あまり目立っていない、地味に追加された機能によって殺されてしまいました ![]()
よし!Rails6アップデートリリースするぞ! 
bundle update railsを実行し、テストが全て通るよう修正し、Warningを潰し、stagingで入念に動作確認しました。
そして、もう大丈夫!productionリリースしてもいいよね! と、リリースへの機運が高まりきったところで事件は起きました。
productionだけど社内用のクローズドな環境へリリース
全体のproductionへリリースする前に、社内用の隔離されたproduction環境へリリースしてみました。
無事リリースが成功し、「ふんふん、まあ大丈夫そうかな??」と触っていたら、急に503エラーが発生してうんともすんともいわなくなりました。
エラー監視(Sentry)を見ても、特にアプリケーションエラーが発生したような痕跡はなさそう。
何が起きたのかと思って急いでアプリケーションサーバへsshしてアプリケーションログを見てみました。
が、特にめぼしいエラーは見当たらず。。 ![]()
原因を探っていると、急にsshが遮断されました。
どうやらインスタンスがterminateされた模様。。
え?なんかヤバイことしちゃった? 
さすがに焦りました。
社内用のクローズドな環境なので影響範囲は社内に限られるのが不幸中の幸いでした。
社員のみなさんにごめんなさい![]() して、調査を継続しました。
して、調査を継続しました。
AWSコンソールからterminateされたインスタンスの情報を見てみても、CPU使用率やメモリ使用率などが異常に上がっているということはなさそうでした。
そして、**「おっ復旧したみたい」**という声が社内から上がってきました。
えっ?何もしてないけど??? 
原因も分かってないし、何もしてないのに、確かに復旧していました。
どうやらterminateされたインスタンスの代わりに新たなインスタンスが立ち上がったようです。
新たなインスタンスが元気にリクエストを捌いていました。
新しいインスタンスはRais6アップデート前の状態でデプロイされています。
Auto Scaling?
勝手に立ち上がるってことは、Auto Scalingかな?
と思い、Auto Scalingを見てみました。
確かにアクティビティ履歴にはTerminatingの履歴がありました。
原因を見ると、
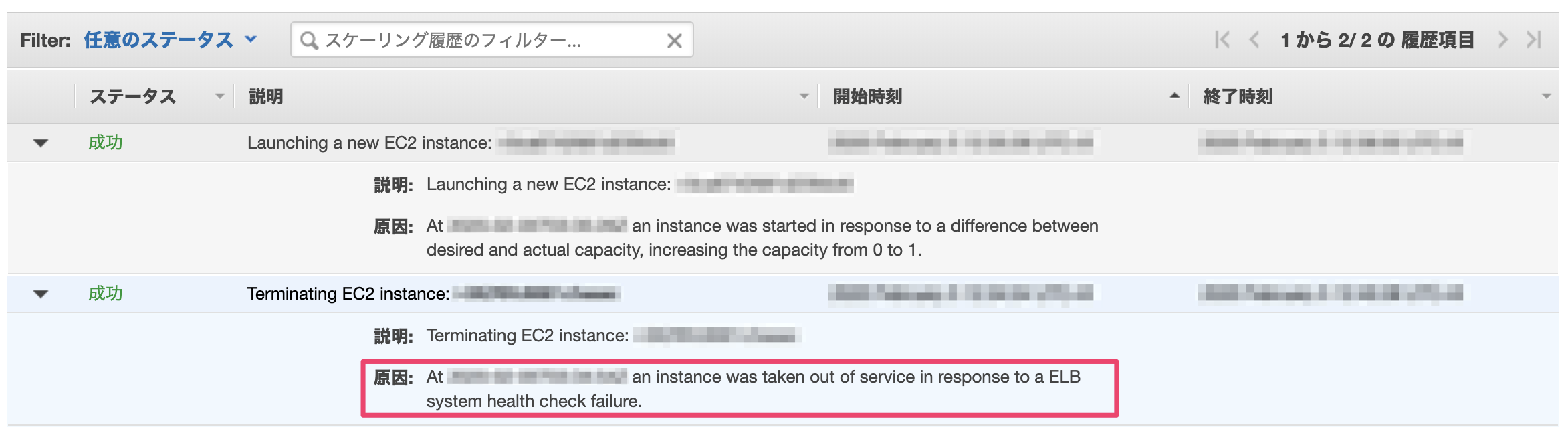
system health check failure.
