概要
コサイン類似度を使ったTwitteで記事推薦を行うWebRecommendというアプリケーションを2012年あたりに作っていたので、忘れてしまっているけど、ソースを読み解きつつ、メモしていきます。
WebRecommendとは
WebRecommendは何かというと、
Twitterのユーザに対し、おすすめの記事を見つけ出して、Twitterのタイムラインに書き込むというサービスを作っていました。
↓のように毎日twitterにおすすめの記事が投稿されるようなものです

WebRecommendの仕組み
Twitter連携部分などは本質と関係ないため省きます。
WebRecommendではツイッターのユーザー情報を見て、ユーザの興味関心のある単語を抽出します。
よくツイッターのユーザー情報の欄に自己紹介や、興味のあるものを書いている人がいますよね。
それを利用しています。
そのユーザーのプロフィール情報だけでは、情報が少ないので、
そのユーザーがフォローしているユーザは、そのユーザが興味のあるユーザ
つまり、そのユーザのフォローしているユーザのプロフィールも関心事である
と仮定し、フォローしているユーザのプロフィール情報も利用しています。

アルゴリズム
1.ユーザのタームベクトルを作成する
Twitterでそのユーザのプロフィール情報とフォロワーのプロフィール情報を集め、
形態素解析をして、キーワードからタームベクトルを作成します。
例:
ユーザAがユーザBとユーザCをフォローしているとします。
それぞれのユーザのプロフィール情報に下記情報が書いてあるとします。
ユーザAのプロフィール:プログラミング、アニメ、バナナが好きです。
ユーザBのプロフィール:アニメ、ゲーム、リンゴが好きです。
ユーザCのプロフィール:プログラミングゲームが好きです。
このプロフィールを結合して、形態素解析してキーワードとその頻度を取り出してベクトルを作ります。
ユーザAのタームベクトル
| 単語 | 頻度 |
|---|---|
| プログラミング | 2 |
| アニメ | 2 |
| ゲーム | 2 |
| バナナ | 1 |
| りんご | 1 |
| これでもいいのですが、ユーザAのプロフィールに直接書かれてある「プログラミング」と、直接書かれていない「ゲーム」が同じ2の値になってしまっています。 | |
| なので、ユーザAのプロフィール情報に重みを付けて2倍にすることにします。 |
| 単語 | 頻度 |
|---|---|
| プログラミング | 3 |
| アニメ | 3 |
| ゲーム | 2 |
| バナナ | 2 |
| りんご | 1 |
これでユーザAのタームベクトルの完成です。

