この記事のハンズオンでは、GoogleスライドをAIに作らせます。
PowerPointo版の手順も公開しましたので、お好きな方をご活用ください。
この記事は何?
生成AIブームは終わりが見えませんが、そろそろRAGは十分試したよという方も多いのではないでしょうか。次のトレンドと目されているのが、人間の代わりに自動で仕事してくれる「AIエージェント」です。
AWSクラウドの生成AIサービス「Amazon Bedrock」には、そんなエージェントを簡単に作れるマネージドサービス 「Agents for Amazon Bedrock」 という機能があります。
これを使えば、難しいPythonのコードをたくさん書かなくても、AWSのマネジメントコンソールでGUIをポチポチやるだけで賢いエージェントが作れてしまいます。
今回作るアプリ
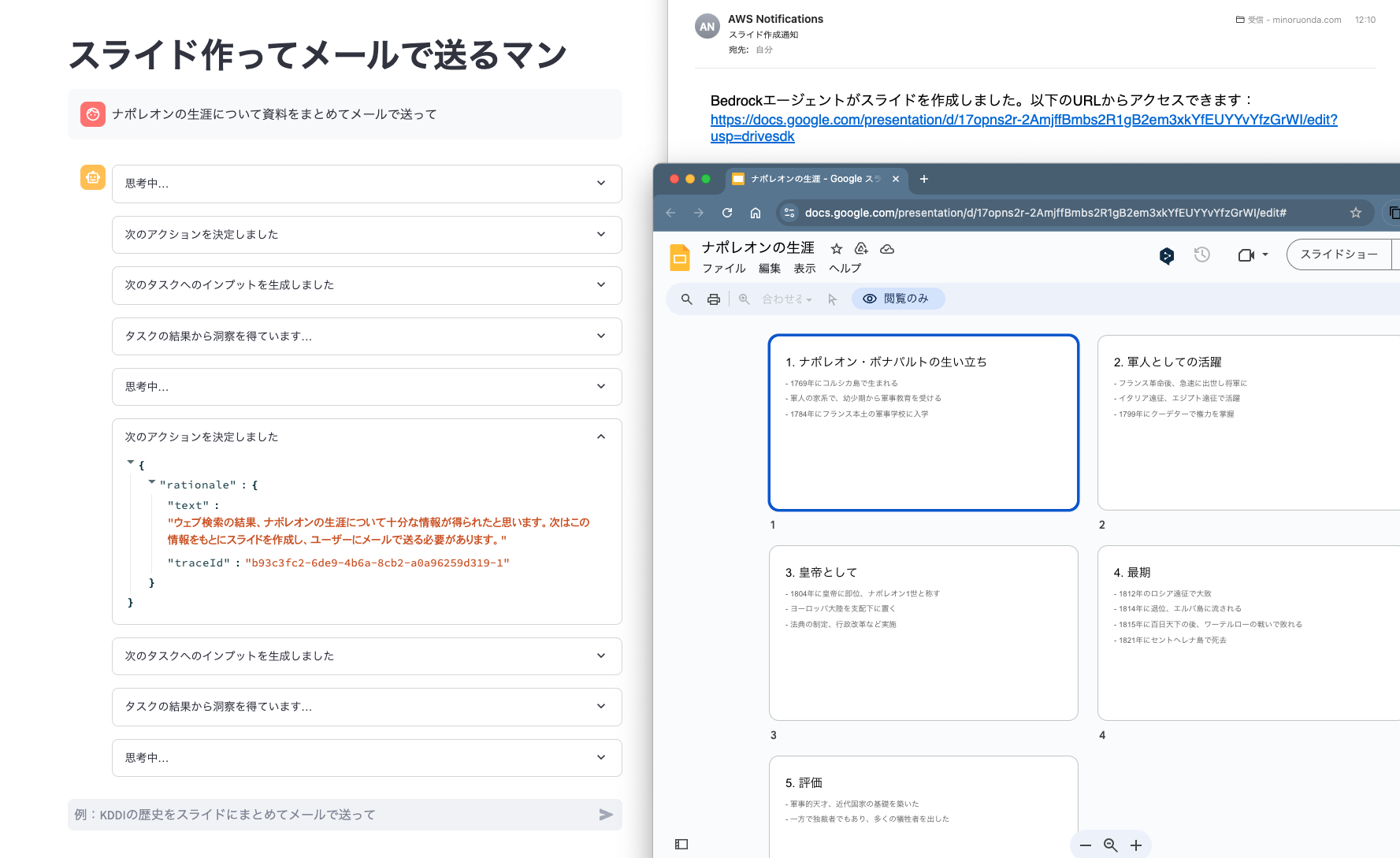
ユーザーが「xxxについて資料にまとめて」と依頼すると、
- Web検索して情報を集める
- Googleスライドで資料を作成する
- 作成したスライドURLをユーザーにメールで送る
という流れを自動でやってくれます。
不明点があればユーザーに聞き返しますし、AIは各作業の結果をうけて次のアクションを柔軟に調整します。(例:メールの送信に失敗したら結果をチャット画面上に表示するなど)
アーキテクチャ

