「このクエリくっそ重すぎワロタw」となった時、いくつかチューニングをして、効果測定をします。
その時に、圧倒的に速くなっているならまだしも、数%の改善であれば、何度も実行しないと誤差であることを拭いきれません。
PythonからMySQLにつないで、数10回~数100回同じクエリを叩いて、2つのクエリ(この場合だと改善前と改善後)の処理時間を比較してみましょう。
環境
- OS: Mac El Capitan
- Python : 3.6.2
- MySQL : 5.7.18
mysqlclientのインストール
pip install mysqlclient
必要なパッケージをimport
%matplotlib inline
import MySQLdb
import time
import numpy as np
import matplotlib.pyplot as plt
MySQLに接続
※ Jupyter notebookから書いています。
connection = MySQLdb.connect(user='db_user', host='db_host', db='db_name', password='db_password')
cursor = connection.cursor()
クエリを書く
とりあえず、query1を改善前、query2を改善後のクエリとしましょう。(まぁ普通に全く違うクエリですが)
query1 = "SELET * FROM sample"
query2 = "SELECT COUNT(*) FROM sample WHERE category = 999"
2つのクエリを100回ずつ実行
time.timeでそれを実行した時の時間が取れます。それをクエリ実行前と実行後で取得して、引き算をしてあげるだけです。
exec_count = 100
x_axis = np.array(range(0,exec_count))
sql1_results = np.array([])
sql2_results = np.array([])
for i in range(0, exec_count):
start = time.time()
cursor.execute(sql1)
end = time.time()
sql1_results = np.append(sql1_results, [end-start])
for i in range(0, exec_count):
start = time.time()
cursor.execute(sql2)
end = time.time()
sql2_results = np.append(sql2_results, [end-start])
計測結果を折れ線グラフで可視化
matplotlibを使って可視化してあげます。
x_axis = np.array(range(0,exec_count))
p1 = plt.plot(x_axis, query1_results, linestyle="solid")
p2 = plt.plot(x_axis, query2_results, linestyle="dashed")
plt.legend((p1[0], p2[0]), ("query1", "query2"), loc=2)
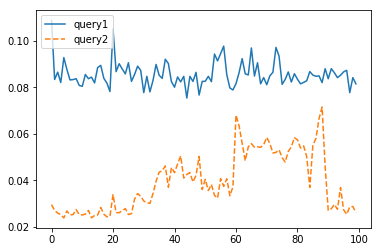
そうするとオレンジの折れ線(改善後)のほうが速くなっていることが一目瞭然なわけです。
アベレージでみると
np.average(query1_results) # 0.085642900466918942
np.average(query2_results) # 0.039277324676513674
query2のほうが1/2以上速いという結果になります。