目次
本記事の構成は下記の通りです。
- 概要
- 背景
- 構成
-
手順
- §1. 【Orchestrator サーバー】Orchestrator の準備
- §2. 【Orchestrator サーバー】Fluentd (td-agent) のインストール
- §3. 【Orchestrator サーバー】Fluentd (td-agent) の設定ファイルの構成
- §4. 【EFK スタックサーバー】Ubuntu サーバーの設定
- §5. 【EFK スタックサーバー】Docker Engine のインストール
- §6. 【EFK スタックサーバー】Docker 関連ファイルと Fluentd の設定ファイルの構成
- §7. 【EFK スタックサーバー】Docker Compose による EFK スタックのデプロイ
- §8. 【EFK スタックサーバー】Kibana によるログの可視化
- TIPS 集
概要
本記事では、Windows Server OS 上で稼働する Web サーバー (UiPath Orchestrator など) で生成されるシステムログ (IIS ログ、イベントログ、HTTPERR ログなど) と UiPath Robot 実行ログを、 Windows 版 Fluentd (td-agent) と Ubuntu 上の Docker Engine 上のコンテナ群として動作する EFK (Elasticsearch, Fluentd, Kibana) スタックを利用した一元的なログソリューション (リアルタイムのログ収集アーキテクチャー) に統合する方法を説明しています。
本記事では、システムログとして IIS アクセスログのみを対象としていますが、今後の改定でその他のログにも対応できればと計画しています。また本記事の手順は、UiPath 製品に限らず、IIS を利用する一般的な Web サーバーにおいても知見を流用してログ連携できる内容になっています。IIS と EFK スタックの連携方法のみを知りたい場合は、Orchestrator サーバーを Web サーバーと読み替えていただき、 §2. 【Orchestrator サーバー】Fluentd (td-agent) のインストール から読み進めてください。
EFK スタックは、利用するコンポーネント (Elasticsearch, Fluentd, Kibana) の各頭文字をとった名前に由来しています。ログを集計して分析し、アプリケーションおよびインフラストラクチャのモニタリングの可視化、トラブルシューティングの高速化、セキュリティ分析などが実現可能となります。各コンポーネントの役割を簡単に示すと以下の通りです。
- Elasticsearch は、収集されたデータの蓄積/検索を担います。
- Fluentd は、データの収集/編集/転送を担います。
- Kibana は、データの可視化/探索/分析を担います。
Docker Engine は、コンテナ型の仮想環境を作成、配布、実行するためのプラットフォームです。コンテナはホストマシンのカーネルを利用することで、プロセスやユーザなどを隔離することができ、あたかも別のマシンが動いているかのように動かすことができます。そのため、軽量で高速に起動、停止などが可能となります。Docker Compose を利用することで複数のコンテナを一元的に管理することができます。
背景
オンプレミスや IaaS の環境で運用される UiPath Orchestrator 等のサーバー製品では日々様々なログが記録されています。多くの場合、それらのログはサーバー起因のシステム障害が発生した際のトラブルシューティング時には必須の情報となります。一方で、これらのログには例えば、サーバーが誰にどのようにどれくらい利用されているのか、どのような操作にどれくらいの時間を要したのかを示唆する情報も随時出力されています。サーバーが正常系である場合、所有しているリソースがどのように活用されているのかをトラッキングして有益な情報を抽出することで、将来の運用計画にフィードバックしていくこともできます。
しかし、管理するサーバー数が増えると、ログを収集して解析するコストは高くなります。例えば、(A) Orchestrator が複数ノードで冗長化されている場合や、(B) 本番/検証/Staging/Disaster Recoveryのように用途の異なる環境が存在する場合が考えられます。
-
(A) のような環境の全てのノードを統合的に解析する場合、各ノードに管理者ユーザーでログインしてログをコピーし、Parser ツール等で Excel 形式などに整形して時系列分析する必要があります。また、収集したログデータを Elasticsearch/Kibana 等の分析ツールへ投入する際には、別途方法を構築する必要もあります。実際に解析を始めるまでに非常に時間がかかってしまう為、トラブルシューティングのように対応が急がれる状況では悪影響が出る恐れがあります。
-
(B) のような環境の間の比較分析を実施する場合、(A) の場合での懸念事項に加えて、ログ収集元の環境を特定する情報をログに埋め込んで識別したり、タイムゾーンが異なる場合にデータ形式を各環境で一致させる等のように、ログデータを加工して揃える必要があります。この加工処理をバッチなどで部分的に自動化したとしても、バッチ処理が終わるまでデータを解析することができません。また、データ量が大きくなると1つのホストではバッチ処理し切れなくなり破綻します。
本ソリューションを利用することで、(A) や (B) のような環境であっても、一度仕組みを組み込んでしまえば、少ない運用コストでリアルタイムな解析やトラブルシューティングが可能になります。
Fluentd は Kubernetes 環境の統合ログ基盤として、近年ではデファクトスタンダードのソフトウェアの地位を確立しています。
EFK スタックの補足説明は下記の通りです。
-
EFK (Elasticsearch, Fluentd, Kibana) スタック
- ログ データの検索、分析、可視化を可能にする一元化されたログ ソリューションです。
-
Elasticsearch
- Elastic 社が提供している Elastic Stack というプロダクト群に含まれ、Apache Lucene を基盤として構築された分散検索/分析エンジンです。ログのようなシーケンシャルなデータの保存に適しています。
-
Fluentd (td-agent)
- 様々なデータの収集を統一できるオープンソースのデータ コレクターです。2011年にTreasure Data 社により Ruby で開発され、以降は Treasure Data 社およびコミュニティベースで開発されています。
- Fluentd は個々のシステム毎に管理されている大量のログ ファイルを収集、解析し、ストレージに集約、保存を行うツールとして活用されています。 ログに限らず、各種データを NoSQL データベース (MongoDB 等)やクラウドストレージ (Amazon S3 等) など様々な媒体に出力できます。また、Elasticsearch/Kibana と連携してログを可視化する構成においてもインタラクティブなデータの取り扱いが可能です。
- Fluentd は Ruby と C 言語で実装されており、多様な入出力と実行環境を豊富なプラグインを利用することができます。
- Ruby やいくつかのプラグインが同梱されている安定版の「td-agent」としても提供されています。td-agent は開発元である Treasure Data 社より RedHat(rpm)、Debian(deb)、OSX(dmg) などに対応した主要なパッケージとして配布されています。
- Fluentd はプラグイン アーキテクチャを採用しており、用途に応じたプラグイン開発、拡張を自由に行うことができます。機能拡張を前提としないのであれば、td-agent により Fluentd をより手軽に導入する選択も可能です。
- Fluentd と類似コンセプトの Logstash (ELastic 社製) を利用したソリューションも存在し、ELK (Elasticsearch, Logstash, Kibana) スタックと呼ばれます。
-
Kibana
- Elasticsearch と同様に、Elastic 社が提供している Elastic Stack というプロダクト群に含まれます。ログと時系列の分析、アプリケーションのモニタリングなどの用途で使われる、データの視覚化および調査のためのツールです。また Kibana は Elasticsearch と緊密に統合されているため、Elasticsearch に保存されているデータを可視化するための既定の選択肢になります。
構成
本記事では、シングル構成の Orchestrator 環境にてソリューションを構築します。
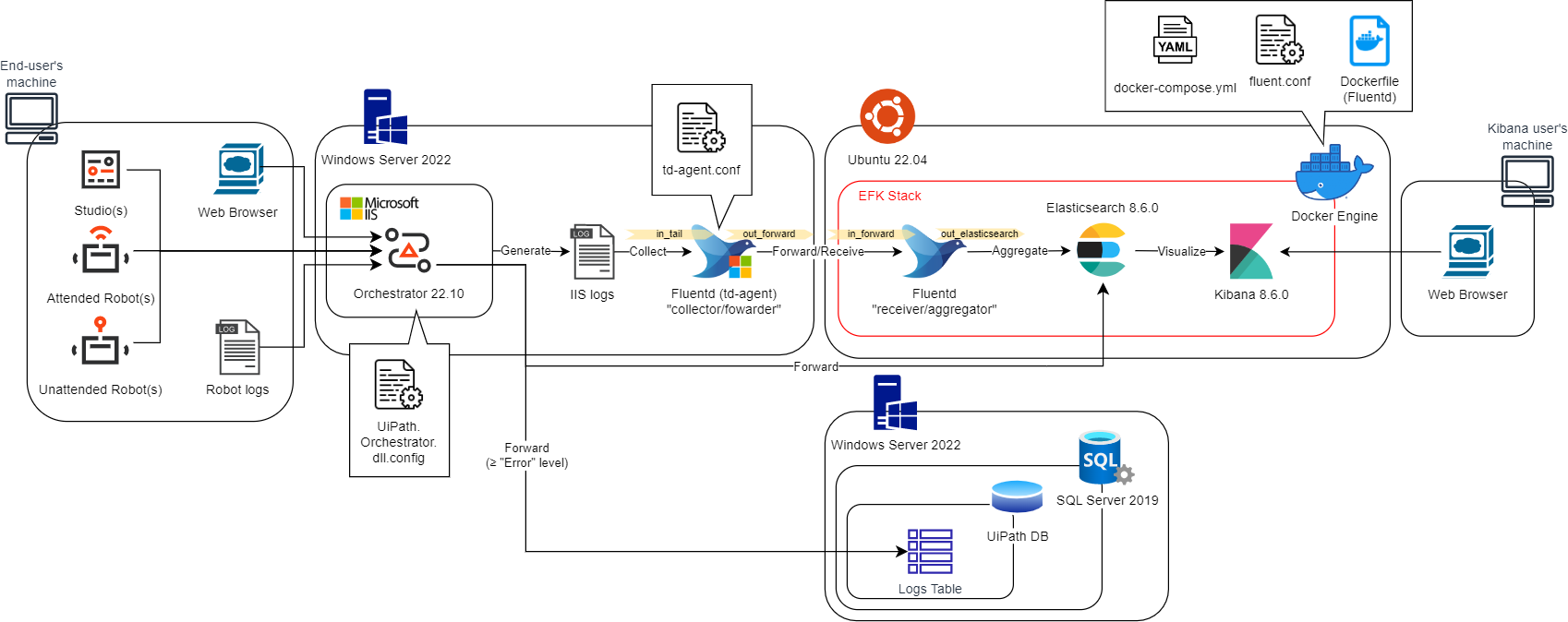