Web検索に利用しているDuckDuckGoは、APIキーが不要で使えるためお手軽です。
今回は含めていませんが、ここに「ナレッジベース」機能でRAGを組み合わせて社内文書を検索させることも可能です。
そもそもBedrockって何?
色んなAIモデルをAPIとしてサーバーレスで利用できる、AWSの機能です。
概要資料をまとめていますので、ご興味ある方はご覧ください!
ハンズオン手順
基本的にWebブラウザがあれば実施できます。
すべてサーバーレスで構築していますので、費用もかなり少額で済むはずです。
1. GoogleスライドAPIの利用設定
今回はAIにGoogleスライドで資料を作ってもらうため、Google Cloudの設定が必要になります。
Googleアカウント作成
以下より新規Googleアカウントを作成しましょう。
同じ電話番号で複数のGoogleアカウントを作るとエラーになるときがあるので、その際は既存のアカウントを流用しましょう。
Google Cloudプロジェクト作成
以下ドキュメントにある「リソースの管理に移動」という青いボタンをクリックします。
Google Cloudの利用規約に同意して、ポップアップを閉じます。
画面上部の「プロジェクトを作成」をクリックします。

bedrock-agent という名前のプロジェクトを作成しましょう。
スライド・ドライブAPI有効化
画面上部の検索バーで slide と入力し、「Google Slides API」にアクセスします。

先ほど作成した bedrock-agent プロジェクトでの操作になっていることを確認し、Slides APIを「有効にする」をクリックします。

同様に、次は drive と検索して「Google Drive API」も有効にしましょう。

サービスアカウント作成
次に、これらのAPIをAIエージェントに使わせられるように、Google Cloudの認証情報を作成します。
「サービスアカウント」の画面を検索して、「+サービスアカウントを作成」をクリックします。

- サービスアカウント名:
bedrock-agent - ロール:
編集者(クイックアクセス > 基本 より)
他は入力なしで大丈夫です。

作成したサービスアカウントをクリックし、「キー」タブから「新しい鍵を作成」します。キーのタイプはJSONにしましょう。
作成した認証鍵のJSONファイルは、作業PCのデスクトップなど分かりやすいところに保存しておきます。認証情報なので第三者に漏れないよう注意しましょう。
2. AWSアカウント作成
以下を参考に、AWSアカウントを新規作成しましょう。
メールアドレスには、前述のGoogleアカウントのGmailアドレスを利用してもいいですね。
アカウント作成したら、以下URLよりAWSマネジメントコンソールにサインインします。
サインインしたら、右上のリージョンを「バージニア北部」に切り替えておきましょう。

このハンズオンでは、バージニア北部リージョンのみを利用します。
(Claude 3 Haikuを使えば東京リージョンでも実施可能です)
3. Bedrock設定
次はいよいよ生成AIサービスの設定です。
モデル有効化
Amazon Bedrockのコンソールを検索し、画面右下の「モデルアクセス」にアクセスして、Anthropic社のClaude 3 Sonnetを有効化しましょう。

用途の申告が求められるので、所属会社の情報や、用途が個人検証であることなどを簡単に入力しましょう。
エージェント作成
次に「エージェント > エージェントを作成」を実施します。

