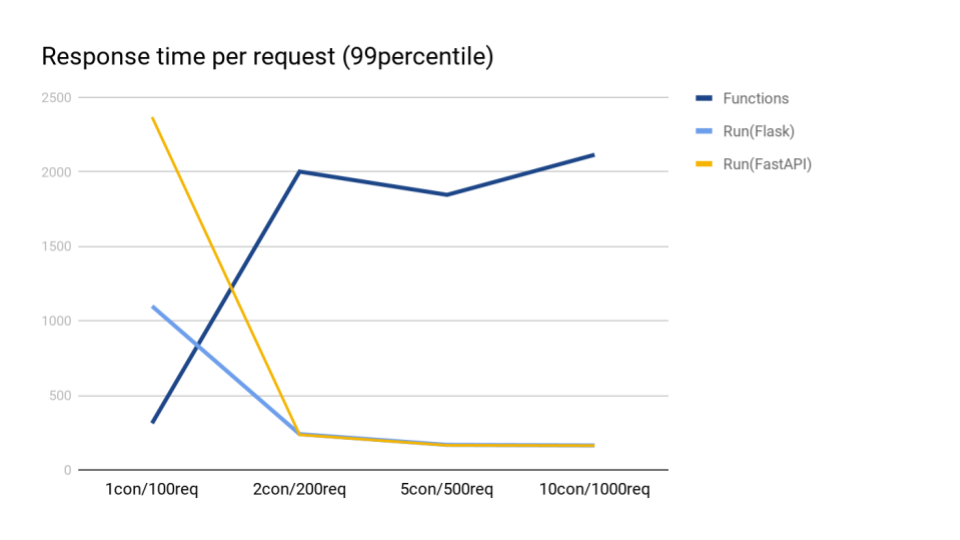
-
インスタンス数
Functionsのインスタンス数は、同時実行数10のときには、15までいってました。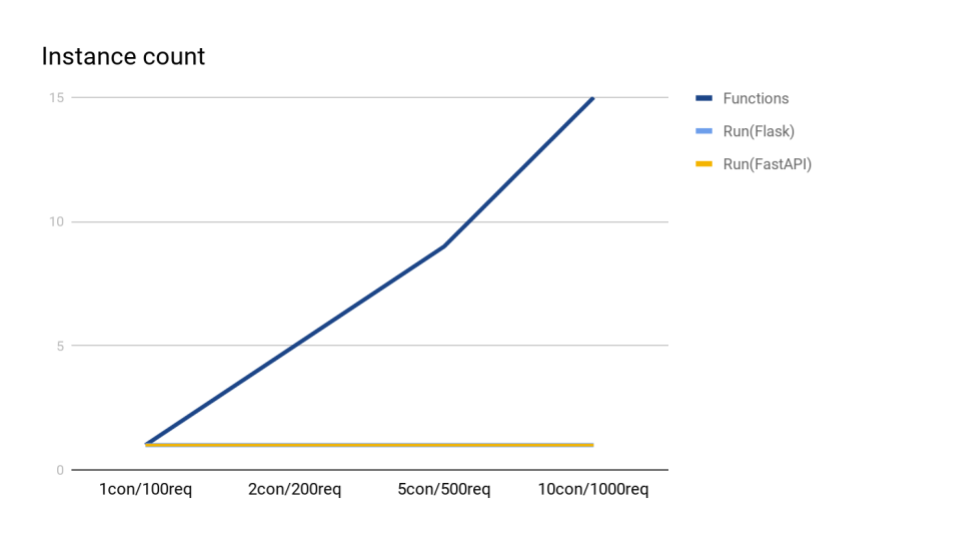
-
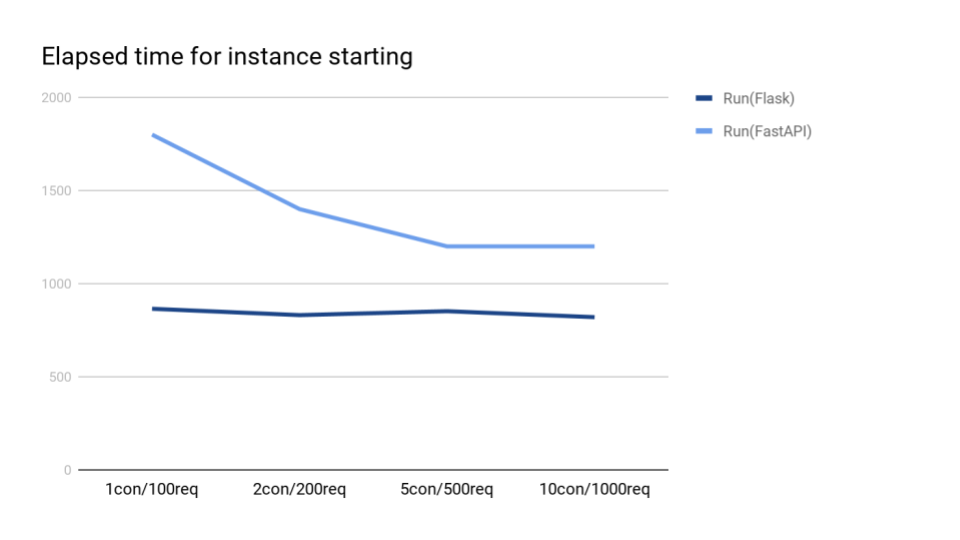
インスタンスの起動にかかる時間
ログで確認ができるCloud Runのみグラフ化してみました。
こちらは、Flaskの方が良さそうです。とりあえず、さくっと作った環境なので、色々と削ることは出来ると思います(ドキュメント)。
結論
Slackボットのように、そこそこ厳しいレイテンシーが要求され、かつ、それなりの同時実行が想定される場合においては、
ほぼほぼコールドスタートを封じ込むことが出来そうな、Cloud Runで実装するほうが良さそうです。
ただし、あくまで私のように、インスタンスの自動スケールが不要な場合に限られますね。