こちらのページはビッグデータ向けプラットフォームに入門するの子記事です。
next: ビッグデータ向けプラットフォームに入門する - Hadoop
DWHはいわゆる「データの倉庫」です。
時系列データを格納することを目的とし、分析・集計(OLAP)用途に特化したRDBです。
オペレーション(OLTP)用途で用いられる一般的なRDBとは大きくことなる点として以下の2つが挙げられます。
- 列指向DBであること
- MPPを採用している(ことが多い)こと
この2つの特徴によりDWHは「分析に特化している」といえます。
列指向DB
簡単な例として、ショッピングサイトで扱うデータについて考えましょう。
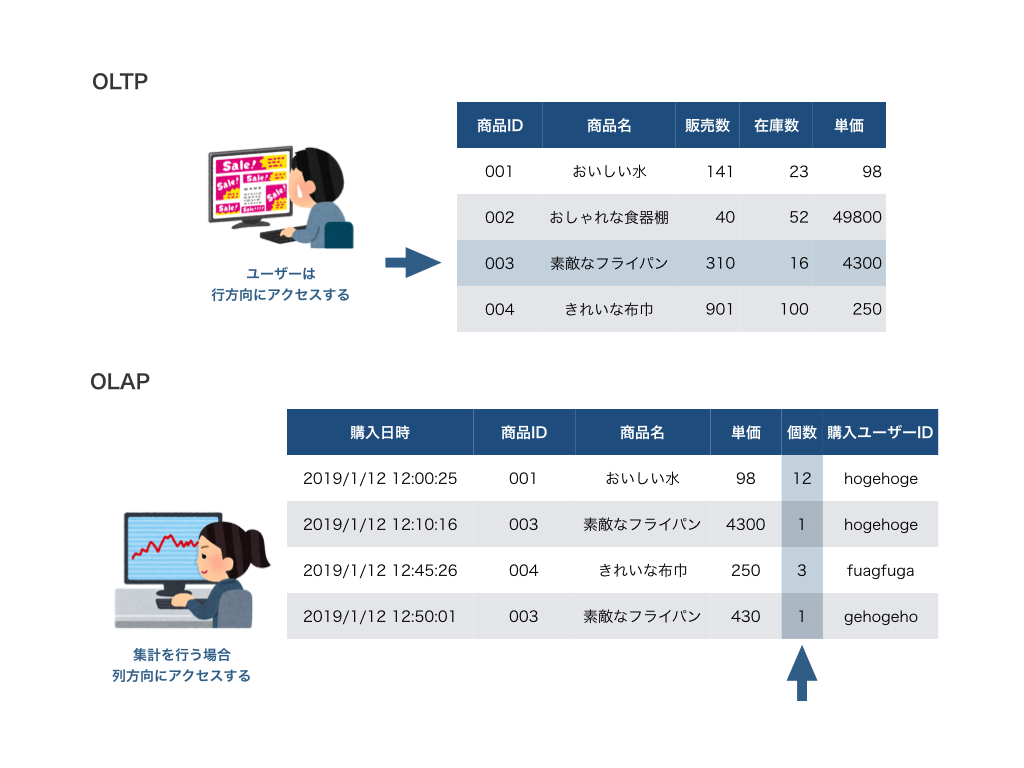
ある商品についての情報にアクセスする場合、その商品についての行を参照することになります。
また、新たな商品を登録したり、購入処理後に在庫数を変更する場合も行単位のアクセスとなります。
OLTP用途のRDBではこのように行単位でレコードのR/Wを行うことに特化し、行指向のDBとなっています。
一方商品数を集計するような場合、列方向にアクセスを行うことになります。
このように集計・分析を行う場合は列単位でのアクセスを行うことになります。
このような列方向でのアクセスに特化しているのが列指向DBです。
列指向DBではカラムごとにデータをまとめて保持しているため、
集計の際に必要なカラムにのみまとめてアクセスでき、高速に集計を行うことができます。
さらに、列指向DBは圧縮効率が高いという長所もあります。
これは列方向には同じ型のデータが並び、かつ似た値が入ることが多いためです。
また図からもわかるように、OLAP用途のDBでは格納するデータの構造(スキーマ)も異なります。
RDBでは図のような現在の状態を示すレコードが保持される一方、DWHでは購入履歴のような時系列のデータが格納され、基本的に更新処理が行われることはありません。
またRDBでは正規化が行われた形式でデータを格納しますが、
一般的にDWHでは集計効率を考えて非正規化が行われた冗長な状態でデータが格納されます。
MPP
近年では多くのDWHがMPP(Massive Parallel Processing)と呼ばれる処理方式を採用しています。
MPPでは1システムが独立した複数のCPU, メモリ, ストレージを持ち(=shared nothing architecture)、
分散してデータの保持及び処理を行います。
メモリ・ストレージを共有しないため処理中の競合が発生せず、高速に分散処理を行うことができるという特徴があります。
また、後述するHadoopやNoSQLなどの分散ストレージほど容易ではないものの、スケールさせることが可能です。
MPPについては、DWHの一つであるTeradataのアーキテクチャについての記事がわかりやすいです。
(https://www.teradata-jp.com/single-post/col05b)
DWHの特徴・プロダクト
DWHは列指向ストレージ、MPPにより、分析・集計を非常に高速に行うことができ、
大容量でスケールが可能なRDBです。一方でOLTP用途で使うことには向いていません。
またRDBであるためACID特性を有し、データの整合性を保証しています。
なおNoSQLの節で触れますが、データの整合性を担保しつつ、分散処理を行い十分な性能を持たせることは本来困難です。
前述の特性に加え、データの格納の仕方も工夫することでDWHでは効率的に分散処理を行うことができます。
具体的には非正規形でデータを格納してデータ間の依存を減らし、
なおかつ更新処理は基本的に行わずに追加のみ行うことで、処理を分散しやすいようにしています。
このデータの更新を行わない、というのは現在の状態を保持するのではなく時系列の記録を格納するという目的と合致しています。
DWHは一般的にソフトウェアとハードウェアが一体となった形で提供されており、
代表的なプロダクトはhttps://www.trustradius.com/data-warehouse から見ることができます。