エージェント名は pawapo-master など分かりやすい名前をつけて「作成」をクリックします。
エージェントビルダーという編集画面が開くので、以下のとおり設定します。
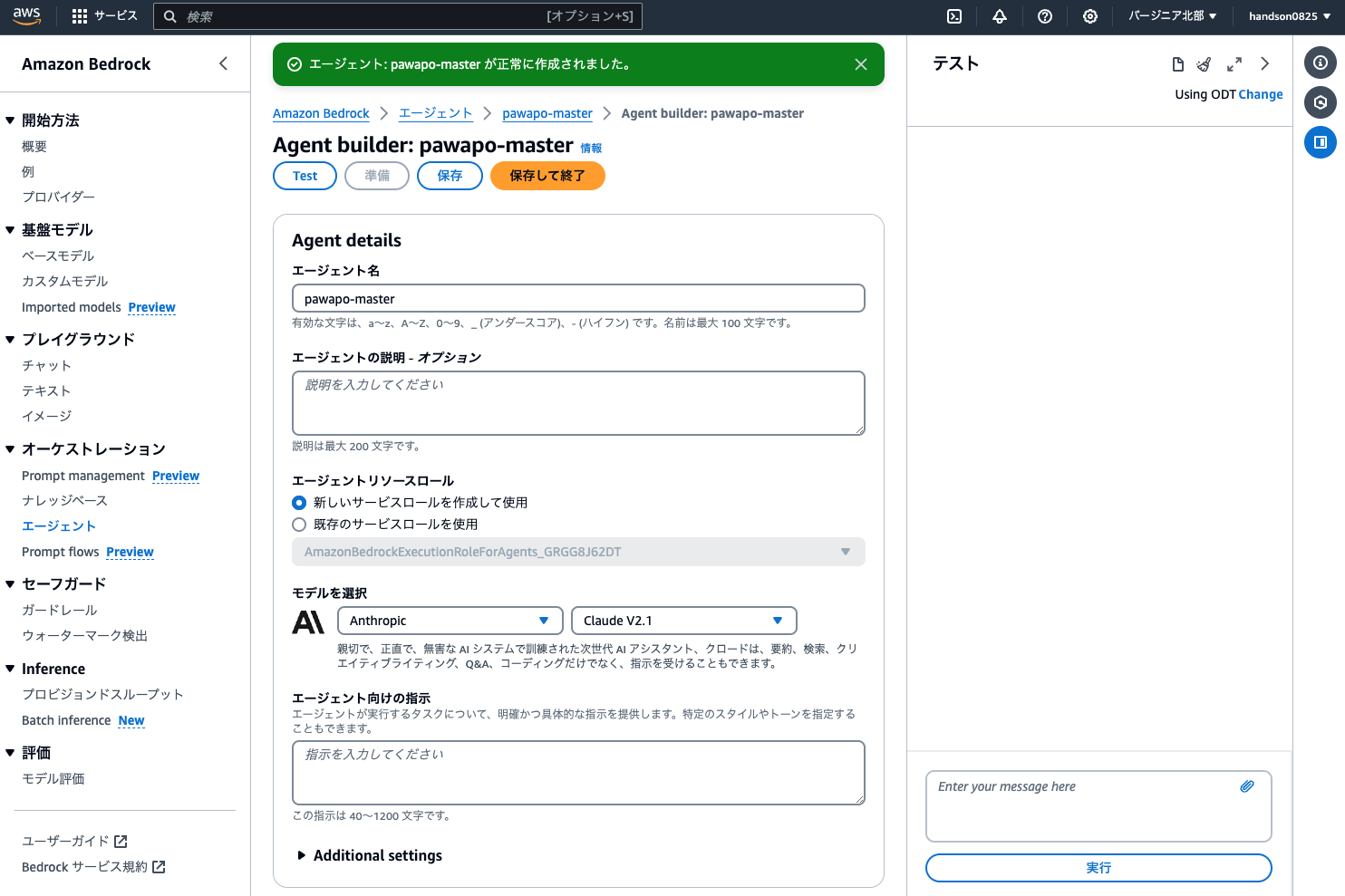
- モデルを選択: Anthropic > Claude 3 Sonnet
- エージェント向けの指示:
- ユーザーからの依頼をもとに、テーマについてWeb検索を行い、Googleスライドに調査結果をまとめてください。
- スライドは6ページを目安とし、各ページには必ずタイトルと、内容を箇条書きで複数含めてください。
- 作ったスライドのURLはユーザーにメールで送信してください。
- すべての処理が終わったら、ユーザーへはメールを送信したことを伝えてください。
- Additional settings
- ユーザー入力: Enabled
上記が設定できたら、画面上部の「保存」をクリックします。
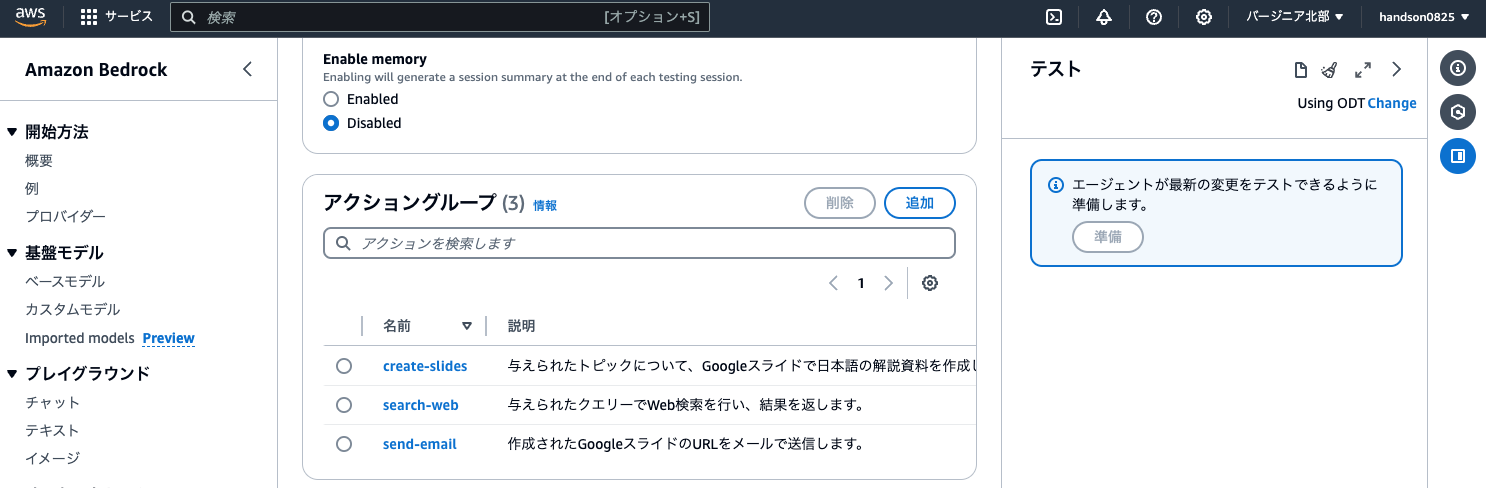
アクショングループ追加
Bedrockのエージェントでは、AIが実行できるタスクを「アクショングループ」として定義します。今回は「Web検索」「スライド作成」「メール送信」の3つのアクショングループを作成します。
エージェントビルダー画面下部のアクショングループにある「追加」ボタンをクリックしましょう。

