先日個人で開発していた"Muniverse"というサービスをローンチしました。
https://muniverse.app (PC推奨)
音楽の宇宙を探検できるサービス"Muniverse"をローンチしました🎉https://t.co/x7XtAROnt1
— mito (@m110h5rb) May 8, 2020
Wikipediaのデータを抽出して音楽ジャンル間の関係を可視化、その起源や派生ジャンルを辿れるようになってます。
曲の試聴もできるので、家にこもりがちの今、自分のまだ知らない音楽を発掘してみては? pic.twitter.com/uKg7vLnd7A
せっかく頑張って作ったので、技術的な内容と開発にあたって感じたことを記録しておこうと思います。
サービス概要
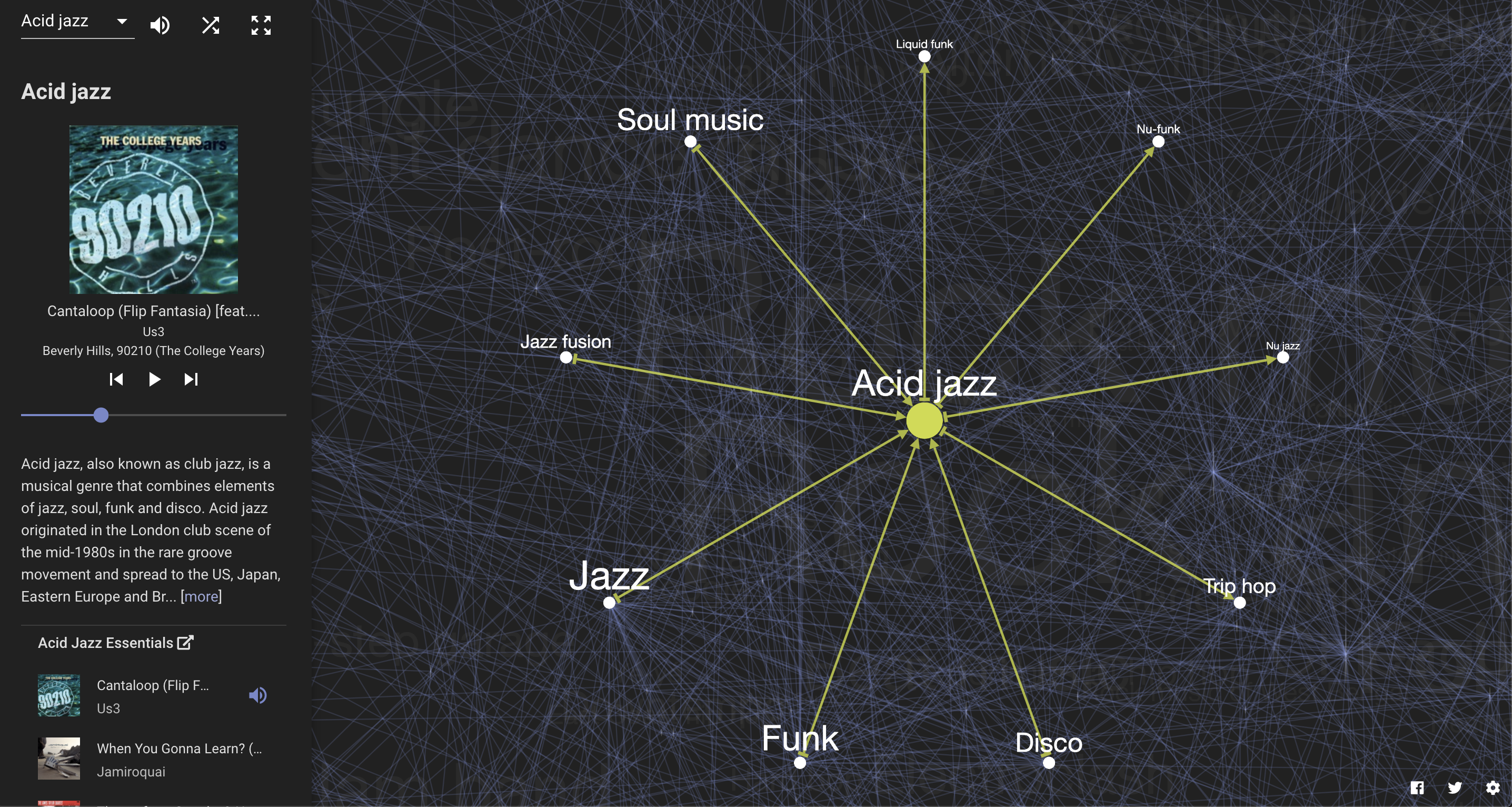
Muniverseは、音楽のジャンルの関係をグラフ構造で可視化し、各ジャンルの派生ジャンルやその起源となったジャンルを順番に辿ることができるサービスです。
各ジャンルの曲の試聴も行えるため、自分の好きな音楽ジャンルから他のジャンルへと辿っていったり、シャッフル機能を使って全く未知のジャンルに出会ってみたりと、音楽の宇宙を探検しつつまだ知らない新たなお気に入りの音楽を見つけることができます。
システム概要
GCPを中心としたシンプルな構成です。

まず、Muniverseの根幹を担うグラフ構造のデータは、Wikipediaの情報を構造化して持っているDBPediaから抽出しています。
抽出したデータはCloud Firestore上にキャッシュし、このデータを使ってCytoscape.jsでグラフ構造の可視化をおこなっています。
また、各ジャンルの代表曲の情報はApple Music APIから取得しています。曲の再生等の処理はMusic Kit JSにより実施しています。
実行環境はGKEを使っています。WebフレームワークはFlask + Vue.jsを使っています。
後でも触れますが、技術選定等は結構適当です。自分の使ってみたいものを適当に使った結果こうなりました。
詳細内容
データ抽出
Muniverseのグラフは、各ジャンルをノードとし、派生元から派生先に伸びるようエッジを定義した有向グラフです。
各音楽ジャンルから派生したジャンル、およびその起源となったジャンルは、以下のページのように記事中に定義されています(サイドバーの"Derivative forms", "Stylistic origins"の内容がこれにあたります)。
これらの情報はWikipediaのページを直接クロールすることでも抽出できますが、今回はDBPediaを使っています。
DBPediaではWikipediaの記事データをRDF(Resource Description Framework)形式で構造化し公開しています。