2.記事の取得
WebRecommendでは記事の取得には、はてなブックマークのAPIを利用しています。
http://b.hatena.ne.jp/keyword/}任意のキーワード}?mode=rss
ここで用いるキーワードとして 1.で作成したユーザーのタームベクトルを利用します。
出現の頻度の高いキーワード順で上位10件で検索を行うようにしています。
例:
プログラミングが語の出現頻度が高いのでプログラミングで検索して記事を取得
http://b.hatena.ne.jp/keyword/プログラミング?mode=rss
3.記事のタームベクトルを作成
2.取得した記事に対してそれぞれタームベクトルを作成します。
作成方法は、1とあまり変わりありません。
記事のdescriptionを形態素解析をしてタームベクトルを作成します。
例:
記事のdescription:
PC初心者でもできる、ゲームプログラミング講座。簡単なシューティングゲームを作っていきます。
このdescriptionのタームベクトルを作成します。
| 単語 | 頻度 |
|---|---|
| ゲーム | 2 |
| プログラミング | 1 |
| シューティング | 1 |
| PC | 1 |
| 初心者 | 1 |
| 講座 | 1 |
| 簡単 | 1 |
こんな感じのタームベクトルが出来上がります。
4.類似度を計算する
類似度の計算にはコサイン類似度という方法を使います。
今回ユーザAのタームベクトルと、記事のタームベクトルを作成しました。
この2つのベクトルを比較することにより類似度を調べます。
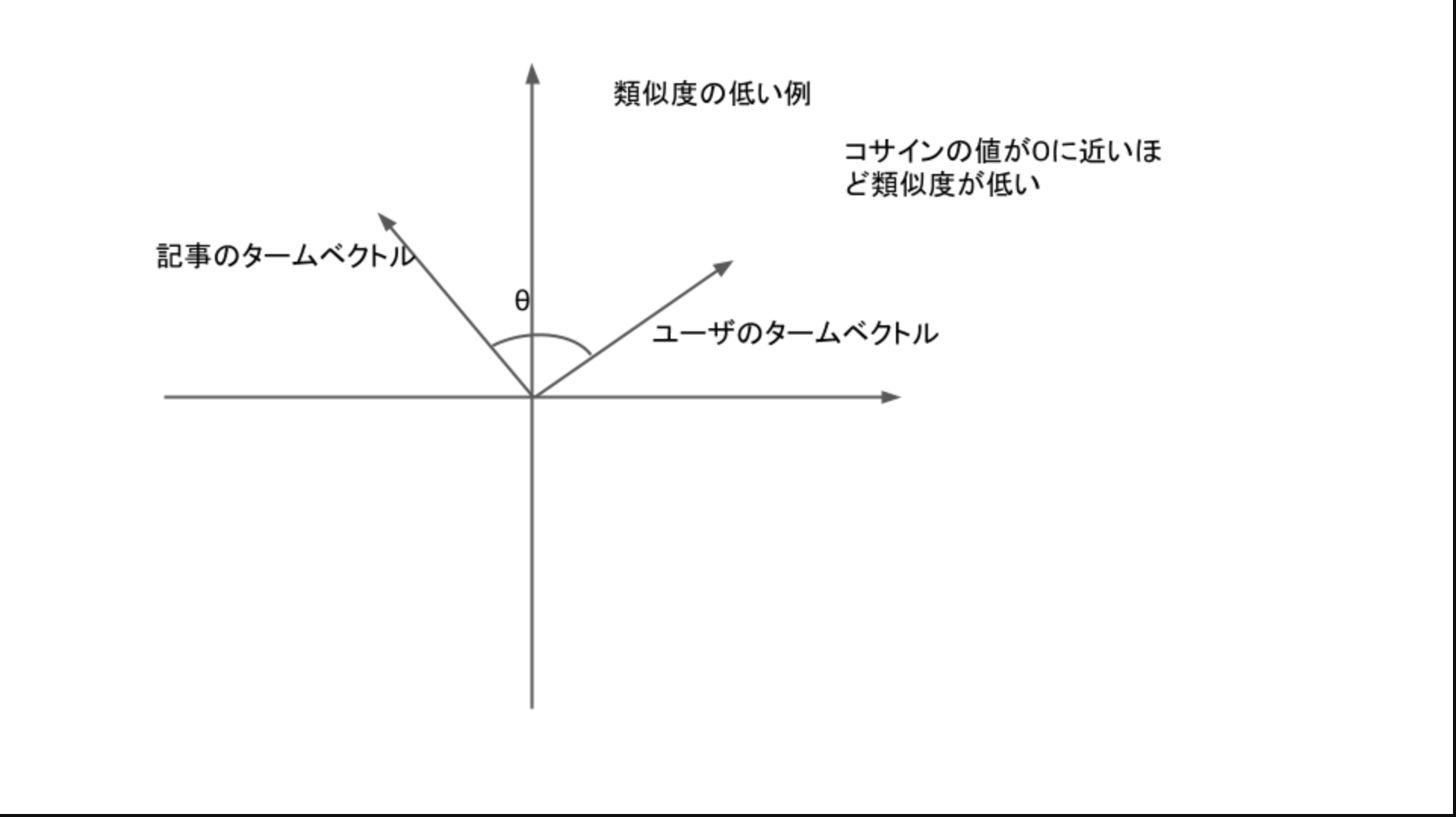
この2つのベクトルのなす角が小さいほど似ているということになります。
つまりこの2つのベクトルのcosの値が1に近いほど類似していて、0に近いほど類似していないということになります。
類似度の高い例