-
Orchestrator server
- HW requirement
- CPU: 4 Cores+
- Memory: 4 GB+
- OS: Windows Server 2022
- Orchestrator version: 22.10
- Fluentd (td-agent) version: 1.15.3
-
DB server
- HW requirement
- CPU 4 Cores+
- Memory: 8 GB+
- OS: Windows Server 2022
- DB engine: SQL Server 2019 Enterprise
-
EFK stack server
- HW requirement
- CPU: 4 Cores+
- Memory: 8 GB+
- Disk size: 128 GB+
- OS: Ubuntu 22.04
- Docker Engine version: 20.10.21
- Docker Compose version: 2.13.0
- fluentd version: v1.15.3-debian-1.0
- Elasticsearch/Kibana version: 8.6.0
手順
UiPath Orchestrator サーバーに記録されている IIS アクセスログを外部の EFK スタック内に連携する手順をステップバイステップで解説します。
§1. 【Orchestrator サーバー】Orchestrator の準備
UiPath Orchestrator 以外の Web サーバーにおける IIS アクセスログを扱う場合、本節はスキップしてください。
- 利用可能な UiPath Orchestrator 環境を用意します。詳細な手順については、UiPath 社の公式ドキュメント (例: 『Orchestrator スタンドアロン インストール ガイド』、『Orchestrator導入ステップバイステップガイド [2023.4 対応版]』等) をご参照ください。
- (任意) UiPath Orchestrator に接続される Studio/Robot を用意し、簡易なプロセスを実行できる状態にしておきます。これにより Robot 実行ログが生成されます。ただし、本記事では IIS アクセスログを主に扱うため、UiPath Orchestrator にブラウザーでアクセスできるクライアント環境があれば問題ありません。
- (任意) Studio/Robot から Orchestrator に投げられた Robot 実行ログを Elasticsearch に投入するために
C:\Program Files (x86)\UiPath\Orchestrator\UiPath.Orchestrator.dll.configを下記のように設定します。ただし、「...」は行間の省略記号とします。UiPath.Orchestrator.dll.config<?xml version="1.0" encoding="utf-8"?> <configuration> ... <!-- Logging configuration --> <nlog ...> ... <targets> ... <target name="robotElasticBuffer" xsi:type="BufferingWrapper" flushTimeout="5000"> <target xsi:type="ElasticSearch" name="robotElastic" uri="http://elasticsearch_ip:9200" requireAuth="false" username="" password="" index="${event-properties:item=indexName}-${date:format=yyyy.MM.dd}" documentType="" includeAllProperties="true" layout="${message}" excludedProperties="agentSessionId,tenantId,indexName" /> </target> <target name="serverElasticBuffer" xsi:type="BufferingWrapper" flushTimeout="5000"> <target xsi:type="ElasticSearch" name="serverElastic" uri="http://elasticsearch_ip:9200" requireAuth="" username="" password="" index="serverdiagnostics-${date:format=yyyy.MM.dd}" documentType="" includeAllProperties="true" layout="${machinename} ${message}" /> </target> ... </targets> ... <rules> ... <logger name="BusinessException.*" minlevel="Info" writeTo="businessExceptionEventLog" final="true" /> <logger name="Robot.*" ruleName="primaryRobotLogsTarget" minlevel="Warn" final="false" writeTo="database" /> <logger name="Robot.*" ruleName="primaryRobotLogsTarget" minlevel="Info" final="true" writeTo="robotElasticBuffer" /> <logger name="Monitoring.*" writeTo="monitoring" minlevel="Warn" final="true" /> <logger name="*" minlevel="Info" writeTo="eventLog" /> <logger name="*" minlevel="Warn" writeTo="fileLog" /> </rules> </nlog> <appSettings> ... <add key="Logs.RobotLogs.ReadTarget" value="robotElasticBuffer" /> ... <!-- Logs --> <add key="Logs.Elasticsearch.MaxResultWindow" value="10000" /> ... </appSettings> ... </configuration>- NLog ターゲットの
robotElasticBufferの設定は、Robot 実行ログを Elasticsearch に送りたい場合に記述します。 - (任意) NLog ターゲットの
serverElasticBufferの設定は、Orchestrator ソースの Application イベントログを Elasticsearch に送りたい場合に記述します。- 本設定を機能させるためには、NLog ターゲットの
rulesセクションにおけるlogger name="*"の設定が必要です。例えば次のような一行を利用します:<logger name="*" minlevel="Warn" writeTo="serverElasticBuffer" />。
- 本設定を機能させるためには、NLog ターゲットの
- ターゲット設定における
date:formatは既定でyyyy.MMであり、月次で Index が生成されます。この値をyyyy.MM.ddと設定することで、日次で Index が作成されます。 - ターゲット設定における
documentTypeは Elasticsearch 8.x より廃止されたため、ここでは空欄を設定します。 - NLog ターゲットの
rulesセクションにおけるlogger name="Robot.*"の設定は、実行ログの投入先を指定します。NLog のminlevelオプション (Tutorial) を利用することで、ログレベルに応じて投入先を振り分けることも可能です。ここでは、警告 (Warn) レベル以上のログを SQL Server に、情報 (Info) レベル以上のログを Elasticsearch に投入するように設定しています。 -
Logs.RobotLogs.ReadTargetキーは、Orchestrator が Robot 実行ログを読み込む先のターゲットを指定します。SQL Server から実行ログを読み込む場合は「database」、Elasticsearch から読み込む場合は「robotElasticBuffer」を値として指定します。 - (任意) Elasticsearch からログを読み込む場合、一度のクエリで読み込まれるログ件数は既定で 10000 件に制限されています。10000 件より多くのログを読み込む必要がある場合には、
