背景
基本的なファンクションですが、よく考えないと迷路に迷い込みそうなのでここにメモしておきます。
FPGA 化するアルゴリズムのネタとして、ポリゴンを描画するためのアルゴリズムを考えてみます。
全てを FPGA 化するのは大変なので、見えているポリゴンの抽出と頂点変換は CPU で出来ているとします。従って、後は三角形を描画することが FPGA でやるべき仕事となります。
三角形の分割
まず、一般の三角形を X 軸に沿って分割します。
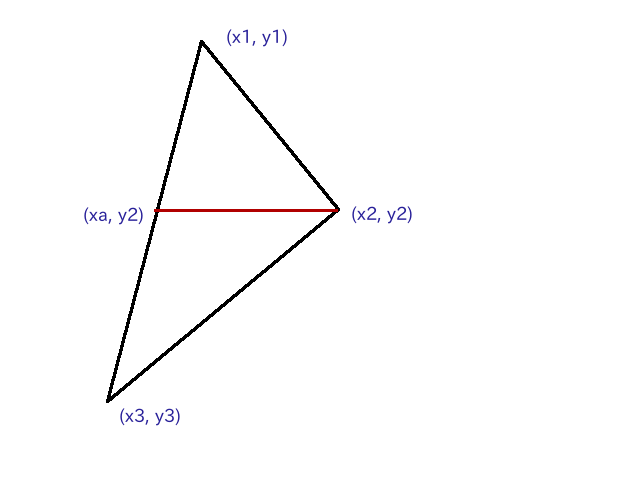
図で y1, y2 が等しい時または y2, y3 が等しい時は分割は行わず、以降のアルゴリズムを適用します。
$x_a$ の座標は
x_a = \frac{y_2 - y_1}{y_3 - y_1}x_3 + \frac{y_2 - y_3}{y_1 - y_3}x_1
で求めることができます。以降は$y_2$と$y_3$が等しいものとして話を進めます。また、$x_2$と$x_3$は等しくないものとします。等しい場合は頂点番号を振り直します。
振り直しても等しくなる場合は頂点が一直線に並んでいて三角形ではないので除外します。
X 軸方向の描画
$(x_1, y_1)$の頂点色を$c_1$、$(x_2, y_2)$の頂点色を$c_2$、$(x_3, y_2)$の頂点色を$c_3$とします。頂点が囲む中間の点の色は OpenGL のように頂点色を内挿したグラデーション色をつけるものとします。1ドットX軸に水平な方向に移動した時の色の増分は
\Delta c = \frac{c_3 - c_2}{x_3 - x_2}
となりますが、割り算をなくすために割る数と割られる数を別々に考えます。
# define abs(x) ((x) >= 0) ? (x) : (-x))
# define sgn(x, d) ((x) > 0) ? (d) : ((x) < 0) ? (-d) : 0)
// この関数はハードウェア化する
void draw_Xaxis(volatile unsigned int *vram, int x2, int x3, int c2, int c3) {
int d = 0;
int c = c2;
int x = x2;
int adx = abs(x3 - x2);
int sdx = sgn(x3 - x2, 1);
int adc = abs(c3 - c2);
int sdc = sgn(c3 - c2, 1);
int dc = (sdx == sdc) ? 1 : -1;
if (adx == 0) {
// 書き込みが一点のケース
vram[x] = c;
return;
}
for (int pos = 0; pos <= adx; x += sdx, pos++) {
vram[x] = c;
d += adc;
while (d >= adx) {
c += sdc;
d -= adx;
}
}
}
while ループがちょっとダサイ感じですが、一応割り算は回避できます。
Y軸方向の移動
Y軸方向を移動して1ドット$(x_1, y_1)$に近づいた時、線分 $(x_1, y_1) - (x_2, y_2)$、$(x_1, y_1) - (x_3, y_2)$のXの増分はそれぞれ
\Delta x_a = \frac{x_1 - x_2}{y_1 - y_2},
\Delta x_b = \frac{x_1 - x_3}{y_1 - y_2}
色については
\Delta c_a = \frac{c_1 - c_2}{y_1 - y_2},
\Delta c_b = \frac{c_1 - c_3}{y_1 - y_2}
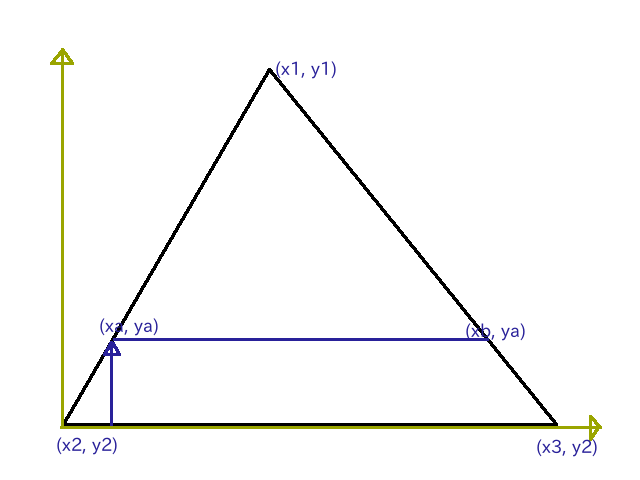
となるので、同じように割り算をなくすと
# define SCREEN_WIDTH <screen_width>
// この関数はハードウェア化する
void draw_flatTriangle(volatile unsigned int *vram, int x1, int y1, int x2, int y2, int x3, int c1, int c2, int c3) {
int ady = abs(y1 - y2);
int sdy = sgn(y1 - y2, 1);
int sdys = sgn(sdy, SCREEN_WIDTH);
int adxa = abs(x1 - x2);