アクショングループを以下のとおり、3つ作成します。
アクショングループ(1つ目)
- アクショングループ名: search-web
- 説明:
与えられたクエリーでWeb検索を行い、結果を返します。 - Action group function 1
- Name: search-web
- 説明:
与えられたクエリーでWeb検索を行い、結果を返します。 - Parameters: 以下のとおり
| Name | Description | Type | Required |
|---|---|---|---|
| query | Web検索用のクエリー | string | True |
アクショングループ(2つ目)
- アクショングループ名: create-slides
- 説明:
与えられたトピックについて、Googleスライドで日本語の解説資料を作成します。 - Action group function 1
- Name: create-slides
- 説明:
与えられたトピックについて、Googleスライドで日本語の解説資料を作成します。 - Parameters: 以下のとおり
| Name | Description | Type | Required |
|---|---|---|---|
| topic | スライドのメイントピック | string | True |
| content | スライドに含める内容 | string | True |
アクショングループ(3つ目)
- アクショングループ名: send-email
- 説明:
作成されたGoogleスライドのURLをメールで送信します。 - Action group function 1
- Name: send-email
- 説明:
作成されたGoogleスライドのURLをメールで送信します。 - Parameters: 以下のとおり
| Name | Description | Type | Required |
|---|---|---|---|
| presentation_url | GoogleスライドのURL | string | True |
3つのアクショングループを作成すると、エージェントビルダーで以下のように表示されます。
4. Lambdaレイヤー作成
各アクショングループから実行されるLambda関数を作成する前に、Lambdaが必要とするPythonの外部ライブラリを「レイヤー」として事前作成しておきます。
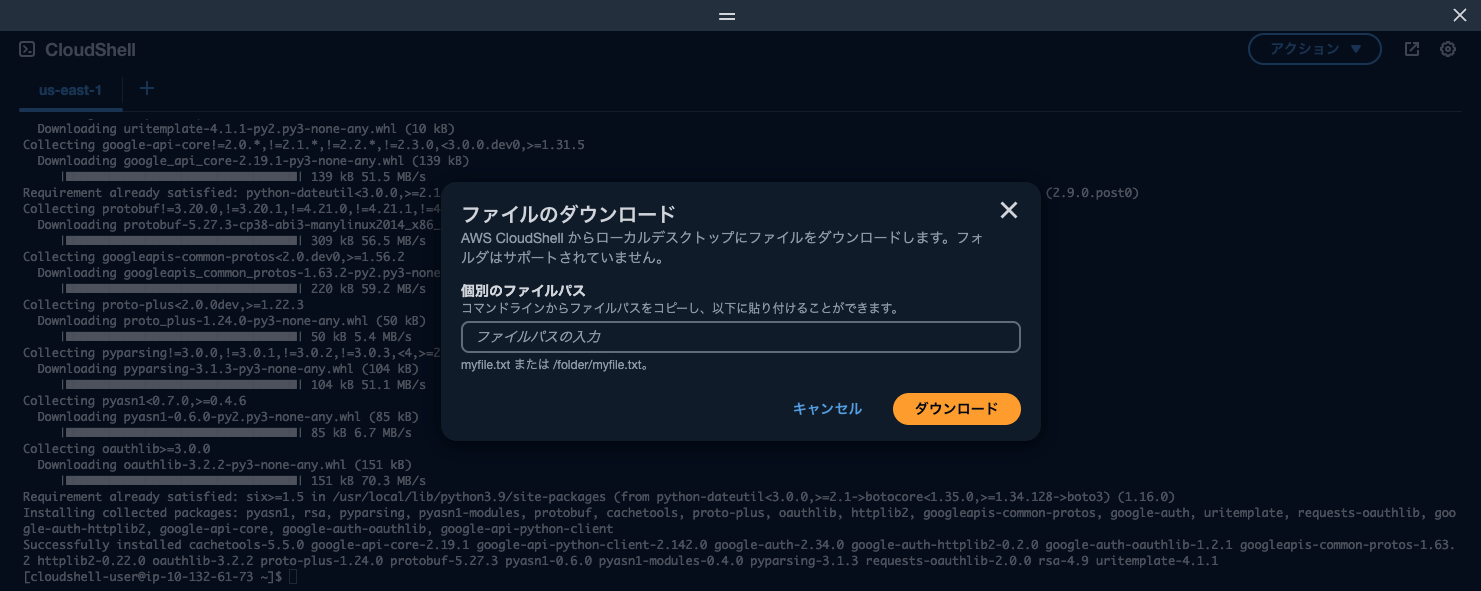
最初にマネコン右上のアイコンより、CloudShellを起動します。

以下コマンドを実行します。
# レイヤー用のディレクトリを作成
mkdir python
# 作成したディレクトリに、必要なライブラリをインストール
pip install -t python boto3 duckduckgo_search google-auth google-auth-oauthlib google-auth-httplib2 google-api-python-client
# インストールしたライブラリをZIP圧縮
zip -r layer.zip python
CloudShell右上の「アクション > ファイルのダウンロード」をクリックし、ファイルパスとして layer.zip を入力して、作業PCのローカルにZIPファイルをダウンロードしておきます。
この後、CloudShellのウィンドウは閉じてしまっても大丈夫です。
5. SNS設定
Lambdaからメールを送信するために、Amazon SNSを事前に設定します。
SNSコンソールのトップより、bedrock-agent という名前のトピックを作成します。他はデフォルト設定のままで大丈夫です。

トピックが作成されたら、このトピックに届いたメッセージを配信する「サブスクリプション」を作成します。

- プロトコル: Eメール
- エンドポイント: 自分のメールアドレス
上記を設定したら、設定したメールアドレス宛てに確認メールが届くので「Confirm subscription」リンクをクリックしましょう。これで通知が配信されるようになります。
6. Lambda設定
先ほどBedrockエージェントのアクショングループを作成した時点で、Lambda関数が自動で作成されているのですが、中身のコードがほぼ空っぽなので編集します。
AWS Lambdaのコンソールに移動して「関数」を開き、バージニア北部リージョンに3つの関数が作成されていることを確認します。