(ちなみに今回は日本語版のWikipediaを対象としたDBPedia Japaneseではなく、英語版を対象としたDBPediaを使っていますが、これは単純に音楽ジャンルの記事の数・情報量が日本語版より多いためです。)
RDFについての詳しい解説は他に譲りますが、一言で言えばsubject(主語)、predicate(述語)、object(目的)により構成されるtripleというモデルで情報を情報を表現しています。
例えば、"Funkの派生がDisco"である、という情報は以下のような形式で記述されます。
| subject | predicate | object |
|---|---|---|
| Funk | derivative | Disco |
RDF形式のデータは、SPARQLというSQLライクなクエリ言語で検索ができます。
先程のデータの問い合わせを行う場合は、以下のようなクエリとなります。
PREFIX resource: <http://dbpedia.org/resource/>
PREFIX ont: <http://dbpedia.org/ontology/>
SELECT ?resource WHERE {resource:Funk ont:derivative ?resource.}
このようなSPARQLでのDBPediaへの問い合わせは、DBPediaで公開されているエンドポイントから試すことができます。
データ変換・ロード
抽出したデータは整形し、後にグラフとしての可視化を行いやすいようキャッシュしておきます。
具体的には以下のような流れでデータの構造化を行っています。
- SPARQLで音楽ジャンルの記事(リソース)一覧を取得
- SPARQLで各リソースの派生・起源に対応するリソースを取得、隣接リストに登録していく
- このとき、取得した派生・起源となるリソースが音楽ジャンルでないことがあるのでこれを除外
- 全体が連結グラフとなるよう、孤立したジャンルを除外
- これまでの手順だと、派生情報が無い孤立したジャンルや、2つのマイナーなジャンル同士がつながっているような小さな連結成分が残ってしまう。このためDFSでグラフの連結成分を列挙し、ノード数が最大のもの以外を削除する。
ちなみに、出来上がったグラフはノード数844、エッジ数3068でした。これなら多少効率の悪いアルゴリズムでも問題はなさそうです。
こうして変換されたデータに、記事の文面の一部などの付加情報を加えて永続化します。今回のケースではドキュメントDBが使いやすそうだったのでCloud Firestoreに保持しています。
以上のDBPediaから抽出・データ整形・Cloud FirestoreまでのETL処理はPythonでスクリプトを組んで、Compute Engine上でバッチで処理させています。
データ可視化
今回グラフの可視化にはCytoscape.jsを使っています。
Cytoscape.jsでは以下のようにノードとエッジの情報を定義して渡すことで、
