前回に引き続き、Udemy【世界で74万人が受講】基礎から理解し、Pythonで実装!機械学習26のアルゴリズムを理論と実践を通じてマスターしようで学んだ内容をアウトプットしていきたいと思います。
(※この記事は勉強した内容のアウトプットを目的としてざっくりと書かれているので、もともと知っていて復習の為に読んだりするにはいいと思いますが、正しく知りたい方は別の記事を読んだほうが良いとおもわれます。コードに関してはライブラリが入っていれば、jupyterなどにコピペすればだいたい動くはずです。)
前回、記事にしたクラスタリングからDeep Learningに至るまで、Association rule learning、強化学習、自然言語処理があったのですが、ここで例題として扱うのに丁度良いデータセットが見つからなかったので、飛ばしてます。今後、手頃なデータセットが見つかればまた取り上げるかもしれません。
ANN(Artificial Neural Network)
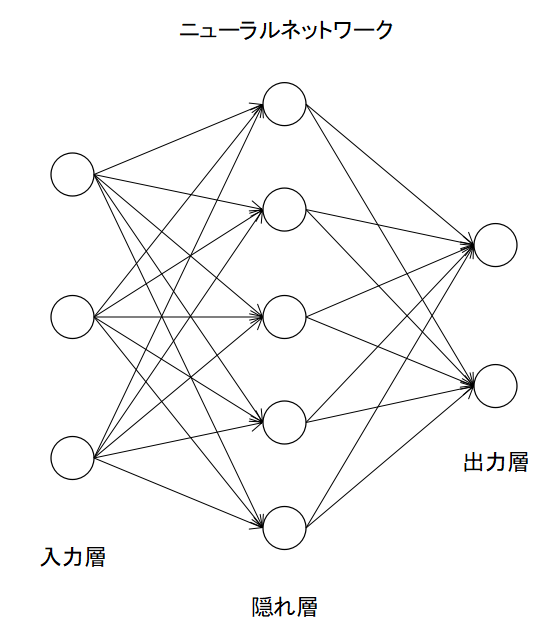
ニューラルネットワーク(ANN)とは脳の神経回路の一部を模した数理モデル(ニューロン)を複数組み合わせたものの総称で、入力層、出力層、隠れ層から構成される。
ニューロン
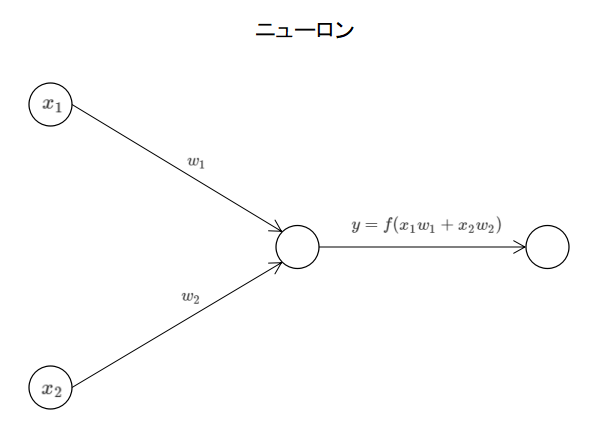
ニューロンとは複数の入力(下図では2つ)に対し活性化関数を使って演算を行い出力を行うノードのことです。出力をしたニューロンは別のニューロンの入力にもななり得ます。
活性化関数
活性化関数とはニューロンに入って来た入力に対して演算処理をするもので、上記の図の$y = f(x_1w_1+x_2w_2)$の$f()$にあたるもので、代表的なものとしては以下のような種類がある。
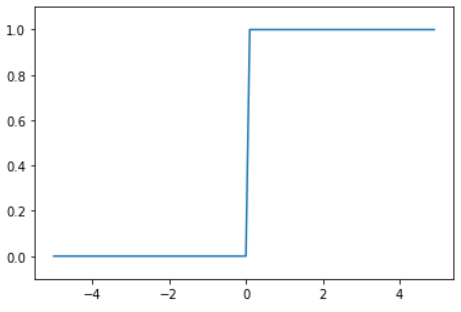
・ステップ関数
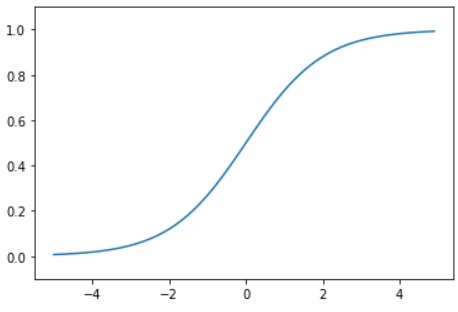
・シグモイド関数
・Relu関数
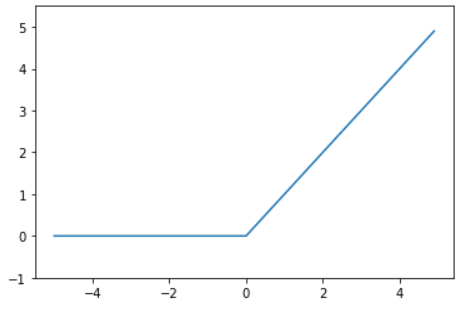
損失関数
モデルから出力された値と実際の正解を比較してその差を計算する関数で、この差を小さくなるようにする事でモデルを最適化することができます。
モデルからの出力値
$$ y = f(x_1w_1+x_2w_2) $$
正解の値
$$ \hat{y} $$
損失関数
$$ C = 1/2(\hat{y}-y)^2 $$
Cを最小化するように$w_1, w_2$を調整する事でモデルが最適化されます。
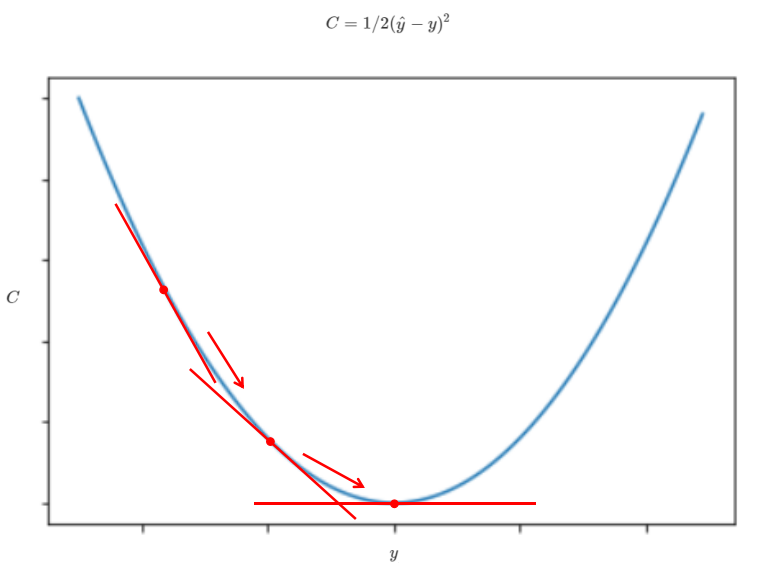
勾配降下法
損失関数を$ C = 1/2(\hat{y}-y)^2 $の$C$を最小値を見つけるために、下図のように関数の接線の傾きを小さくしていく事でCの最小値を割り出す方法
とりあえず、ここでも学んだ内容で、分類のときにも使ったScikit-learnのデータセットの乳がん患者を使って、target以外のデータを独立変数、target(悪性or良性)を従属変数としてロジスティック回帰を使った分類をしたいと思います。