Lambdaレイヤーの設定
まずは「レイヤー > レイヤーの作成」より、先ほど作成したZIPでLambdaレイヤーを作成します。
- 名前: bedrock-agent
- .zipファイルをアップロード: 先ほどダウンロードしたZIPファイルを指定
- 互換性のあるアーキテクチャ: x86_64
- 互換性のあるランタイム: Python 3.9
他はそのままで「作成」をクリックします。20秒ほどかかります。

Lambda関数の設定
その後、3つの関数をそれぞれ設定していきます。
search-web 関数
- コードソース:以下で上書きし、「Deploy」をクリックします。
# Python外部モジュールのインポート
import json
from duckduckgo_search import DDGS
# メインのLambda関数
def lambda_handler(event, context):
# イベントパラメータから検索クエリを取得
query = next(
(item["value"] for item in event["parameters"] if item["name"] == "query"), ""
)
# DuckDuckGoを使用して検索を実行
results = list(
DDGS().text(
keywords=query,
region="jp-jp", # 日本向けの検索結果を取得
safesearch="off", # セーフサーチをオフに設定
timelimit=None, # 時間制限なし
max_results=10, # 最大10件の結果を取得
)
)
# 検索結果をフォーマット
summary = "\n\n".join(
[f"タイトル: {result['title']}\n要約: {result['body']}" for result in results]
)
# レスポンスの作成と返却
return {
"messageVersion": "1.0",
"response": {
"actionGroup": event["actionGroup"],
"function": event["function"],
"functionResponse": {
"responseBody": {
"TEXT": {
"body": json.dumps({"summary": summary}, ensure_ascii=False)
}
}
},
},
}
- ランタイム設定:「編集」をクリック
- ランタイム: Python 3.9
- レイヤー:「レイヤーの追加」をクリック
- カスタムレイヤー: bedrock-agent
- バージョン: 1
create-slides 関数
- コードソース:以下で上書きし、「Deploy」をクリックします。
# Pyhton外部モジュールのインポート
import json, os, uuid
from google.oauth2 import service_account
from googleapiclient.discovery import build
def lambda_handler(event, context):
# イベントパラメータからトピックとコンテンツを取得
topic = next(
(item["value"] for item in event["parameters"] if item["name"] == "topic"), ""
)
content = next(
(item["value"] for item in event["parameters"] if item["name"] == "content"), ""
)
# 環境変数からGoogle認証情報を取得し、認証オブジェクトを作成
creds_json = json.loads(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
creds = service_account.Credentials.from_service_account_info(creds_json)
# Google Slides APIクライアントの作成
service = build("slides", "v1", credentials=creds)
# プレゼンテーションの作成
presentation = service.presentations().create(body={"title": topic}).execute()
presentation_id = presentation.get("presentationId")
# スライドの追加
create_slides(service, presentation_id, content)
# Google Drive APIクライアントの作成
drive_service = build("drive", "v3", credentials=creds)
# スライドの共有設定(誰でも閲覧可能に設定)
permission = {"type": "anyone", "role": "reader", "allowFileDiscovery": False}
drive_service.permissions().create(
fileId=presentation_id, body=permission, fields="id"
).execute()
# プレゼンテーションの閲覧用URLを取得
file = (
drive_service.files()
.get(fileId=presentation_id, fields="webViewLink")
.execute()
)
web_view_link = file.get("webViewLink")
# レスポンスの作成と返却
return {
"messageVersion": "1.0",
"response": {
"actionGroup": event.get("actionGroup", "default"),
"function": event["function"],
"functionResponse": {
"responseBody": {
"TEXT": {
"body": json.dumps(
{
"message": "Presentation created and shared successfully",
"presentationUrl": web_view_link,
}
)
}
}
},
},
}
def create_slides(service, presentation_id, content):
slides = []
# コンテンツを各スライドに分割
slide_contents = content.split("\n\n")
# 最初のスライド(タイトルスライド)を削除
delete_requests = [{'deleteObject': {'objectId': 'p'}}]
service.presentations().batchUpdate(
presentationId=presentation_id, body={'requests': delete_requests}).execute()
for index, slide_content in enumerate(slide_contents):
lines = slide_content.strip().split("\n")
title = lines[0].replace("スライド", "").strip(":")
body = "\n".join(lines[1:])
# 各要素に一意のIDを割り当て
object_id = f"slide_{uuid.uuid4().hex[:8]}"
title_id = f"title_{uuid.uuid4().hex[:8]}"
body_id = f"body_{uuid.uuid4().hex[:8]}"
# スライドの作成とコンテンツの挿入リクエストを準備
requests = [
{
"createSlide": {
"objectId": object_id,
"insertionIndex": str(index),
"slideLayoutReference": {"predefinedLayout": "TITLE_AND_BODY"},
"placeholderIdMappings": [
{"layoutPlaceholder": {"type": "TITLE"}, "objectId": title_id},
{"layoutPlaceholder": {"type": "BODY"}, "objectId": body_id},
],
}
},
{"insertText": {"objectId": title_id, "insertionIndex": 0, "text": title}},
{"insertText": {"objectId": body_id, "insertionIndex": 0, "text": body}},
]
# バッチ更新の実行
response = (
service.presentations()
.batchUpdate(presentationId=presentation_id, body={"requests": requests})
.execute()
)
slides.append(object_id)
return slides
- ランタイム設定:「編集」をクリック
- ランタイム: Python 3.9
- レイヤー:「レイヤーの追加」をクリック
- カスタムレイヤー: bedrock-agent
- バージョン: 1
その後、「設定」タブから以下を設定します。
- 一般設定:「編集」をクリック
- タイムアウト: 0分30秒
- 環境変数:「編集 > 環境変数の追加」をクリック
- キー:
GOOGLE_APPLICATION_CREDENTIALS - 値: 冒頭でダウンロードしたGoogleのJSONファイルの中身をそのまま貼り付ける
- キー:
send-email 関数
- コードソース:以下で上書きし、「Deploy」をクリックします。
# Pyhton外部モジュールのインポート
import json, boto3, os
# SNSトピックARNを環境変数から取得
SNS_TOPIC_ARN = os.environ.get('SNS_TOPIC_ARN')
def lambda_handler(event, context):
# パラメータからURLを取得
presentation_url = event.get('parameters', [{}])[0].get('value')
# SNSクライアントの作成
sns = boto3.client('sns')
# メッセージの作成
message = f"Bedrockエージェントがスライドを作成しました。以下のURLからアクセスできます:\n{presentation_url}"
# SNSメッセージの発行
sns.publish(
TopicArn=SNS_TOPIC_ARN,
Message=message,
Subject="スライド作成通知"
)
# Bedrock Agentが期待する形式で応答を返す
return {
'messageVersion': '1.0',
'response': {
'actionGroup': event.get('actionGroup', 'send-email'),
'function': event.get('function', 'send-email'),
'functionResponse': {
'responseBody': {
'TEXT': {
'body': json.dumps({
'message': 'Email sent successfully',
'presentationUrl': presentation_url
})
}
}
}
}
}
その後「設定」タブから以下を設定します。
- 環境変数:「編集」をクリック
- キー:
SNS_TOPIC_ARN - 値: 先ほど作成したSNSトピックのARNを別タブで確認し、コピペする
- キー:
- アクセス権限:「ロール名」をクリック