elements: {
nodes: [
{
data: { id: 'a' }
},
{
data: { id: 'b' }
}
],
edges: [
{
data: { id: 'ab', source: 'a', target: 'b' }
}
]
}
このようにグラフの可視化を行うことができます。

可視化のスタイルはもちろん、ノードの選択などのイベントをトリガーとした関数やアニメーション等を定義することができます。
Muniverseでは、Cloud Firestoreから取得した情報を元にグラフを可視化するとともに、ノードを選択した際に、関連先情報をまとめるアニメーションを表示し、選択されたジャンルのプレイリストをApple Music APIにリクエストするトリガーを定義しています。
Cytoscape.jsのパフォーマンス最適化
上述の通り、今回のグラフはノード数844、エッジ数3068あり、これを描画させると結構重たいです。
自分の環境ではレンダリングに5秒以上かかり、アニメーションもだいぶカクついているような状態だったため、以下のような対策を行いました。
- ノードの位置の固定
- ノードをバランスよく配置させるためCoSE(Compound Spring Embedder)レイアウト(各エッジをバネに見立てて、バネの釣り合う位置を物理的にシミュレートしてノードをの位置を決める)を採用している
- クライアントサイドでのバネの計算を避けるために、事前計算して実際には固定位置にしておく
- レンダリングを軽量にするためオプションを調整
- エッジのスタイルで、 bezier曲線や矢印はレンダリングのコストが高いので、ノードが選択されたときのみ描画する
- ラベルも同様に高コストなため、ある程度のサイズ以上の場合のみ表示
またこれらの対策を行ってもまだ満足できるパフォーマンスは得られなかったので、思い切ってノード数を減らすことにしました。
以下は各ノードの次数(接続するエッジの数)のヒストグラムです。
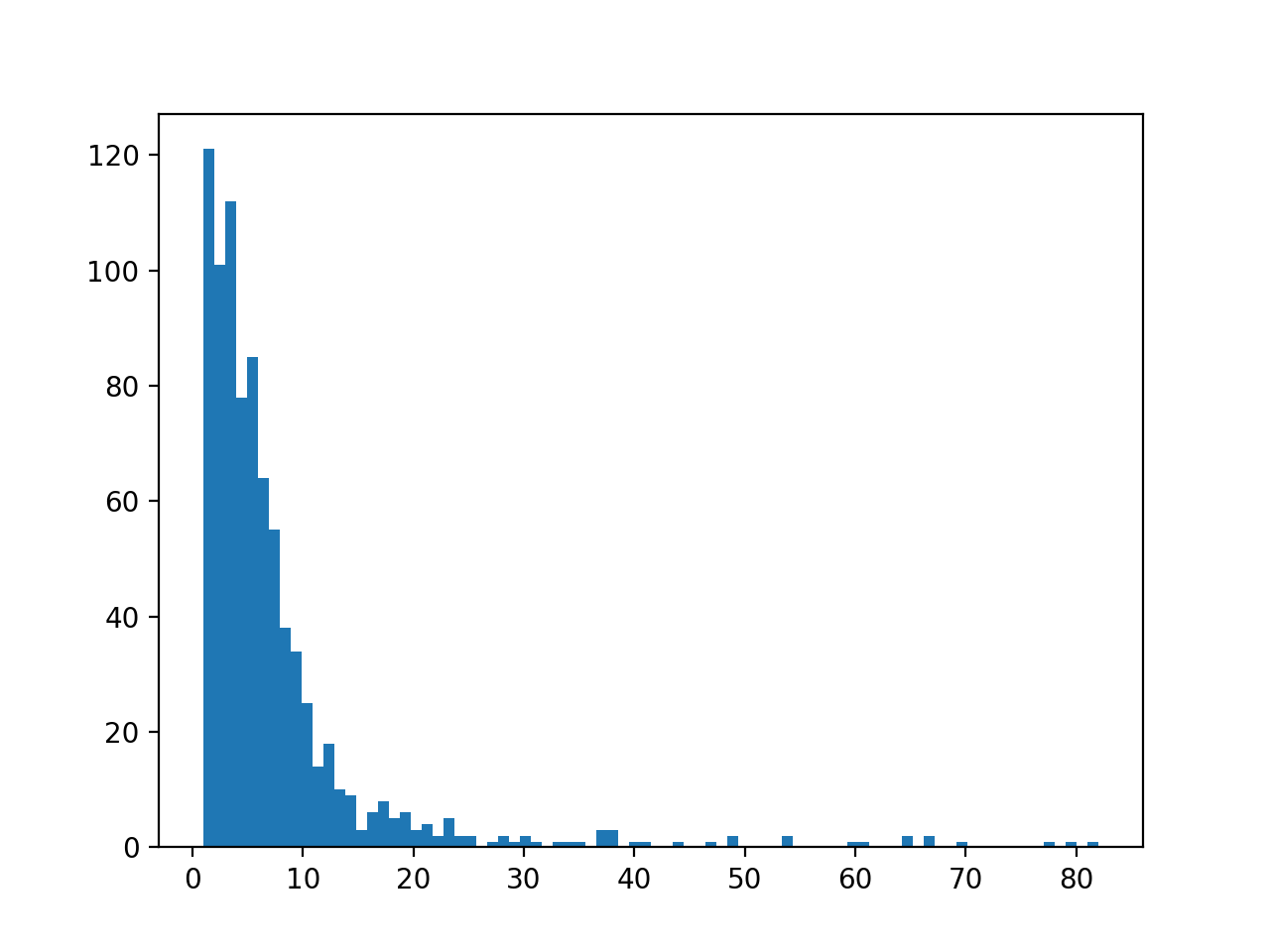
ここから、接続するエッジの数が1つしかないジャンルが120以上あることがわかります。また、半分近くが次数4以下であることがわかりました。
そこで次数4以下の比較的マイナーなジャンルと、連結するエッジをグラフから削除することにしました。これによりノード数は510, エッジ数は2470まで減り、パフォーマンス的にも及第点となりました。ただ、マイナーなジャンルを含めて閲覧したい場合もあると考えたため、重くはなるけど全ジャンルも表示するよ、という形に切り替えられるよう実装しました。
各ジャンルの曲の取得・再生
Muniverseでは、グラフの可視化に加えて各ジャンルに対応する曲を試聴する機能があります。
今回はMusicKit JSを使ってApple Musicにある曲を取得し、試聴する機能を実装しています。