Logs.Elasticsearch.MaxResultWindowキーで上限値を調整します。
- NLog ターゲットの
§2. 【Orchestrator サーバー】Fluentd (td-agent) のインストール
-
Orchestrator サーバーにログ送信用の Windows 版 Fluentd(td-agent) をインストールします。MSI インストーラーのダウンロードリンクは こちら です。
-
ダウンロードページから、最新の MSI インストーラーをダウンロードします。ここでは td-agent-4.4.2-x64.msi を利用します。
-
MSI インストーラーを起動します。Microsoft Defender SmartScreen に起動が妨げられた場合は、[詳細情報] リンクをクリックします。[実行] ボタンが現れるので、[実行] ボタンをクリックします。
-
MSI インストーラーが起動されるので、ウィザードに従ってインストールします。

-
Td-agent Command Prompt を起動します。Td-agent Command Prompt は基本的にはコマンドプロンプト (cmd.exe) そのものです。ただし、td-agent のプログラムのために
PATHが調整されているため、td-agent と対話する必要がある場合はこのプログラムを使います。
-
Td-agent Command Prompt で下記のコマンドを実行します。これにより、td-agent はログファイルのリッスンを開始し、発生したレコードを EFK スタックの Fluentd コンテナ (後述の手順でデプロイ) に出力するようになります。
Td-agent Command PromptC:\opt\td-agent> td-agent
- td-agent サービスとして起動する方法は下記の2通りあります。ログは
C:/opt/td-agent/td-agent.logに記録されます。- コマンドプロンプトで
net.exeコマンドから起動コマンドプロンプトcmd> net start fluentdwinsvc The Fluentd Windows Service service is starting.. The Fluentd Windows Service service was started successfully. - Powershell の
Start-Serviceコマンドレッドから起動PowerShellPS> Start-Service fluentdwinsvc
- コマンドプロンプトで
- td-agent サービスを再起動する方法は下記です。
Td-agent Command Prompt
C:\opt\td-agent>net stop fluentdwinsvc Fluentd Windows Service サービスを停止中です. Fluentd Windows Service サービスは正常に停止されました。 C:\opt\td-agent>net start fluentdwinsvc Fluentd Windows Service サービスを開始します. Fluentd Windows Service サービスは正常に開始されました。
- td-agent サービスとして起動する方法は下記の2通りあります。ログは
-
Fluentd のプラグインである fluent-plugin-config-expander (GitHub - tagomoris/fluent-plugin-config-expander) をインストールします。このプラグインは Fluentd (td-agent) の MSI インストーラには含まれていません。
- このプラグインを利用することで、繰り返し項目を記述するための設定テンプレートの利用や設定ファイルの記法の拡張が可能となります。例えば、設定ファイルである
td-agent.conf内の<config>ディレクティブには、実際のInput/Filter/Outputプラグインの設定を書くことができ、ループ制御のための特別なディレクティブも利用可能です。 - インストール方法は、Td-agent Command Prompt を起動し、下記の
td-agent-gemコマンドを利用します。--version=?.?.?オプションを利用することでプラグインのバージョンを指定することができますが、このオプションを利用しない場合は最新版がインストールされます。Td-agent Command PromptC:\opt\td-agent> fluent-gem install fluent-plugin-config-expander
- このプラグインを利用することで、繰り返し項目を記述するための設定テンプレートの利用や設定ファイルの記法の拡張が可能となります。例えば、設定ファイルである
§3. 【Orchestrator サーバー】Fluentd (td-agent) の設定ファイルの構成
Orchestrator サーバーにて、Fluentd (td-agent) の設定ファイルを記述します。C:/opt/td-agent/etc/td-agent/td-agent.conf ファイルをテキストエディターで開き、下記のように編集します。
# Fluentdのシステム設定
<system>
process_name "Data collector"
log_level debug
</system>
# 入力/収集
<source>
@type config_expander # Inputプラグインの機能拡張(in_config_expanderプラグイン)
<config>
@type tail # ログファイル読み取り(in_tailプラグイン)
@label @iislog.orchestrator
tag iislog.${hostname} # ログ取得元サーバーのホスト名を取得してタグに追記
path C:/inetpub/logs/logfiles/*/* # 対象のログフォルダパス/ログファイルパス
pos_file C:/opt/td-agent/var/log/td-agent/tmp/iislog.pos # tail位置情報
read_from_head true
<parse>
@type regexp # 正規表現の設定(parse_regexpプラグイン)
expression /((?<time>\d{4}-\d{2}-\d{2} [\d:]+) (?<message>.+))|(.*)/ # ログの正規表現によるキー名付与
time_key time # 時間キーの対象を指定
time_format "%Y-%m-%d %H:%M:%S" # 時間フォーマットを指定
</parse>
</config>
</source>
# 編集/追加
<label @iislog.orchestrator>
# パターンマッチしないログの除外
<filter iislog.**>
@type grep # filter_grepプラグイン
<exclude>
key message # 除外対象の判別のキー名
pattern /^$/ # 除外対象の条件値
</exclude>
</filter>
# メッセージの細分化
<filter iislog.**>
@type parser # 構文解析(filter_parserプラグイン)
key_name message # 構文解析の対象キー
# 構文解析
# IISログフィールドの対象 "s-ip cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Referer) sc-status sc-substatus sc-win32-status time-taken"
format /^(?<s_ip>[^ ]*) (?<cs_method>[^ ]*) (?<cs_uri_stem>[^ ]*) (?<cs_uri_query>[^ ]*) (?<s_port>[^ ]*) (?<cs_username>[^ ]*) (?<c_ip>[^ ]*) (?<User_Agent>[^ ]*) (?<Referer>[^ ]*) (?<sc_status>[^ ]*) (?<sc_substatus>[^ ]*) (?<sc_win32_status>[^ ]*) (?<time_taken>[^ ]*)$/
reserve_time true # 元のイベント時間を構文解析結果に含むようにするか否か : default "false" (含まない)
reserve_data true # 元のキーペアを構文解析結果に含むようにするか否か : default "false" (含まない)