IAMロールの編集画面に飛ぶので、「許可を追加 > ポリシーをアタッチ」をクリックします。
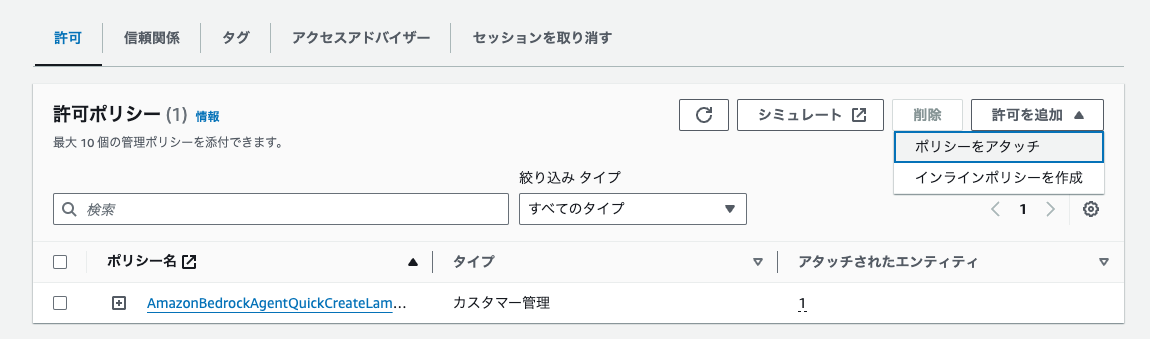
AmazonSNSFullAccess にチェックを入れ、「許可を追加」をクリックします。

7. エージェント動作確認
ここまで設定できたら、エージェントがうまく動くか動作確認をしてみましょう。
Bedrockのコンソールに移動し、「エージェント」より先ほど作成したエージェント名をクリックして開きます。
右側のテスト用サイドバーにある「準備」をクリックします。