類似度の低い例
コサインを求める式は
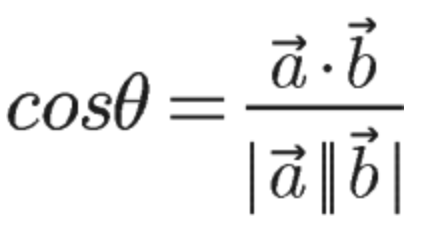
という式で求められます。
aとbを正規化していれば、ベクトルの各要素の2乗の和は1となるので、分母部分が1になるので下記式で求められます。
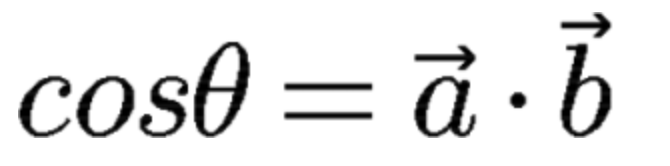
今回は、計算を行う前にまずベクトルを正規化します。
xは(x1,x2….xn)のベクトルとすると、
下記式でベクトルxの正規化を行えます

例を元に実際に類似度を計算してみます。
ユーザのタームベクトルの正規化
分母の部分を求める
(3^2+3^2+2^2+2^2+1^2)^(1/2) = 27^(1/2)≒5.196
各要素を5.196で割っていくと
| 単語 | 値 |
|---|---|
| プログラミング | 3/5.196 = 0.577 |
| アニメ | 3/5.196 = 0.577 |
| ゲーム | 2/5.196 = 0.384 |
| バナナ | 2/5.196 = 0.384 |
| りんご | 1/5.196 = 0.192 |
これが正規化されたユーザのベクトルになります。
同様に記事のベクトルも正規化します。
分母の部分を求める
(2^2+1^2+1^2+1^2+1^2+1^2+1^2)^(1/2) = 10^(1/2)≒3.162
| 単語 | 値 |
|---|---|
| ゲーム | 2/3.162 = 0.632 |
| プログラミング | 1/3.162 = 0.316 |
| シューティング | 1/3.162 = 0.316 |
| PC | 1/3.162 = 0.316 |
| 初心者 | 1/3.162 = 0.316 |
| 講座 | 1/3.162 = 0.316 |
| 簡単 | :1/3.162 = 0.316 |
| これが正規化された記事のベクトルとなります。 |
いよいよコサインの値(類似度)を求めてみます。
一度表にまとめると
| 単語 | ユーザベクトル | 記事ベクトル |
|---|---|---|
| プログラミング | 0.577 | 0.316 |
| アニメ | 0.577 | |
| ゲーム | 0.384 | 0.632 |
| バナナ | 0.384 | |
| りんご | 0.192 | |
| シューティング | 0.316 | |
| PC | 0.316 | |
| 初心者 | 0.316 | |
| 講座 | 0.316 | |
| 簡単 | 0.316 |
ユーザベクトル・記事ベクトルの計算をします。
各要素を掛けあわせて足せばいいですね。
実際にはスパースなベクトルなので、共通要素部分だけの計算になります。
計算すると。。。
0.577 * 0.316 + 0.384 * 0.632 = 0.425
このユーザに対するこの記事の類似度は0.425となることが分かりました。
同様の手順で取得した記事に対しユーザベクトルと記事のベクトルの類似度を計算し、
類似度に高い順で表示することで、レコメンドが可能となります。
以上がWebRecommendのアルゴリズムになります。
やっていることは基本的な集合知プログラミングになります。