remove_key_name_field true # 構文解析に成功した場合キーを削除するか否か : default "false" (削除しない)
</filter>
# ホスト名フィールドの追加
<filter iislog.**>
@type record_transformer # レコード変換および追加(filter_record_transformerプラグイン)
enable_ruby true # Ruby言語有効化
<record>
s_hostname "#{Socket.gethostname}" # ホスト名の取得とキー名の設定
</record>
</filter>
# 出力/転送
<match iislog.**>
@type forward # 転送プラグイン(out_forwardプラグイン)
<server>
host 123.45.67.89 # EFKスタックのIPアドレス
port 24224 # EFKスタックのFluentdコンテナのポート番号:default "24224"
</server>
</match>
</label>
# Fluentd自身のログの処理
<label @FLUENT_LOG>
<match fluent.**>
#<match fluent.{warn,error,fatal}>
@type stdout
</match>
</label>
- 設定内容は
<system>、<source>、<filter>、<match>の大きく4つのディレクティブから構成されています。各ディレクティブでは以下のような役割を持っています。-
<system>ディレクティブではプロセス名の名前付けやログレベル、スレッド数制御など、Fluentd 全体の動作に関する設定を行います。 -
<source>ディレクティブでは、収集元のデータを定義し、in_tailプラグインによりデータを収集します。-
label(任意):tailしたデータにラベルを付与します。ラベルを利用することで<filter>ディレクティブや<match>ディレクティブで対象のラベルのみに対して処理を行います。 -
path(必須):tailする対象のファイルパスを指定します。「,」で区切って複数の対象を指定できます。 -
pos_file(推奨; 既定で設定なし):tailしているログファイルの何処までをtailしたかという位置情報をファイルに保存する場合、そのファイルパスを記述します。-
pos_fileをC:\opt\td-agent\var\log\td-agent\tmpフォルダに設定していますので、tmpフォルダは事前に作成しておきます。 - この設定を有効にしておくことで、Fluentd がダウンしても元の場所から tail が再開できます。もしこのデータに基づいて探索した際にファイル自体が無かったりした場合は、このデータは破棄して新しい位置情報を保存します。このパラメータを設定しない場合、「
this parameter is highly recommended to save the position to resume tailing.」というログが出力されます。 - 「
*」や日時のパターンをpathパラメータに指定している場合にはread_from_headパラメータをtrueに設定します。このパラメータは、Fluentd の起動直後や新しいファイルを検出した場合に、ファイルの先頭から読み込み始める為のオプションです。read_from_headパラメータがtrueの場合、pos_fileパラメータの指定が無いとpathパラメータで指定されたファイルの先頭からデータの読み込みを開始するため、送られるデータが重複してしまう可能性があります。-
read_from_headパラメータは Fluentd v1.14.3 より既定でtrueとなっています。
-
-
-
expression:tailしたデータにキー名を付与します。ここでは time と message に分離し、名前を付与しています。- time と message 表記に一致しないデータは(
.*)にマッチさせます。 - この段階でメッセージに細かくキー名を付与することもできますが、次の
<filter>ディレクティブで編集を行います。 -
<filter>ディレクティブで編集をする1つのメリットとしては、message に対して複数回の編集や message そのものを保持をすることが可能となるためです。
- time と message 表記に一致しないデータは(
-
-
<filter iislog.**>ディレクティブでは、ログメッセージの編集 (ここではパターン例外の除外・メッセージ細分化・時間変換、ホスト名フィールドの付与) をしています。-
iislog.**によりtag名のパターンに一致したログのみを処理対象とします。 - パターン例外の除外では、message を細分化する際に警告ログが表示されるため、パターンにマッチしないログを除外しています。
- メッセージの細分化では、
<source>ディレクティブで名前付けした message に対して処理を行います。ログ出力設定の各項目に合わせてキー名の付与をしています。 - キー名付与では、正規表現を用いるため、
‐(ハイフン) の利用を避けることをお勧めします。 - ホスト名フィールドの追加では、ログ情報に存在しない、ホスト名をキーとして付与し、どのサーバからの情報であるかを判別できるようにしています。
-
-
<match iislog.**>ディレクティブでは、out_forwardプラグインにより、フィルター処理されたデータの転送設定を定義しています。-
iislog.**によりtag名のパターンに一致したログのみを処理対象とします。 -
hostには EFK スタックの IP アドレスまたはホスト名を指定します。 -
portには EFK スタック Fluentd コンテナのポート番号を指定します。
-
-
- 各ディレクティブの詳細な利用方法に関しては別記事の『Fluentd (td-agent) の設定ファイル内の概念と記法』をご覧ください。
§4. 【EFK スタックサーバー】Ubuntu サーバーの設定
- Elasticsearch のプロセスが使用可能なメモリマップ領域の最大値を増やします。Elasticsearch は既定では
mmapfs(memory mapped file system) ディレクトリを使用して Index を保存します。Linux によるmmapカウントの既定値は Elasticsearch にとって低すぎる可能性があります。この制限はvm.max_map_countパラメータで指定されます。- 現在のシステムに設定されているパラメータの設定値を確認します。
例えば下記のように表示されます。Ubuntu
/sbin/sysctl -aUbuntu... (略) ... vm.max_map_count = 65530 ... (略) ... - root 権限で
/etc/sysctl.confを開きます。Ubuntusudo vi /etc/sysctl.conf - 使用可能なメモリマップ領域の最大値を「
262144」以上に増やします。例えば、末尾にvm.max_map_count=262144を追記して保存します。 - root 権限で次のコマンドを実行して設定を反映します。システムの再起動は不要です。
Ubuntu
/sbin/sysctl -p /etc/sysctl.conf
- 現在のシステムに設定されているパラメータの設定値を確認します。
- Firewall 設定にて EFK スタックで利用されるポートを開けておきます。
- Firewall を有効化します。
Ubuntu
sudo ufw enable - 下記のポートを開放します。
- Elasticsearch: 9200-9300/tcp
Ubuntu
sudo ufw allow 9200:9300/tcp - Kibana: 5601/tcp
Ubuntu
sudo ufw allow 5601/tcp - Fluentd: 24224 (tcp, udp)
Ubuntu
sudo ufw allow 24224
- Elasticsearch: 9200-9300/tcp
- Firewall をリロードして設定を反映させます。
Ubuntu
sudo ufw reload - 下記の状態になっていれば OK です。
Ubuntu
# ufw status numbered Status: active To Action From -- ------ ---- [ 1] 22/tcp ALLOW IN Anywhere [ 2] 9200:9300/tcp ALLOW IN Anywhere [ 3] 5601/tcp ALLOW IN Anywhere [ 4] 24224 ALLOW IN Anywhere
- Firewall を有効化します。