チャットボックスに ナポレオンについて資料にまとめて と送信してみましょう。
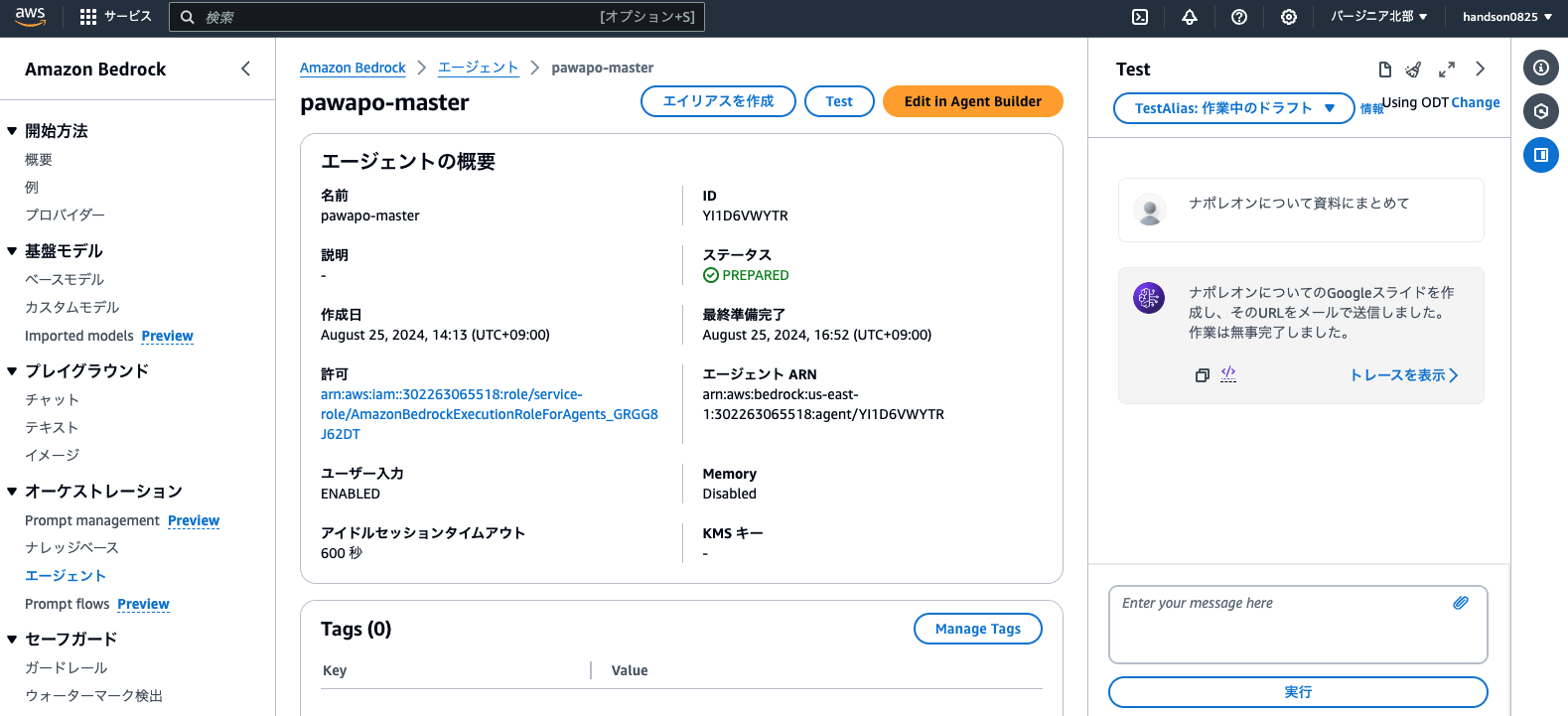
30秒〜1分ほど待つと、エージェントから返事が来ます。
確かにAmazon SNSからメールが届いています。

URLをクリックすると、Googleスライドが作成されていました!

ここまで動いたら、エージェント画面下部の「エイリアス > 作成」より、エイリアスを作成しておきます。エージェントの新バージョンをリリースする、といった作業です。
- エイリアス名: v1