どうやら、Auto Scaling(ELB)からのヘルスチェックに応答しなかったせいで、unhealty扱いされてインスタンスterminate、という流れだったようです。
ふーん、なるほど。。でもなんで?? ![]()
nginxのアクセスログを見る
アプリケーションエラーが原因ではなさそう、ということは分かっていました。
では、何が原因か?
ヘルスチェックに応答できないって、そもそもヘルスチェックのリクエストに何返してるの??と思い、nginxのアクセスログを見てみました。
新たに立ち上がった元気なインスタンスへsshしてnginxのアクセスログを見てみました。
time:<アクセス時間> host:192.168.0.54 uri:/health status:200 size:33 reqsize:- method:GET referer:- ua:ELB-HealthChecker/2.0 reqtime:0.008 apptime:0.008 upstream:127.0.0.1:8080 vhost:192.168.8.12
time:<アクセス時間> host:192.168.2.116 uri:/health status:200 size:33 reqsize:- method:GET referer:- ua:ELB-HealthChecker/2.0 reqtime:0.013 apptime:0.012 upstream:127.0.0.1:8080 vhost:192.168.8.12
time:<アクセス時間> host:192.168.1.89 uri:/health status:200 size:33 reqsize:- method:GET referer:- ua:ELB-HealthChecker/2.0 reqtime:0.007 apptime:0.000 upstream:127.0.0.1:8080 vhost:192.168.8.12
こんな感じでヘルスチェックのリクエストが来ていました。
status:200 を返していますね。
ちなみに、Railsアプリケーションの動作確認を目的にヘルスチェックのリクエストを受けるエンドポイントを用意しています。
get '/health' => 'health_statuses#show'
この状態で、Rails6アップデートを再度リリースしてみました ![]()
おっ、やっぱりまた落ちた
無事リリースが成功すると、nginxのアクセスログが、
time:<アクセス時間> host:192.168.0.54 uri:/health status:403 size:1187 reqsize:- method:GET referer:- ua:ELB-HealthChecker/2.0 reqtime:0.024 apptime:0.024 upstream:127.0.0.1:8080 vhost:192.168.8.12
time:<アクセス時間> host:192.168.2.116 uri:/health status:403 size:1187 reqsize:- method:GET referer:- ua:ELB-HealthChecker/2.0 reqtime:0.005 apptime:0.008 upstream:127.0.0.1:8080 vhost:192.168.8.12
time:<アクセス時間> host:192.168.1.89 uri:/health status:403 size:1187 reqsize:- method:GET referer:- ua:ELB-HealthChecker/2.0 reqtime:0.002 apptime:0.000 upstream:127.0.0.1:8080 vhost:192.168.8.12
おっと、status:403 に変わりました。
この状態で数十秒経過したら、先ほどと同じくインスタンスterminateされてsshが切断されました。
terminateされてhealthyなインスタンスが無くなってしまうのでELB側で503を返していた、ということだったんですね。
Rails6で403エラーを返す変更といえば・・
そう、 ActionDispatch::HostAuthorization ですね。
production環境には、以下のようにconfig.hostsを設定していました。
config.hosts << '.example.com'
ELBからのヘルスチェックは、host:192.168.0.54 のようにIPアドレスを指定した形式なので ActionDispatch::HostAuthorization のチェックに引っかかって403エラーを返してしまっていたようです。
どう回避したか
以下の通りconfig.hostsの設定をクリアしました。
config.hosts.clear
これで、 ActionDispatch::HostAuthorization のチェックを無効にできます。(せっかく追加された機能を無効化するのは心苦しいですが・・![]() )
)
あとで調べたら、そもそもconfig.hostsを設定しなければ、デフォルトでdevelopment環境以外ではチェックされないようですね。
In other environments
Rails.application.config.hostsis empty and noHostheader checks will be done.
ひとまず、これでヘルスチェックに応答するようになり、社内用production環境へリリースできました。
その後、無事全体のproductionへもリリースできました ![]()
まとめ
ELBからのヘルスチェックを使用している場合はActionDispatch::HostAuthorization に注意してください。
今回、ELBがあるのはproductionだけというインフラ構成の違いによって、stagingでは気づくことができませんでした。
環境ごとの違いをしっかり考慮しておく必要がありますね。
本来は、production と staging はインフラ構成も完全に一致させておくべきです。
しかし、様々な事情によってできないケースもあると思うので難しいところですね。
あと、stagingとproductionの間にもう1クッションとして、社内用のクローズドなproduction環境があるのは本当に助かりました。
もし、いきなり全体productionへリリースしていたら全インスタンス死亡でサービス停止という最悪の事態になるところでした![]()
先人の知恵、努力に感謝です ![]()