§5. 【EFK スタックサーバー】Docker Engine のインストール
- 古いバージョンの Docker Engine をアンインストールします。
- Docker Engine のかつてのバージョンは
docker、docker.io、docker-engineと呼ばれていました。 これらがインストールされている場合はアンインストールしてください。Ubuntu Shellsudo apt-get remove docker docker-engine docker.io containerd runc -
apt-getを実行し、上記のパッケージがインストールされていないと表示されることを確認します。
- Docker Engine のかつてのバージョンは
- Docker Engine のインストール準備として、リポジトリを設定します。
Temporary failure resolvingエラーが発生する場合は本記事末尾のトラブルシュート情報を参照のこと。-
aptのパッケージ インデックスを更新します。Ubuntusudo apt-get update -
aptが HTTPS 経由でリポジトリにアクセスしパッケージをインストールできるようにします。Ubuntusudo apt-get -y install ca-certificates curl gnupg lsb-release - Docker の公式 GPG 鍵を追加します。
Ubuntu
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg - 安定版 (stable) リポジトリをセットアップします。
Ubuntu
echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
-
- Docker Engine をインストールします。
-
aptのパッケージ インデックスを更新します。Ubuntusudo apt-get update - Docker Engine と containerd の最新版をインストールします。
Ubuntu
sudo apt-get -y install docker-ce docker-ce-cli containerd.io sudo docker -v Docker version 20.10.21, build baeda1f - Docker Engine が正しくインストールされているのを確認するため、hello-world イメージを実行します。
Ubuntu
sudo docker run hello-world
-
-
Docker Compose V2 をインストールします。
- Docker Compose V2 のインストール先のディレクトリを作成します。
Ubuntu
mkdir -p ~/.docker/cli-plugins-
~($HOME) は/home/{現在のSSH接続でログイン中のユーザー名}を指す環境変数です。 -
ls -aコマンドで Docker の隠しディレクトリ.dockerが存在することを確認できます。
-
-
cURLコマンドで Docker Compose V2 (本記事では v2.13.0) をインストールします。その他の Docker Compose のバージョンは Releases > docker/compose から確認できます。Ubuntucurl -Lf -o ~/.docker/cli-plugins/docker-compose "https://github.com/docker/compose/releases/download/v2.13.0/docker-compose-linux-x86_64" -
chmodコマンドで現在のユーザーに Docker Compose の実行権限を付与します。Ubuntuchmod +x ~/.docker/cli-plugins/docker-compose - Docker Compose の正常性を確認します。ここでは Compose のバージョンを出力するコマンドを実行しています。
Ubuntu
docker compose version Docker Compose version v2.13.0
- Docker Compose V2 のインストール先のディレクトリを作成します。
§6. 【EFK スタックサーバー】Docker 関連ファイルと Fluentd の設定ファイルの構成
- 詳細は後述しますが、最終的なディレクトリとファイルの配置は下記のようになります。ただし、本記事では利用していないディレクトリ (
elasticsearch/buffer,fluentd/log,fluentd/plugin) も含みます。Ubunturoot@efk-ubuntu2204:~/.docker/projects# tree -a . └── efk ├── docker-compose.yml ├── elasticsearch │ └── buffer ├── .env └── fluentd ├── Dockerfile ├── etc │ └── fluent.conf ├── log └── plugin - Fluentd の公式の Docker イメージには Elasticsearch プラグインが含まれいないため、イメージをカスタマイズする必要があります。まず、Fluentd 用の Dockerfile や設定ファイル (
fluent.conf) のルート ディレクトリとしてfluentdディレクトリを作成します。Ubuntumkdir -p ~/.docker/projects/efk/fluentd - Fluentd の設定ファイル (~/.docker/projects/efk/fluentd/etc/fluent.conf) を作成します。
参考: Docker Logging Efk Compose~/.docker/projects/efk/fluentd/etc/fluent.conf# Fluentd のシステム設定 <system> process_name "Data aggregator" log_level info </system> # 受信 <source> @type forward # ログファイル受信 (in_forwardプラグイン) @label @iislog.aggregated #port 24224 #bind 0.0.0.0 </source> <label @iislog.aggregated> # 時間変換 (UTCからJST) <filter iislog.**> @type record_transformer # レコード変換(追加含む)プラグイン enable_ruby true # ruby 利用有無 <record> jst_time ${(time + (9 * 60 * 60)).strftime('%Y-%m-%dT%H:%M:%S%z')} # JST 時間への変換 </record> </filter> # Elasticsearch へ投入 <match iislog.**> @type copy # 複数ターゲットへのデータ転送 (out_copyプラグイン) <store> @type elasticsearch # Elasticsearch へのデータ転送 (out_elasticsearchプラグイン) host "elasticsearch-8.6.0-container" # EFK スタックの IP アドレスまたはElasticsearchのコンテナ名 port 9200 # Elasticsearch コンテナのポート番号 logstash_format true # インデックス名変更有無 (logstash_prefix変更の場合必須、trueの場合[logstash]-%Y.%m.%d) logstash_prefix "iis" # インデックス名を iis に変更 (デフォルト:logstash) log_es_400_reason true # Elasticsearch API 400 の場合にエラーを記録 (デフォルト:false) time_key jst_time # time キーに jst_time を指定 remove_keys jst_time # jst_time キーは不要なため削除 </store> <store> @type stdout </store> </match> </label>- 設定内容は
<system>、<source>、<filter>、<match>の大きく4つのディレクティブから構成されています。各ディレクティブでは以下のような役割を持っています。-
<system>ディレクティブでは、プロセス名の名前付けやログレベル、スレッド数制御など、Fluentd 全体の動作に関する設定を行います。 -
