はじめに
機械学習の手法の一つに強化学習があります。現在では、深層強化学習(Deep-Q-learning)が注目されているが、その基本となるQ-learningを用いて迷路の探索を行うことを考えます。自身、強化学習を学びたての初心者ということもあり、そういった方に役立つ記事になればと思います。
強化学習
強化学習は、教師あり学習、教師なし学習と並ぶ機械学習の分類の一つである。強化学習では、エージェントが状態(state)を遷移する中で、状態を遷移する行動(action)選択の方法を学習する。しばしば神経科学の分野と結び付けられており、未知の環境に対して、人間が最適な行動を学習していく様に近いものと考えられる。強化学習では基本的に以下のパラメータが用いられ本記事でも下記に準じて記載を行なっている。
s : 状態 ( state )
a : 行動 ( action )
T : 遷移関数 ( transition function )
R : 報酬関数 ( reward function )
V : 価値関数 ( value function )
π : 方策 ( policy )
迷路問題の概要
迷路の構造は以下のように定める。

エージェントの設定として、エージェントは各状態について、上下左右のマスに移動できるものとする。また、グレーで塗られた壁の部分には移動することが出来ないことがわかっている。スタート地点(S)からゴール地点(G)に到達することを目的とし、到達するまで探索行い、到達するとエピソードが終了となり、スタート地点に戻る。
アルゴリズム
1. パラメータの決定
ここで、 はepsilon-greedy法のパラメータであり、最大価値関数の行動を行う確率を定めるパラメータである。epsilon-greedy法ではこの確率で、全ての行動からランダムに行動を決定し、その他の確率で最大価値関数の行動を行う。そのため、 は1より小さく1に近い値で用いられる。次には割引率である。価値ベースの強化学習においては、未来に得られる報酬を最大化するような行動を選択する。その中で、遠い未来に得られる報酬の価値を近い未来に得られる報酬よりも小さく与える働きを持つパラメータである。故に、通常は1より小さく、1に近い値が用いられる。最後に、 は学習率である。これは、TD学習法に用いられるパラメータである。TD学習においては、状態sにおいてある行動を行う際に見積もられる価値関数の値V(s)と、行動後の状態からの見積もりV(s’)とその行動で得られた報酬rの和を比較する。そして、その2つの値の内分点として価値関数の値V(s)を更新する。その内分点の重みを定める値が(学習率)である。学習率が小さいほど学習は安定するが、学習が遅くなってしまう問題が生じる。
2. 初期化
価値関数を0に初期化する。すなわち、迷路の各座標s = (x, y)について、V(s) = 0とする。
3.学習を行う
500回のエピソードを繰り返し、その中で価値観数の更新を行う。エピソードごとに次の手順を繰り返す。
エージェントの位置の初期化
エージェントを初期位置 (S)に置く。
行動の選択
次の時刻でのエージェントの位置を以下のepsilon-greedy方策で定める。
確率で、とする。ここで、s’は、現在の位置から移動できるマスである。壁方向には移動できず、移動できるマスの中で価値関数が最大になるマスへ移動する。
• 確率で移動できるマスにランダムに移動する。
瞬時報酬の計算
エージェントの新しい位置(s’)がゴール(G)ならば、r=1、そうでなければr=-0.04とする。
評価関数の更新
Q学習法では、
$Q(s,a)=(1-α)Q(s,a)+ α(r+γ max Q(s',a'))$
状態の更新
s’ がゴールでなければ、s ← s’ として、行動の選択に戻る。 すなわちエージェントが移動する。
コーディング
epsilon-greedy法による方策
def policy(self, s, actions):
if np.random.random() < self.epsilon:
return actions[np.random.randint(len(actions))]
else:
if s in self.Q and sum(self.Q[s]) != 0:
return np.argmax(self.Q[s])
else:
return actions[np.random.randint(len(actions))]
確率 ε で価値関数が最大となる行動を選択し、その他の確率で移動できるマスにランダムに移動する方策となっている。
報酬関数
def reward_func(self, state):
reward = self.default_reward
done = False
# Check an attribute of next state.
attribute = self.grid[state.row][state.column]
if attribute == -1:
# Get reward! and the game ends.
reward = 1
done = True
return reward, done
ゴール(-1)のマスに達した時に報酬1を獲得し、それ以外の移動できるマスに移動した際には-0.04の標準報酬を獲得する。
移動を行う関数
def _move(self, state, action):
if not self.can_action_at(state):
print(state.row, state.column)
raise Exception("Can't move from here!")