int sdxa = sgn(x1 - x2, 1);
int adxb = abs(x1 - x3);
int sdxb = sgn(x1 - x3, 1);
int adca = abs(c1 - c2);
int sdca = sgn(c1 - c2, 1);
int adcb = abs(c1 - c3);
int sdcb = sgn(c1 - c3, 1);
int dxa = (sdxa == sdy) ? 1 : -1;
int dxb = (sdxb == sdy) ? 1 : -1;
int dca = (sdca == sdy) ? 1 : -1;
int dcb = (sdcb == sdy) ? 1 : -1;
int xa = x2;
int xb = x3;
int ca = c2;
int cb = c3;
int xda = 0;
int xdb = 0;
int cda = 0;
int cdb = 0;
int y = y2;
for (int ypos = 0; ypos <= ady; y += sdys, ypos++) {
draw_Xaxis(&vram[y], xa, xb, ca, cb);
xda += adxa;
while (xda >= ady) {
xa += dxa;
xda -= ady;
}
xdb += adxb;
while (xdb >= ady) {
xb += dxb;
xdb -= ady;
}
cda += adca;
while (cda >= ady) {
ca += dca;
cda -= ady;
}
cdb += adcb;
while (cdb >= ady) {
cb += dcb;
cdb -= ady;
}
}
}
となります。
一般的な三角形から出発すると従って、
# define swap(a,b) { int tmp = a; a = b; b = tmp; }
// この関数は CPU で計算する
void draw_triangle(volatile unsigned int *vram, int x1, int y1, int x2, int y2, int x3, int y3, int c1, int c2, int c3) {
// y1 < y2 < y3 となるように並べ直す
if (y1 > y2) {
swap(x1, x2);
swap(y1, y2);
swap(c1, c2);
}
if (y1 > y3) {
swap(x1, x3);
swap(y1, y3);
swap(c1, c3);
}
if (y2 > y3) {
swap(x2, x3);
swap(y2, y3);
swap(c2, c3);
}
// 例外的なパターンの排除
if (y1 == y3) {
return;
}
if (x1 == x2 && x2 == x3) {
return;
}
if (y1 == y2) {
draw_flatTriangle(vram, x3, y3, x1, y1, x2, c3, c1, c2);
} else if (y2 == y3) {
draw_flatTriangle(vram, x1, y1, x2, y2, x3, c1, c2, c3);
} else {
int xa = x1 * (y2 - y1) / (y3 - y1) + x3 * (y2 - y3) / (y1 - y3);
int ca = c1 * (y2 - y1) / (y3 - y1) + c2 * (y2 - y3) / (y1 - y3);
draw_flatTriangle(vram, x1, y1, xa, y2, x2, c1, ca, c2);
draw_flatTriangle(vram, x3, y3, xa, y2, x2, c3, ca, c2);
}
}
となります。
テクスチャを貼る場合は色を$u,v$に置き換えて得られた座標値を元に、テキスチャメモリからデータを読みだして vram にコピーすればいいはず。(アンチエイリアジングしなければ)
for の中に while があるので PIPELINE 化は難しいかも知れません。
[2017.4.11修正]プログラムのバグを修正しました。
[2017.4.11追記]2016.4版 Vivado HLS シミュレータは関数に &vram[y] を渡すと SIGSEGV が発生します。vram アドレスとオフセットは別に渡したほうがよさそうです。