<source>ディレクティブでは、収集元のデータを定義し、in_forwardプラグインによりデータを収集します。-
label(任意): tail したデータにラベルを付与します。ラベルを利用することで<filter>ディレクティブや<match>ディレクティブで対象のラベルのみに対して処理を行います。
-
-
<filter iislog.**>ディレクティブでは、record_transformerプラグインによりフィールドの追加をします。- 筆者の環境では Windows Server 側のタイムゾーン設定に依らず、IIS ログ (W3C 形式のログ) の日時は UTC で記録された為、新規に
jst_timeフィールドを作成しています。
- 筆者の環境では Windows Server 側のタイムゾーン設定に依らず、IIS ログ (W3C 形式のログ) の日時は UTC で記録された為、新規に
-
<match iislog.**>ディレクティブでは、in_forwardプラグインからの全てのログを認識させ、ログデータを Elasticsearch と標準出力 にコピーします。-
iislog.**によりtag名のパターンに一致したログのみを処理対象とします。 -
out_elasticsearchプラグインにより、ログデータを Elasticsearch に転送しています。-
hostには EFK スタックの IP アドレスまたは後ほど設定する Elasticsearch のコンテナ名を指定します。 -
portには EFK スタック Elasticsearch コンテナのポート番号を指定します。
-
-
-
- 各ディレクティブの詳細な利用方法に関しては別記事の『Fluentd (td-agent) の設定ファイル内の概念と記法』をご覧ください。
- 設定内容は
-
fluentdフォルダー内に Dockerfile を作成します。Fluentd のコンテナが作成される際に、ログを Elasticsearch に送るためのプラグイン (GitHub - uken/fluent-plugin-elasticsearch) 等がインストールされるようにします。これらのプラグインは Fluentd の標準プラグインではないため、gemコマンドによる導入が必要です。~/.docker/projects/efk/fluentd/DockerfileFROM fluent/fluentd:v1.15.3-debian-1.0 ENV DEBIAN_FRONTEND=noninteractive ENV DEBCONF_NOWARNINGS=yes USER root RUN buildDeps="sudo apt-utils ruby gem ruby-dev build-essential g++ libc-dev" \ && apt-get update \ && apt-get install -y --no-install-recommends $buildDeps \ && gem install fluent-plugin-config-expander fluent-plugin-elasticsearch \ && gem sources --clear-all \ && SUDO_FORCE_REMOVE=yes \ apt-get purge -y --auto-remove \ -o APT::AutoRemove::RecommendsImportant=false \ $buildDeps \ && rm -rf /var/lib/apt/lists/* \ && rm -rf /tmp/* /var/tmp/* /usr/lib/ruby/gems/*/cache/*.gem USER fluent-
ENV行は警告debconf: delaying package configuration, since apt-utils is not installedの回避のために記述します。 - Fluentd のバージョンを
latestとすると Alpine Linux をベースイメージとした コンテナが作成される可能性があります。Debian のパッケージマネージャーはaptですが、Alpine (アルパイン) ではapkであるため、上記の Dockerfile のままでは動作しません。最新版はこちらから確認できます。 - Debian 及び Ubuntu 系では
--no-install-recommendsを付けると、不必要なパッケージのインストールを防ぐことができます。 -
gemコマンドには Ruby と RubyGems のインストールが必要です。変数buildDepsで指定しているbuild-essentialでRuby 開発に必要なツール (gccやmake) を一括でインストールできます。 -
&& rm -rf /var/lib/apt/lists/* \でaptのキャッシュを破棄してイメージ容量を削減します。
-
-
docker-compose.ymlファイルを作成します。Fluentd のバージョンは、fluentd/Dockerfileで指定されています。ここでは簡単のために、XPack のセキュリティ機能を無効化した設定を利用しています。~/.docker/projects/efk/docker-compose.ymlversion: "3.9" services: elasticsearch: container_name: elasticsearch-${ELASTICSTACK_VERSION}-container image: docker.elastic.co/elasticsearch/elasticsearch:${ELASTICSTACK_VERSION} networks: - efk-vnet volumes: - elasticdata:/usr/share/elasticsearch/data ports: - ${ELASTICSEARCH_PORT}:9200 environment: - network.host=0.0.0.0 - discovery.type=single-node - xpack.security.enabled=false restart: always mem_limit: ${MEM_LIMIT} ulimits: memlock: soft: -1 hard: -1 healthcheck: test: curl -s -f elasticsearch-${ELASTICSTACK_VERSION}-container:9200/_cat/health >/dev/null || exit 1 interval: 5s timeout: 5s retries: 10 kibana: container_name: kibana-${ELASTICSTACK_VERSION}-container depends_on: - elasticsearch image: docker.elastic.co/kibana/kibana:${ELASTICSTACK_VERSION} networks: - efk-vnet volumes: - kibanadata:/usr/share/kibana/data environment: - ELASTICSEARCH_HOSTS=http://elasticsearch-${ELASTICSTACK_VERSION}-container:9200 - SERVER_PUBLICBASEURL=http://${EFK_IP}:5601 - I18N_LOCALE=${I18N_LOCALE} restart: always mem_limit: ${MEM_LIMIT} ports: - ${KIBANA_PORT}:5601 fluentd: container_name: fluentd-${FLUENT_VERSION}-container depends_on: elasticsearch: condition: service_healthy build: ./fluentd networks: - efk-vnet volumes: - ~/.docker/projects/efk/fluentd/etc:/fluentd/etc #- ~/.docker/projects/efk/fluentd/log:/fluentd/log #- ~/.docker/projects/efk/fluentd/plugin:/fluentd/etc/fluent/plugin #environment: #- FLUENT_CONF=./fluentd/etc/fluent.conf ports: - ${FLUENT_PORT}:24224 - ${FLUENT_PORT}:24224/udp restart: always logging: driver: "json-file" options: #fluentd-async: "true" max-size: 100m max-file: "5" networks: efk-vnet: driver: bridge volumes: elasticdata: driver: local kibanadata: driver: local-