next_state = state.clone()
# Execute an action (move).
if action == 0:
next_state.row -= 1
elif action == 1:
next_state.row += 1
elif action == 2:
next_state.column -= 1
elif action == 3:
next_state.column += 1
# Check whether a state is out of the grid.
if not (0 <= next_state.row < self.row_length):
next_state = state
if not (0 <= next_state.column < self.column_length):
next_state = state
# Check whether the agent bumped a block cell.
if self.grid[next_state.row][next_state.column] == 9:
next_state = state
return next_state
方策で定められた行動を行う関数である。行動によってエージェントの位置を移動し、その地点が壁のマス(9)になっていないかを確認し、移動後の状態を出力する。
学習を行うプログラム
def learn(self, env, episode_count=500, gamma=0.9, learning_rate=0.1, render=False, report_interval=50):
self.init_log()
self.Q = defaultdict(lambda: [0] * len(actions))
actions = list(range(4))
for e in range(episode_count):
s = env.reset()
done = False
count = 0
while not done:
if render:
env.render()
can_actions = env.can_action(s, actions)
a = self.policy(s, can_actions)
n_state, reward, done = env.step(a)
gain = reward + gamma * (max(self.Q[n_state]))
estimated = self.Q[s][a]
self.Q[s][a] += learning_rate * (gain - estimated)
s = n_state
アルゴリズムの3で述べた一連の処理が行われている。ここでの評価関数の更新の方法がQ学習法の肝となる所である。
シミュレーション結果
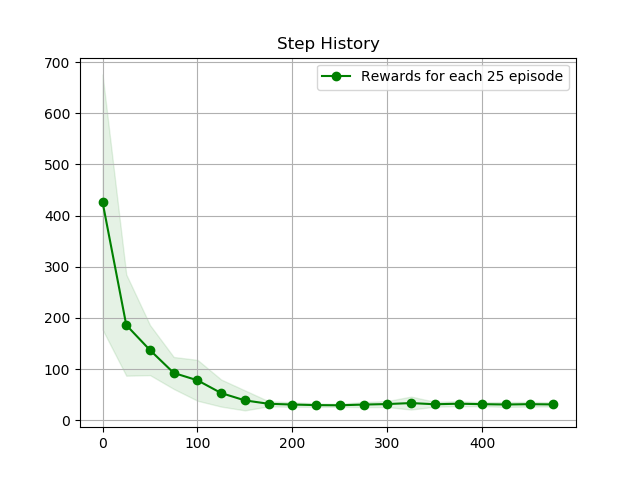
探索を行った25エピソードごとにゴールまでの平均ステップ数をプロットした。最小ステップである25付近に漸近していることが分かる。
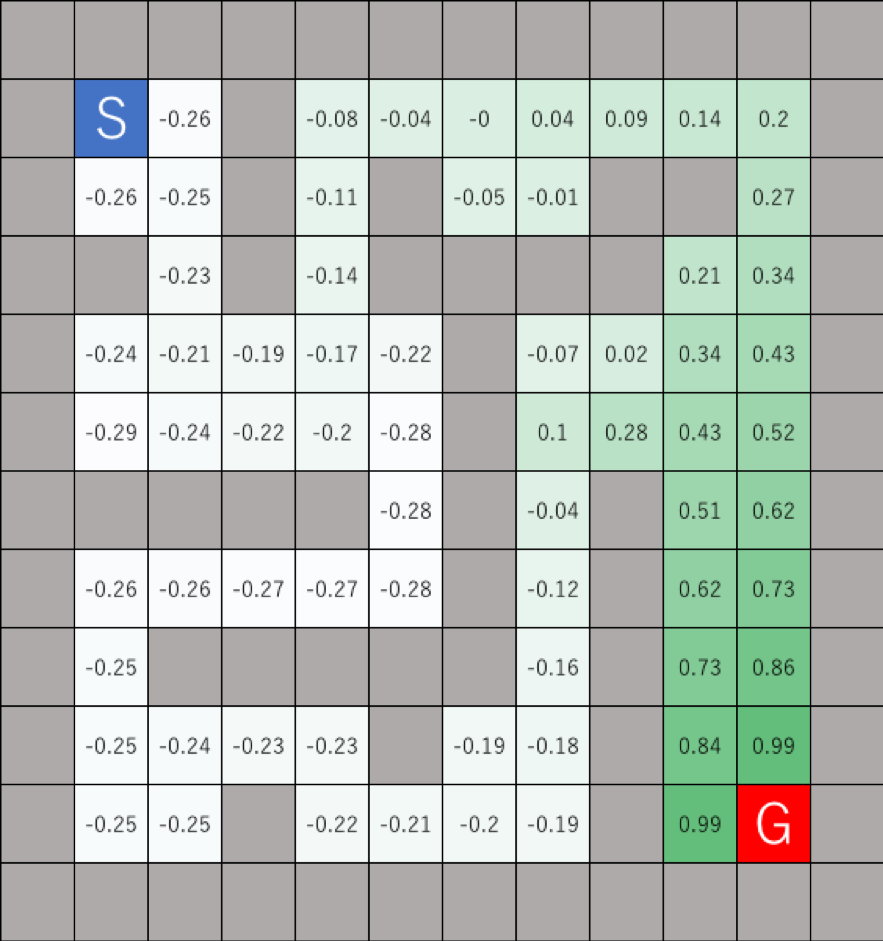
また、学習終了時の各マスの価値関数の最大値を各マスに入力し、その大きさによって色分けをした。
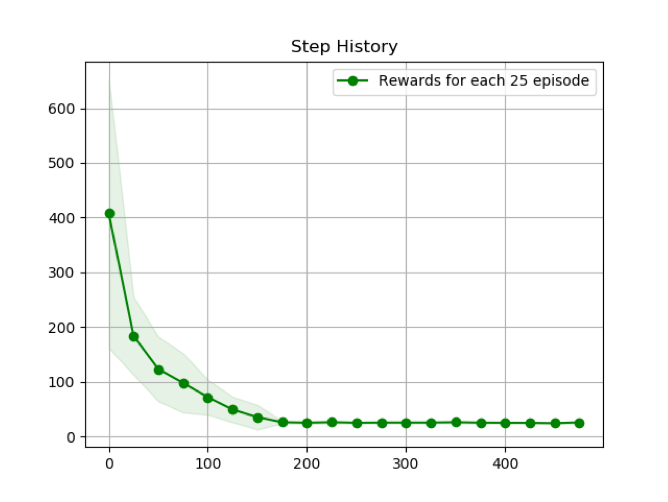
次に、ε の値を変化させて実験をいくつか行った。
ε=0.05
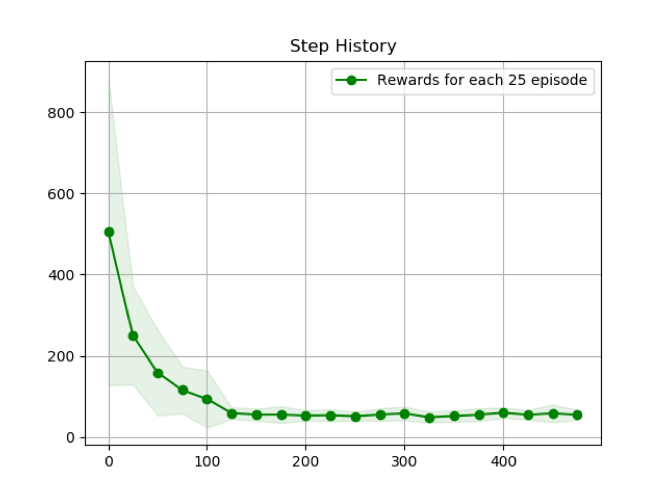
ε=0.50
ε=0.80
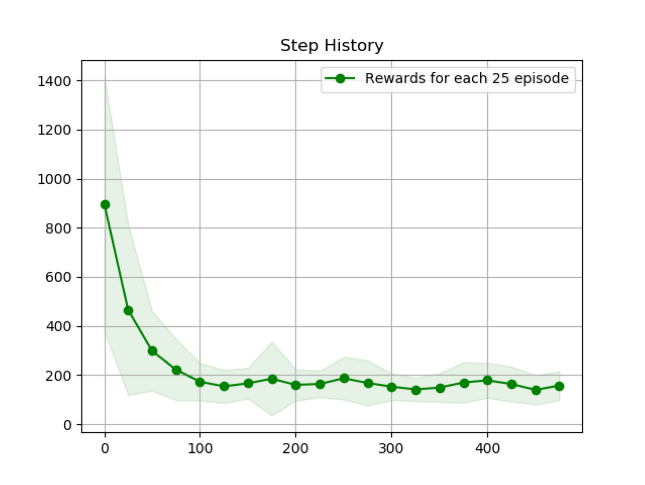
εを大きくすることで、探索がより進み、平均ステップ数の収束が早くなっていることが分かる。しかしながら、εを大きくすることで、収束した平均ステップ数の値が大きくなってしまうこと、分散が大きくなってしまっていることが見られる。これはεは探索と利用のトレードオフのパラメータであり、εを大きくすることで、探索優先度が上がり、様々な状態について学習が進むが、その利用が少ないために、学習による最効率の結果がでないという結果となった。逆に、εの値を小さくすることで、探索による学習の進行は遅くなってしまうが、利用の優先度が高く、最終的には最適な行動を取り続けていると考えられる。
まとめ
Q-learningで迷路の探索を行った。また、ε の値を変化させていくつかの実験を行い、ε の値の寄与が実験において確認できた。
サンプルコード:https://github.com/MizutaniMorihiro/Q-learning
参考文献
久保隆宏: Pythonで学ぶ強化学習, 講談社, (2019)
浅田稔, 麻生英樹, 荒井幸代, 飯間等, 伊藤真, 大倉和博, 黒江康明, 杉本徳和, 坪井祐太, 銅谷賢治, 前田新一, 松井藤五郎, 南泰浩, 宮崎和光, 目黒豊美, 森村哲郎, 森本淳, 保田俊行, 吉本潤一郎 : これからの強化学習, 森北出版, (2016)