ライブラリのインポート
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score
データセットの読み込み
cancer = load_breast_cancer()
cancer_data = pd.DataFrame(cancer.data, columns = cancer.feature_names).assign(malignant=np.array(cancer.target))
X = cancer_data.iloc[:, :-1].values
y = cancer_data.iloc[:, -1].values
フィーチャースケーリング
sc = StandardScaler()
X = sc.fit_transform(X)
訓練用データセットとテスト用データセットへの分割(8:2)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
ANNの構築
ann = tf.keras.models.Sequential()
ann.add(tf.keras.layers.Dense(units=30, activation='relu'))
ann.add(tf.keras.layers.Dense(units=30, activation='relu'))
ann.add(tf.keras.layers.Dense(units=1, activation='sigmoid'))
ann.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
訓練用データセットを使った学習
ann.fit(X_train, y_train, batch_size=32, epochs=50)
出力結果
Epoch 1/50
15/15 [==============================] - 0s 1ms/step - loss: 0.6230 - accuracy: 0.6901
・・・
(省略)
・・・
Epoch 50/50
15/15 [==============================] - 0s 1ms/step - loss: 0.0156 - accuracy: 0.9978
テスト用データセットを使った結果の予測
y_pred = ann.predict(X_test)
y_pred = (y_pred > 0.5)
print(np.concatenate((y_pred.reshape(len(y_pred),1), y_test.reshape(len(y_test),1)),1))
出力結果
[[0 0]
[1 1]
[1 1]
・・・
(省略)
・・・
[0 0]
[0 0]
[1 1]]
混同行列と精度スコアでモデルの評価
cm = confusion_matrix(y_test, y_pred)
print(cm)
accuracy_score(y_test, y_pred)
出力結果
[[46 1]
[ 1 66]]
0.9824561403508771
CNNに関しても講座でならったのですが、ややこしくなるので今回はこのへんで終わります。