本来MusicKit JSは、Apple Musicに登録しているユーザーがApple IDで認証を行い、Webページ上で音楽の再生等を行うことを目的としていますが、Apple Musicの登録者でなくても使えるよう今回は使っていません。単純にApple Music APIでplaylistをジャンル名で検索し、対応するplaylistの各曲の冒頭30秒を試聴させる形をとっています。
MusicKit JSは公式ドキュメントがお世辞にも親切とは言い難いのですが、以下のようなMusicKit JSを実際に使っているサイトが既にいくつかあり、その実装が参考になりました。
またプレイヤー自体のUIは自前で用意する必要があったので、Vuetifyを使ってしこしこ書きました。
システムの構築
上記の方法で実装することで、各機能を実現できることはわかりました。あとは実際にWebサービスを構築していくだけです。
ページは1枚だけで機能も限られているため、軽量なフレームワークであるFlaskを採用し、UIについては部分的にVue.js(+Vuetify)を使っています。(最初はpureなECMAScriptでクライアントサイドを書いていましたが、途中でしんどくなってきたので一部を切り替えました。今思うと全部統一すればよかった感あります)
また実行環境としてはGKEを使っています。こちらも最初はもっと原始的な構成で、GCE上にNginxをインストールして、Flaskを起動して、UWSGIを使ってつなげて、、といった形で環境をつくっていましたが 、デプロイが面倒なのとスケールしない問題があったのでGKEに切り替えた、という経緯を辿っています。
GKEは今回のシステムの要件から見ると完全にオーバースペックなのですが(別にGAEやFirebaseでも問題なさそう)、単純にk8sで1からシステム作りたいなーというだけで採用しました。実際k8sの勉強にはなりましたが、GKEは趣味の個人開発のサービスには向かないかと思います(お値段的な問題で)。
GKEは基本的にはクラスタ管理料金+ワーカーノードに使うGCEの料金で、かつゾーンクラスタ1つまでは管理料金が無料なので、単純にGCEを借りるのと料金的にはさして変わらなそうな印象なのですが、メモリ、ノード数に制約がある(ショボすぎるとそもそもk8sを乗っけられない)ことや、HTTPロードバランサ(まあまあする)が必要なため、可能な限り最小の構成(g1-small2台)でもそこそこのお値段はかかります。
https://cloud.google.com/kubernetes-engine/docs/concepts/cluster-architecture?hl=ja
https://cloud.google.com/kubernetes-engine/docs/tutorials/http-balancer?hl=ja