volumesオプションの設定で、EFK スタック (Ubuntu サーバー) のローカルのディレクトリである~/.docker/projects/efk/fluentd/etcを Fluentd コンテナ内の/fluentd/etcにマウントしています。
-
- 前述の docker-compose.yml 内で利用される環境変数のデフォルト値は環境ファイル .env で定義します。.env ファイルは docker-compose.yml と同じディレクトリ (プロジェクトのルートフォルダー) に作成します。
~/.docker/projects/efk/.env
# Project namespace (defaults to the current folder name if not set) COMPOSE_PROJECT_NAME=uipath_ocefk # Set IP address of the EFK stack server EFK_IP=123.45.67.89 # Version of Elastic products ELASTICSTACK_VERSION=8.6.0 # Version of Fluentd FLUENT_VERSION=1.15.3 # Port to expose Elasticsearch HTTP API to the host ELASTICSEARCH_PORT=9200 # Port to expose Kibana to the host KIBANA_PORT=5601 # Port to expose FluentD to the host FLUENT_PORT=24224 # Increase or decrease based on the available host memory (in bytes) MEM_LIMIT=1g # Choose language (en(default), zh-CN, ja-JP, fr-FR) of Kibana I18N_LOCALE=ja-JP # Set to 'basic' or 'trial' to automatically start the 30-day trial LICENSE=basic - docker-compose.yml と .env ファイルに不備が無いことを確認します。プロジェクトのルートフォルダーで下記のコマンドを実行すると、.env ファイルで定義された変数などが反映された状態の docker-compose.yml を確認できます。 エラーが発生した場合、記述に不備があります。
Ubuntu Shell
cd ~/.docker/projects/efk docker compose config
§7. 【EFK スタックサーバー】Docker Compose による EFK スタックのデプロイ
EFK スタック用のサーバーにて、Docker Composeファイルから EFK スタックを一括デプロイし、各コンテナが正常に起動されたことを確認します。
- すべてのコンテナを起動します。
Ubuntu
cd ~/.docker/projects/efk docker compose up -d- パラメータ
-dは任意です。このパラメータを利用することで、コンテナをデタッチモード (バックグラウンド) で起動できます。これにより同じターミナル (SSH セッション) で後続の作業を続行することができます。
- パラメータ
- EFK スタックが正常に立ち上がっていることを確認します。
- EFK スタックサーバーと疎通できる端末のブラウザーから Elasticsearch サービスの URL (
http://${EFK_IP}:9200) にアクセスし、JSON ファイルのテキストが表示されることを確認します。

- EFK スタックサーバーと疎通できる端末のブラウザーから Kibana サービスの URL (
http://${EFK_IP}:5601) にアクセスできることを確認します。

- Fluentd の正常性確認には下記のコマンドを実行します。
Ubuntu
docker container inspect -f "{{.State.Status}}" fluentd-1.15.3 running-
runningが返ってくれば Fluentd コンテナが正常に起動していると判断できます。
-
- EFK スタックサーバーと疎通できる端末のブラウザーから Elasticsearch サービスの URL (
§8. 【EFK スタックサーバー】Kibana によるログの可視化
-
IIS ログ用の Index Template を設定します。
- Kibana > ホーム > Management > 開発ツール (Dev tools) を開き、下記のクエリを実行して Index Template を設定します。
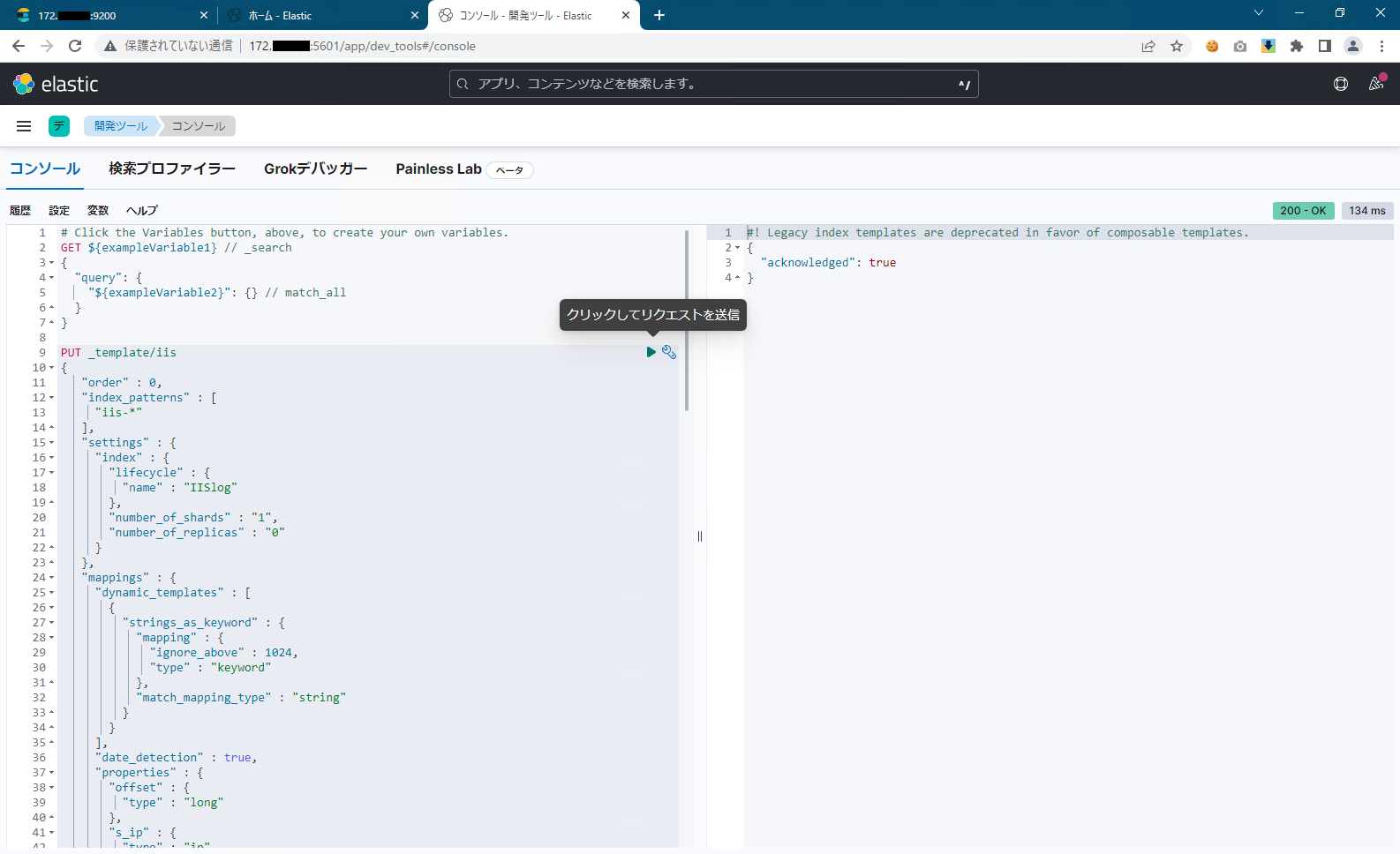
Kibana > Dev Tools > ConsolePUT _template/iis { "order" : 0, "index_patterns" : [ "iis-*" ], "settings" : { "index" : { "lifecycle" : { "name" : "IISlog" }, "number_of_shards" : "1", "number_of_replicas" : "0" } }, "mappings" : { "dynamic_templates" : [ { "strings_as_keyword" : { "mapping" : { "ignore_above" : 1024, "type" : "keyword" }, "match_mapping_type" : "string" } } ], "date_detection" : true, "properties" : { "offset" : { "type" : "long" }, "s_ip" : { "type" : "ip" }, "cs_bytes" : { "type" : "integer" }, "input_type" : { "ignore_above" : 1024, "type" : "keyword" }, "source" : { "ignore_above" : 1024, "type" : "keyword" }, "message" : { "norms" : false, "type" : "text" }, "type" : { "ignore_above" : 1024, "type" : "keyword" }, "c_ip" : { "type" : "ip" }, "time_taken" : { "type" : "integer" }, "tags" : { "ignore_above" : 1024, "type" : "keyword" }, "sc_status" : { "type" : "integer" }, "@timestamp" : { "type" : "date" }, "sc_bytes" : { "type" : "integer" }, "beat" : { "properties" : { "hostname" : { "ignore_above" : 1024, "type" : "keyword" }, "name" : { "ignore_above" : 1024, "type" : "keyword" }, "version" : { "ignore_above" : 1024, "type" : "keyword" } } } } }, "aliases" : { } } - Kibana > ホーム > Management > 開発ツール (Dev tools) を開き、下記のクエリを実行して Index Template を設定します。
-
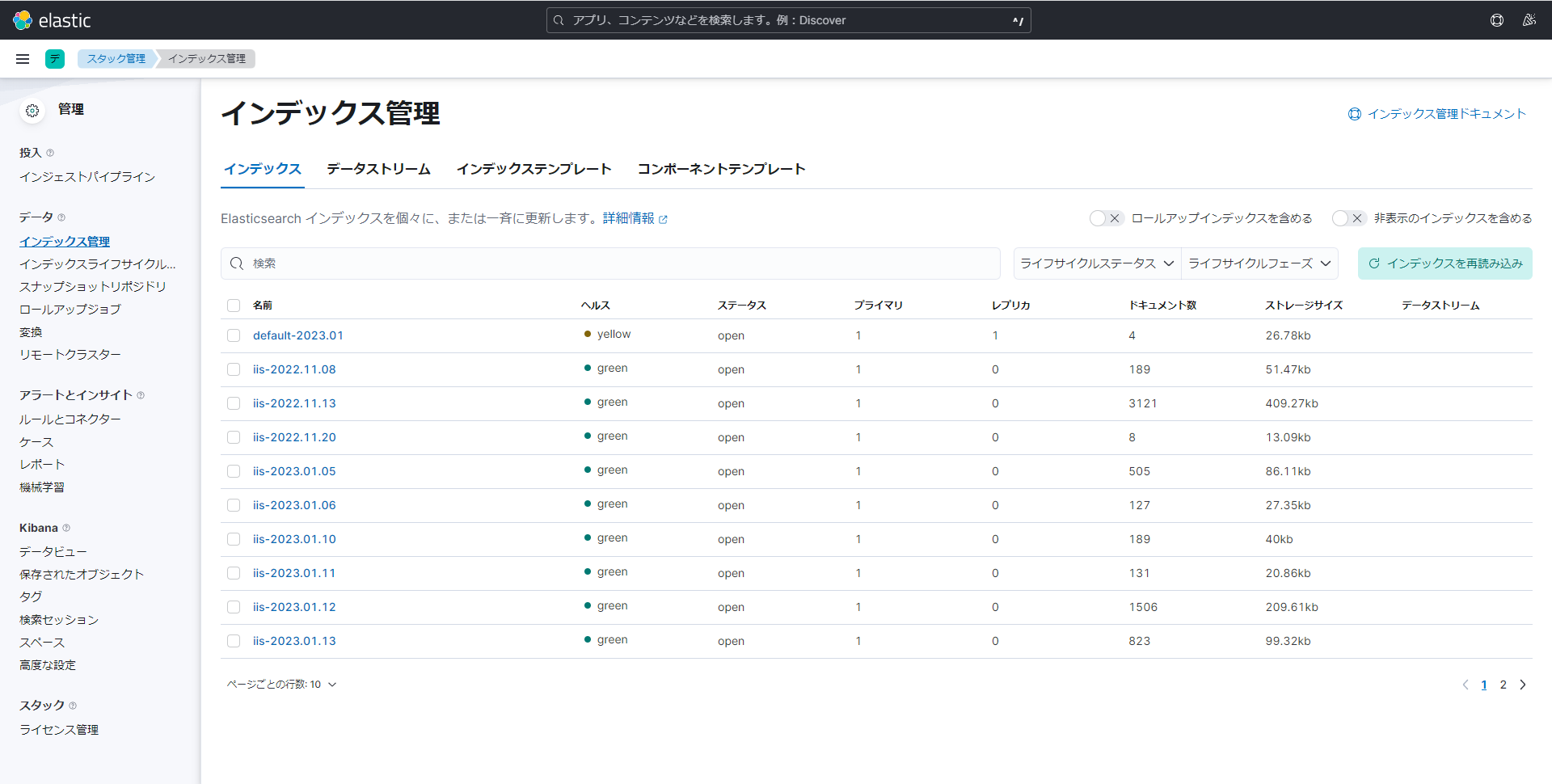
Kibana > Management > インデックス管理 から、
iis-yyyy.MM.ddのインデックスが投入されたことを確認します。
-
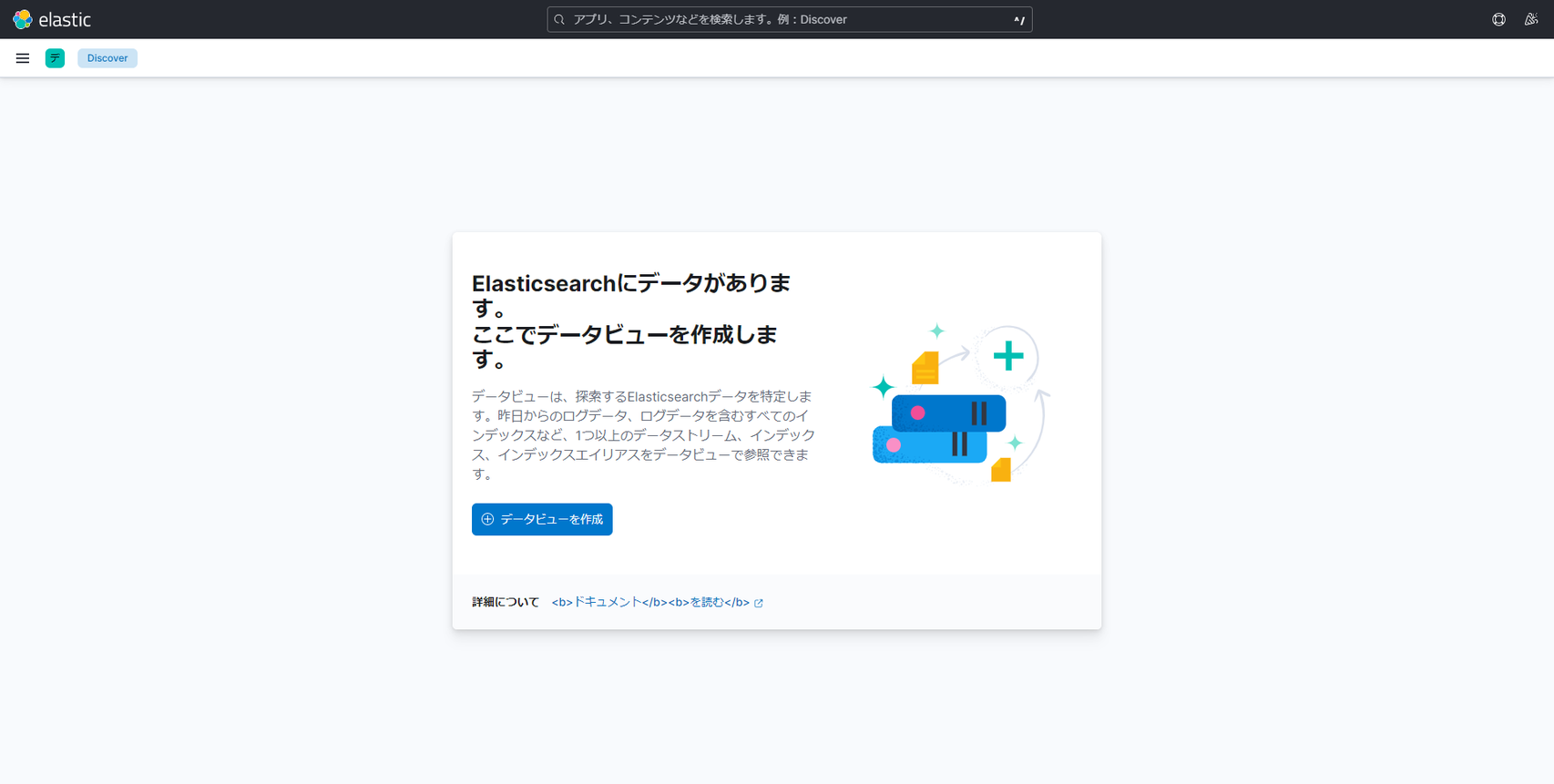
Kibana > Analytics > Discover を開きます。
- データが存在している場合、「
Elasticsearch にデータがあります。ここでデータビューを作成します。」というメッセージが表示されますので、[データビューを作成] リンクをクリックします。
