この記事は?
https://arxiv.org/pdf/2007.10257.pdf
(An Autoencoder Based Approach to Simulate Sports Games)
を精一杯理解しようとして足掻いた軌跡です。
読者対象者
スポーツの分析や、スポーツ好きな人だったら興味あるかもしれません!
それではどうぞ〜。
1.著者の方々
Ashwin Vaswani
Rijul Ganguly
Het Shah
Sharan Ranjit S
Shrey Pandit
Samruddhi Bothara
2.どちらの方々?
Birla Institute of Technology and Science Pilani
(略してBITS Pilaniというインドの大学のようです。)
3.いつの論文?
2020年7月16日[Submitted on 16 Jul 2020]
4.この論文では主に何の話をしているのか?
試合の統計情報(結果とか)を予測するだけでなく、チームがより良い準備をするための戦術分析にも利⽤できるデータ分析を提案する話。
最適な予測を⾏うことができるため、チームはこの予測を利⽤して対戦相⼿に対してより良い準備をすることができることも示している。
→今までもスポーツの結果の予測等はもちろん行われているが、その予測の裏付けや、洞察、内部統計がブラックボックス化していたので、そこを明瞭にしていくという話が主だと思います。明瞭だからこそ、試合の戦術分析にも使えますよ!ってことだと思います。
5.ちなみに過去はどうだったの?
ほとんどは結果を予測するだけで,その結果を裏付ける洞察や内部統計を提供していなかったということ。
そして、こういう細かいところまでの予測を行うための問題では、大抵⼤規模で、クリーンなデータセットがないそうです。その文章っぽいのが下記です。
(論文の文章)既存のデータセットの多くは、試合を要約したデータを提供していますが、興味を引くかもしれない試合のちょっとした複雑さにはあまり焦点が当てられていません。
4で言っている内容をもう一回言ってるかも。結果は予測してるけど、スタッツとかは導き出さないってことだと思います。サッカーだったら、ショートパスが多いのかとか、サイドからのセンタリングが少ないのかとか。そういう試合の内部データは予測出来てないよってことだと思います。
6.じゃあそれをどうやってこの論文では証明しているの?
6.1データセット
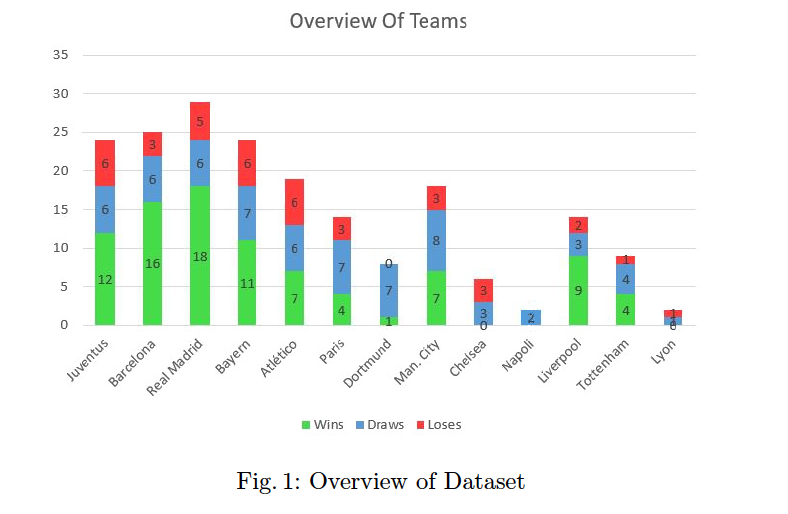
- 過去6年間に⾏われたチャンピオンズリーグの試合から、試合と個⼈の両⽅の統計データを集めたもの。
- データセットを構築するために、Official UEFA Champions Leagueのウェブサイトからデータをスクレイピングしている。2014年から2020年までのデータを使⽤します。全体で157のノックアウトステージの試合のデータを収集している。
6.2学習(学習してそうな文章丸々入れてるだけ^^;)
私たちのネットワークは,データ圧縮に広く用いられているオートエンコーダー[17]の考え方に基づいています.我々の学習プロセスの目的は,チームや選手の様々な特徴を学習することです.これを実現するために、潜在次元の埋め込みを学習することを目的としています。また、この潜在次元のデータは、データから予測できない他の要因からもロバストになるようにしたいと考えています。モデルの構成は、図3に示すとおりです。これにガウスノイズを加えることで、「ノイズの多い」埋め込みを実現します。これがネットワークへの入力となります。ガウスノイズを追加する直感的な理由は、データと一致しないいくつかの要因を考慮するのに役立つからです(例えば、プレイヤーがラッキーな日や悪天候の日、プレーに影響を与える気象条件など)。ガウスノイズなしの埋め込みを、グランドトゥルースラベルとして使用します。学習プロセスの概略を図4に示します。このようにして、モデルは、チームやプレイヤーのパフォーマンスに関する重要な洞察を学習し、後に、特定の試合の勝敗を決定する際に役立ちます。トレーニングでは、損失を平均二乗誤差とし、RMSE(root mean squared error)という指標を用いました。学習にはAdam Optimizerを使用し,学習率は0:01,バッチサイズは10個としました.学習と検証の過程で得られたRMSEの値は、新しい試合でのモデルのパフォーマンスを示すものではなく、モデルが埋め込みを学習する際の効率性を示すものです。チームモデルの学習RMSE値は0:1380、選手モデルの学習RMSE値は0:1127です。双方のモデルの検証RMSE値は、チームモデルが0:1379、選手モデルが0:1126と、トレーニングモデルにかなり近い値になっています。パイプラインの全体的なまとめを図4に示します。

7.この論文は何が肝?
7.1データの前処理に力を入れている
パスの完了などの分野での数百から、ゴールなどの分野でのわずか1〜2までの幅広い範囲の数値が含まれている。
このようなデータを何の前処理もせずに学習させてしまうと、あまりにデータの幅が広いので、正確にデータを捉えることができません。そこで、MinMax Scalingを⽤いて、データを0から1の範囲に正規化します。
桁数とか単位が違うとデータの処理がし辛いってことだと思います。
7.2チャンピオンズリーグの経験値
経験が浅いとプレッシャーによりパフォーマンスが落ちる
(チャンピオンズリーグに出たことないチームはオッズが高くなってしまうが、そこのメンタル面を考慮した前処理を施した。)
レアル・マドリードとかアトランタでは経験値の差があるので、それをどうやって予測に用いるかっていう話をしてますね。ちゃんとそこを考慮しないと、どうしてもアトランタの予測が「ブラックホース」的な扱いになってしまうそう。それはあんまりよくないとのこと。
7.3データ収集
上記でも書いたんですが、データ収集に力を入れている思います。たぶん。
このあたりはまた追記していければなと思ってます。
8.結論
たぶんこちらの論文は、すごく読みやすいように簡単に書かれている気がします。最後の「Conclusion and Future Work」のところだけ読んでも、時系列的な手法用いて過去から現在に向けての重み付けを変えたりとかって話もありました。(LSTMみたいなことなのかな・・・?)
不明瞭な段階で記事をアップしているので、皆さんを迷走させてたら申し訳ないのですが、アウトプットによる自己成長も目的としておりますので、初学者で共にアウトプットして成長しようとしている方いたら是非繋がりましょう〜。
それでは、ここまで読んで頂きありがとうございました!!!
補足的な
個人的に次に読んだほうがいいかなと思った論文
L. Maystreらによるガウス・プロセス・モデルに基づく研究
embeddings関連
☆単語解説☆
・Autoencoder
・ロバスト
・MinMax Scaling
・Embeddings
ガウスノイズ
RMSE