ので、頃合いを見てプラットフォームは移そうかと思っています。
現状の課題・今後
やる気がでたら対応したいなーというもの
- Apple Music APIからplaylistを取得する際、単にジャンル名で検索を行っているだけのため、ジャンルと正しく対応していないことがままある。結構変なplaylistになったり、そもそもなかったりする
- マニュアルで決めたほうが良さそう
- しかし全てのジャンルのplaylistを手動で決めるのは大変すぎるので、何かしらの形でフィードバックを受けられるようにしたい
- モバイル対応を全く考えていなかったので、いい感じにする
感想
もともとはLinked Open Dataについて耳にした際に、DBPediaのデータを使って関係グラフの可視化ができそうだな、と思ったのがきっかけでした。最初は可視化してみるだけのつもりでサービスとして公開するつもりはなかったのですが、思ったよりきれいだったのでいっちょサービスにしてみるか、という形でプロジェクトをはじめました。
実装にはなんだかんだ100時間くらいかかったと思います。自分は普段はサーバーサイドしか触らないのでフロントの知識が薄かったり、シンプルなCRUDアプリケーションとは性質が異るため参考にしやすい先例が少なかったり、利用するフレームワークや環境がころころ変わったことが長時間かかった原因かなと思っています。
気になっていた技術を色々試せたことは良かったと思っています。スピードを重視して既知の技術スタックで開発するか、勉強も兼ねて触ってみたかった新しい技術を使うかという点で少し悩みましたが、やはり多少は新規技術を使ったほうがやっぱりやってて楽しいです。ただその結果ローンチまでの時間が伸びると途中で飽きたり頓挫する可能性がかなり高まるので、勉強を兼ねる場合もスコープと期限をはっきりさせ、不完全な状態でもリリースして継続的に更新するのがいいかなと思いました(実際自分も何回も頓挫しかけました)。
もう一つ悩んだ点としては、保守性に関する部分を真面目に書くか(アーキテクチャに凝るとかdeployment pipelineをしっかり組むとか)、動けば良しで適当に書くかという点でした。最初後者のスタンスで書いてたのですが、いくら小規模とはいえ雑な設計・雑なコードが積み重なると、開発スピードが結果的に下がるし、ストレスも溜まるしなので、最低限必要な保守性は考慮して進めたほうが良いと思いました(ぼくのかんがえたさいきょうのパイプライン、は必要が無いけど、コマンド一つでデプロイとロールバックはできるようにしておくなど)。ここらへんを真面目にやらないとどういうことが起きるか、というのを身を持って体験できたのは良い学びだったかもしれません。
ただ、とにもかくにも公開まで至ってよかったというのが率直な感想です。
もしサービスを利用していただけたり、機能追加やバグ報告など各種フィードバックいただけるとめちゃくちゃ喜びます。ここまで読んでいただきありがとうございました。