- IIS ログは
iis-yyyy.MM.dd形式のインデックスで Elasticsearch に投入されるように設定しています。[Name] 欄はインデックスの名前であり任意の文字列を指定します。[インデックスパターン] 欄には、ワイルドカードを利用して「iis-*」と指定します。最後に [データビューを Kibana に保存] ボタンをクリックします。
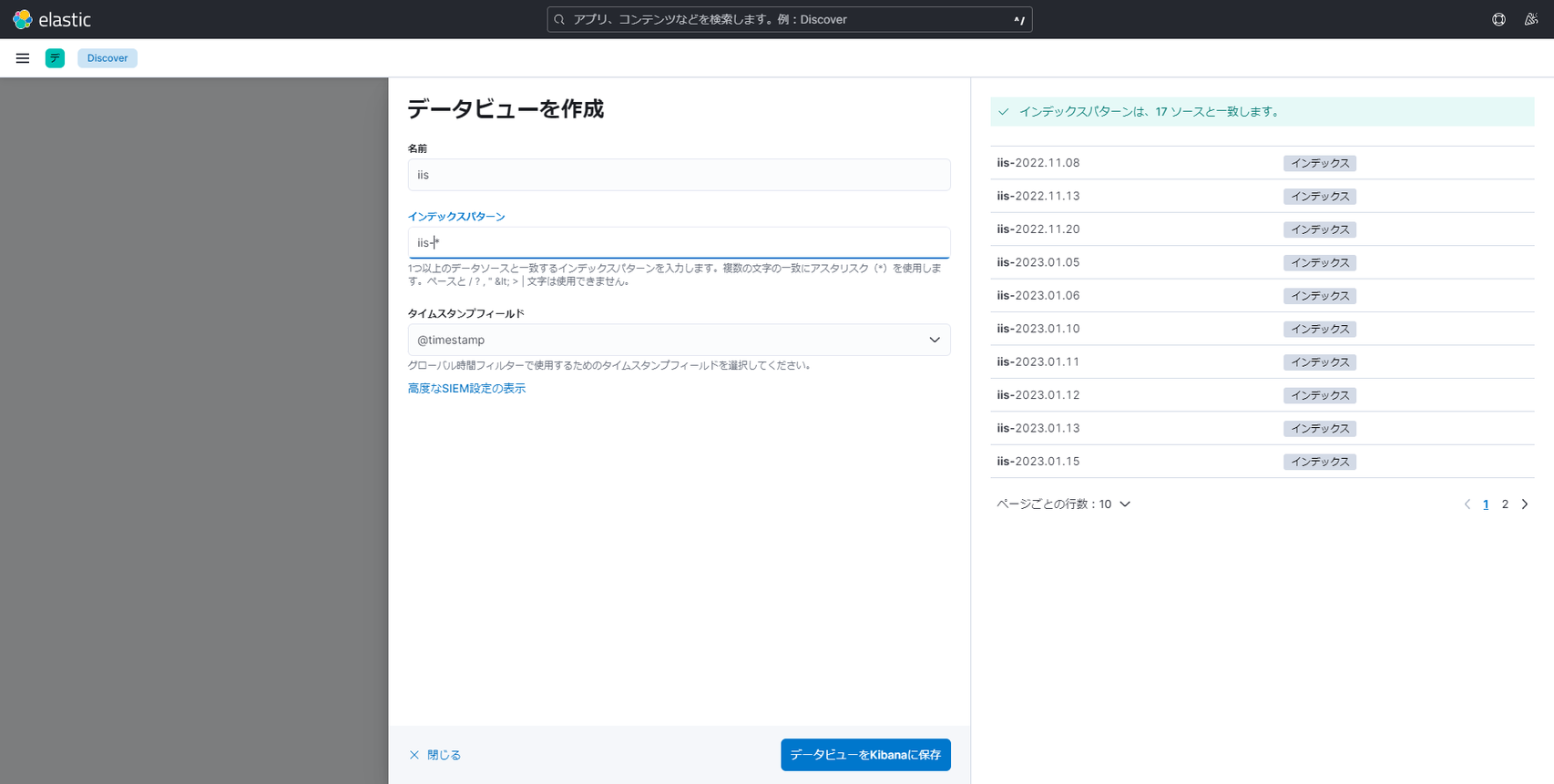
- データが存在している場合、「
-
Kibana > Analytics > Discover から、IIS ログが連携されたことを確認します。
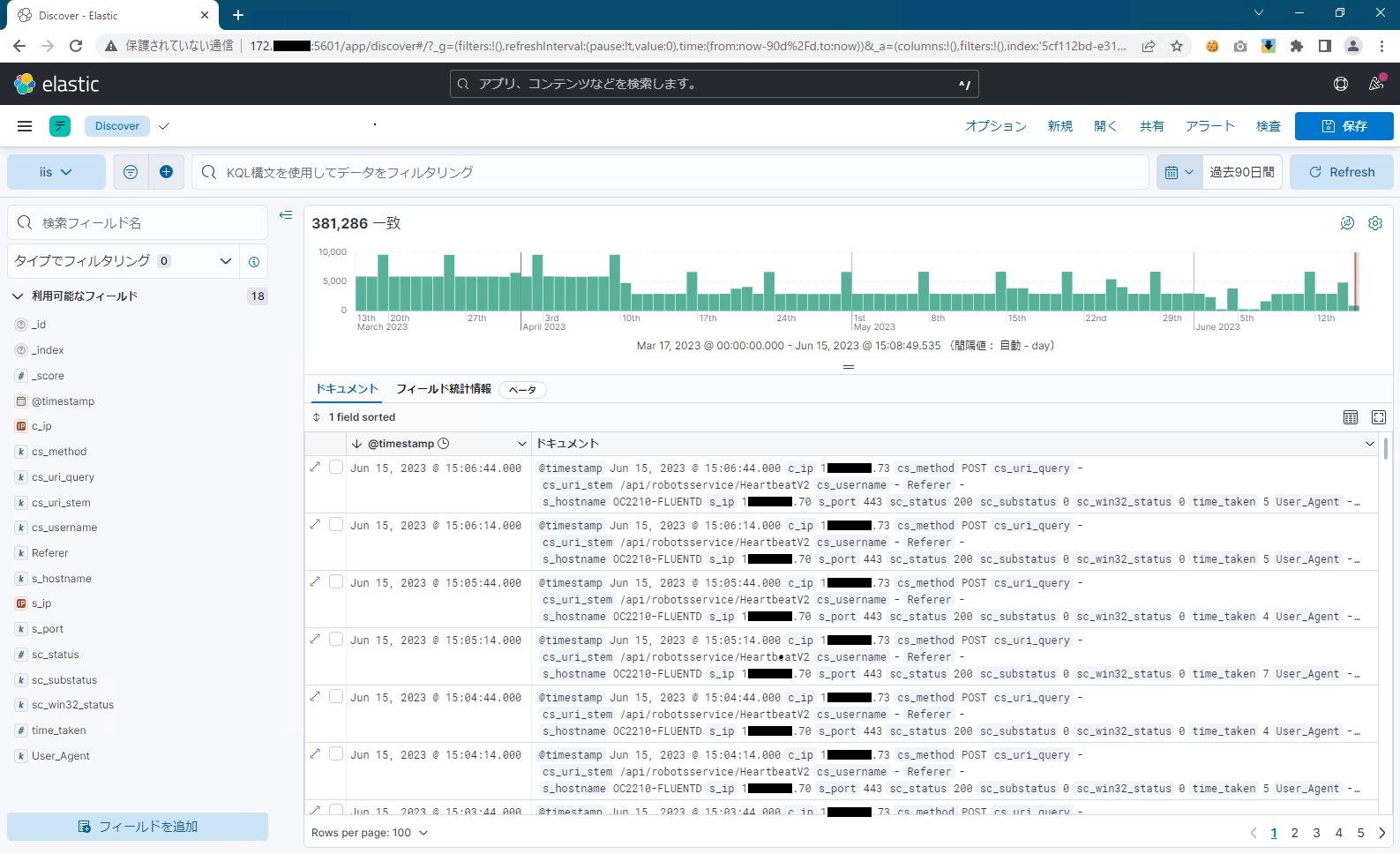
以上で、IIS アクセスログを Kibana で読み込むことができました。Kibana で IIS アクセスログを分析するには Dashboard を作成することが有効ですが、別の機会に譲ることとします。
TIPS 集
本記事の執筆時に遭遇した事象やそのトラブルシュート方法、必要になった設定や試してみた設定について解説します。
設定事例
Ubuntu 22.04 で SSH を有効化
- Ubuntu 22.04 の SSH サービスについて、ssh-rsa がデフォルトで無効のため、公開鍵認証を利用した SSH 接続ができません。
- Ubuntu 22.04 で SSH を有効にするには、パッケージがデフォルトで Ubuntu 22.04 のリポジトリにある
openssh-serverをインストールする必要があります。Ubuntu$ sudo apt install -y openssh-server $ systemctl restart ssh -
openssh-serverのインストールが完了したら、systemctlコマンドを使用してそのステータスを確認します。Ubuntu$ sudo systemctl status ssh - SSH サービスは実行中の状態です。これで、
ufwコマンドを使用して SSH ポートでの接続を許可します。Ubuntu$ sudo ufw allow ssh -
ufwの変更を保存するために、ufwを有効にしてリロードします。Ubuntu$ sudo ufw enable && sudo ufw reload - SSH クライアントをインストールします。
Ubuntu
$ apt -y install openssh-client - 任意の一般ユーザーで SSH サーバーに接続します。例えば
$ ssh efk-ubuntu2204@123.45.67.89など。Ubuntu$ ssh {hostname}@{ip-address} - SSH コマンドの引数にコマンドを指定することで、リモートホストで任意のコマンドが実行可能です。
Ubuntu
$ ssh {hostname}@{ip-address} "cat /etc/passwd"
- Ubuntu 22.04 で SSH を有効にするには、パッケージがデフォルトで Ubuntu 22.04 のリポジトリにある
Ubuntu での Root ユーザーの有効化
- Ubuntu 22.04 での root ユーザーのパスワード設定、デスクトップへのログイン、自動ログインなどのセットアップ方法を示します。
- Root ユーザーの初期設定をします。
Ubuntu
$ sudo -s $ passwd root - root ユーザーのデスクトップ (GUI) ログインを有効化します。
- custom.conf ファイルを編集します。
Ubuntu > /etc/gdm3/custom.conf
...(略)... [security] + AllowRoot=true ...(略)... - gdm-password ファイルを編集します。
Ubuntu > /etc/pam.d/gdm-password
...(略)... - auth required pam_succeed_if.so user != root quiet_success + #auth required pam_succeed_if.so user != root quiet_success ...(略)...
- custom.conf ファイルを編集します。
- Root ユーザーの初期設定をします。
トラブルシュート
エラー:Temporary failure resolving
-
apt-get updateやapt-get installの実行時に 「Temporary failure resolving」 エラーが出力され、失敗することがあります。- 下記のコマンドで resolv.conf を編集し、一時的に Google Public DNS を利用したら解決した。時間が経過するとエラーが再発することがあるため、その度に下記のコマンドを実行します。
resolv.conf の内容は DHCP で IP アドレスを割り当てられた際に自動的に上書きされます。下記のコマンドにより、Google DNS を永続的に使い続けることもできます。Ubuntu
$ echo "nameserver 8.8.8.8" | sudo tee /etc/resolv.conf > /dev/nullUbuntu$ echo "nameserver 8.8.8.8" | sudo tee /etc/resolvconf/resolv.conf.d/base > /dev/null
- 下記のコマンドで resolv.conf を編集し、一時的に Google Public DNS を利用したら解決した。時間が経過するとエラーが再発することがあるため、その度に下記のコマンドを実行します。
エラー:Temporary failure in name resolution
-
docker compose up -dで EFK スタックを起動する際に「Temporary failure in name resolution」エラーが発生する。-
docker compose up -dコマンド実行時のエラー内容Ubuntu[+] Running 0/0 ⠿ setup Error 0.0s ⠿ elasticsearch Error 0.0s ⠿ kibana Error 0.0s Error response from daemon: Get "https://docker.elastic.co/v2/": dial tcp: lookup docker.elastic.co: Temporary failure in name resolution - 上記のエラーは
docker compose up -dコマンド実行時に実行されるdocker pull docker.elastic.co/elasticsearch/elasticsearch:${ES_VERSION}コマンドにおいて、指定の Docker Image ファイルが見つからなかった為に発生しています。docker pullコマンドを実行すると上記と同じエラーメッセージが出力されます。 - 下記のコマンドで resolv.conf ファイルに DNS エントリ
8.8.8.8と8.8.4.4(Google の DNS サービスの IP アドレス) を追加することで解決しました。Ubuntu$ echo "nameserver 8.8.8.8" | sudo tee /etc/resolv.conf > /dev/null
-
Warning:mesg: ttyname failed: デバイスに対する不適切なioctlです
- root ユーザーでログイン後に下記のエラーが表示される場合は、後続の手順を実施します。
Ubuntu
エラーメッセージ/root/.profileの読み込み中にエラーがありました mesg: ttyname failed: デバイスに対する不適切なioctlです- .profile ファイルを編集する。
Ubuntu > /root/.profile
...(略)... - mesg n || true + #mesg n || true + if `tty -s`; then + mesg n + fi ...(略)... - また、docker Image をビルドすると「
mesg: ttyname failed: Inappropriate ioctl for device」というメッセージが出る場合があります。- 以下の一行を Dockerfile に追加すると出なくなりました。
Ubuntu
RUN sed -i -e 's/mesg n || true/tty -s \&\& mesg n/' /root/.profile
- 以下の一行を Dockerfile に追加すると出なくなりました。
- .profile ファイルを編集する。
以上です。