トラブルシューティングのコツ
うまく動かないときは、以下を確認して原因を切り分けてみましょう。
- エージェントのトレースを確認する
- Lambdaの「モニタリング > CloudWatchログを表示」より、ログストリームを確認する
ハマりやすい点は以下です。
- アクショングループのパラメーターに設定ミスはないか?
- Lambdaレイヤーの中身は問題ないか?
- Lambdaのランタイム設定、レイヤー、環境変数、IAMロールに漏れはないか?
- SNSからの確認メールをちゃんと一度クリックしているか?
8. フロントエンド開発
エージェントが単体でうまく動いたので、これを実際にアプリケーションに組み込んでみましょう。
まずCloudShellを開いて「アクション > 削除」を実行し、一度中身を綺麗にします。
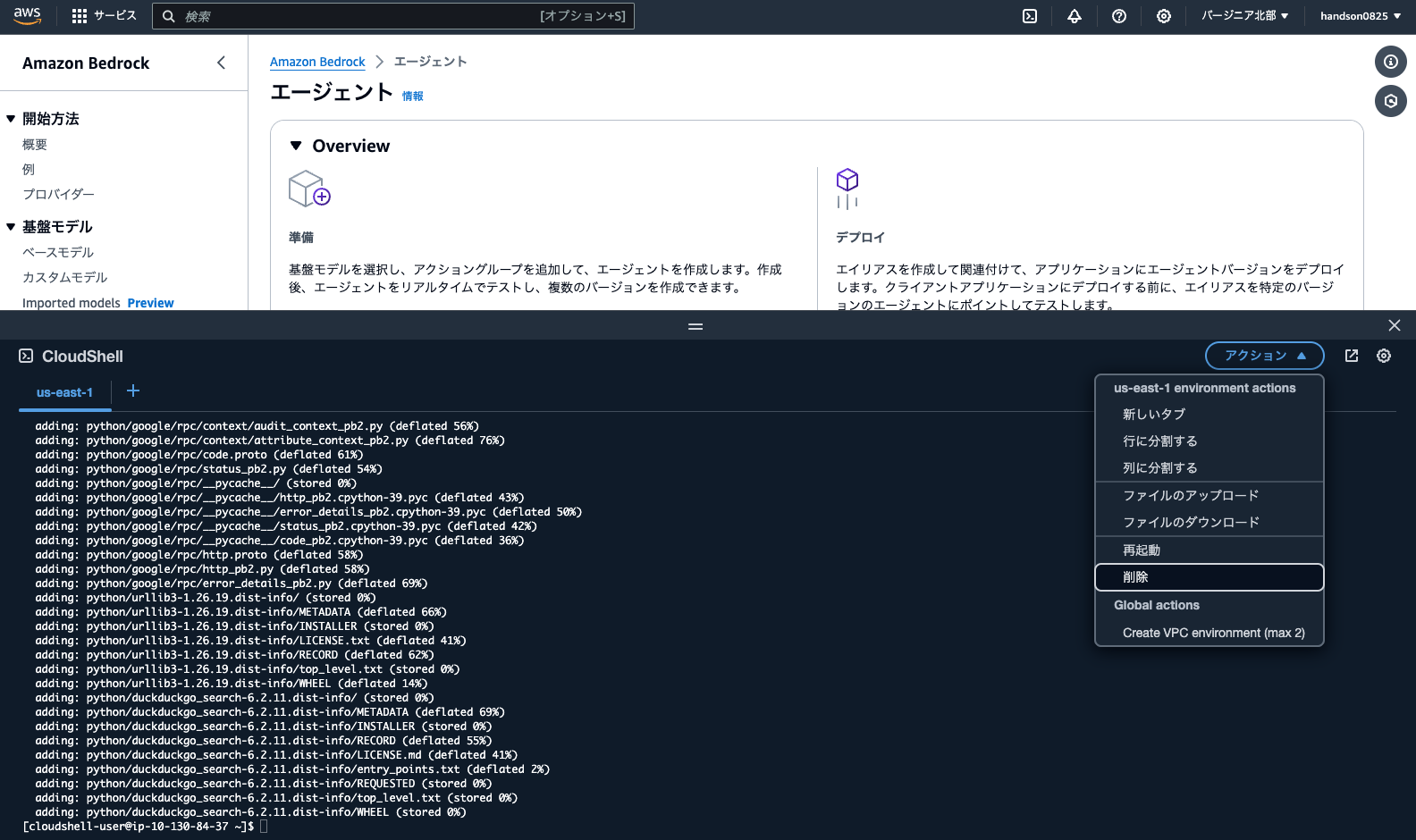
確認メッセージを入力して削除できたら、「Open us-east-1 environment」をクリックして新しいターミナルを起動します。
その後、以下のコードを frontend.py という名前で作業PCのローカルに保存してから、CloudShellの「アクション > アップロード」よりアップロードします。
Bedrockのエージェント画面より、作成したエージェントIDとエイリアスIDをコピーして、以下コードの6行目と7行目の XXXXXXXXXX 部分に入力してからアップロードしてください。
# Pyhton外部モジュールのインポート
import uuid, boto3
import streamlit as st
# エージェントIDとエイリアスIDを設定
AGENT_ID = "XXXXXXXXXX"
AGENT_ALIAS_ID = "XXXXXXXXXX"
# タイトル
st.title("スライド作ってメールで送るマン")
# Bedrockクライアントを作成
if "client" not in st.session_state:
st.session_state.client = boto3.client("bedrock-agent-runtime")
client = st.session_state.client
# セッションID
if "session_id" not in st.session_state:
st.session_state.session_id = str(uuid.uuid4())
session_id = st.session_state.session_id
# メッセージ
if "messages" not in st.session_state:
st.session_state.messages = []
messages = st.session_state.messages
# 過去のメッセージを表示
for message in messages:
with st.chat_message(message['role']):
st.markdown(message['text'])
# チャット入力欄を定義
if prompt := st.chat_input("例:KDDIの歴史をスライドにまとめてメールで送って"):
# ユーザーの入力をメッセージに追加
messages.append({"role": "human", "text": prompt})
# ユーザーの入力を画面に表示
with st.chat_message("user"):
st.markdown(prompt)
response = client.invoke_agent(
agentId=AGENT_ID,
agentAliasId=AGENT_ALIAS_ID,
sessionId=session_id,
enableTrace=True,
inputText=prompt,
)
# エージェントの回答を画面に表示
with st.chat_message("assistant"):
for event in response.get("completion"):
# エージェントの処理状況が更新されたら画面に表示
if "trace" in event:
if "orchestrationTrace" in event["trace"]["trace"]:
orchestrationTrace = event["trace"]["trace"]["orchestrationTrace"]
if "modelInvocationInput" in orchestrationTrace:
with st.expander("思考中…", expanded=False):
st.write(orchestrationTrace)
if "rationale" in orchestrationTrace:
with st.expander("次のアクションを決定しました", expanded=False):
st.write(orchestrationTrace)
if "invocationInput" in orchestrationTrace:
with st.expander("次のタスクへのインプットを生成しました", expanded=False):
st.write(orchestrationTrace)
if "observation" in orchestrationTrace:
with st.expander("タスクの結果から洞察を得ています…", expanded=False):
st.write(orchestrationTrace)
# エージェントの回答が出力されたら画面に表示
if "chunk" in event:
chunk = event["chunk"]
answer = chunk["bytes"].decode()
st.write(answer)
messages.append({"role": "assistant", "text": answer})
その後、以下のコマンドを実行します。
# Pythonの外部ライブラリをインストール
pip install boto3 streamlit
# Streamlitアプリを起動
streamlit run frontend.py
Streamlitのアクセス用URLが表示されたら、うまく起動しています。

その後、CloudShell上部の「+」をクリックして、2つ目の「us-east-1」ターミナルを起動して以下を実行します。
# PinggyにSSH接続し、インターネットからアクセス可能なURLを生成する
ssh -p 443 -R0:localhost:8501 a.pinggy.io
確認メッセージが出力されたら yes と入力してEnterを押すと、Pinggyという外部サービスを通じてこのアプリにアクセス可能なURLが発行されます。下側のHTTPSの方のURLに、ブラウザの別タブからアクセスしてみましょう。

「Enter site」をクリックすると、先ほどアップロードしたPythonアプリにアクセスできます。Streamlitというフレームワークを使って、フロントエンドを表示しています。
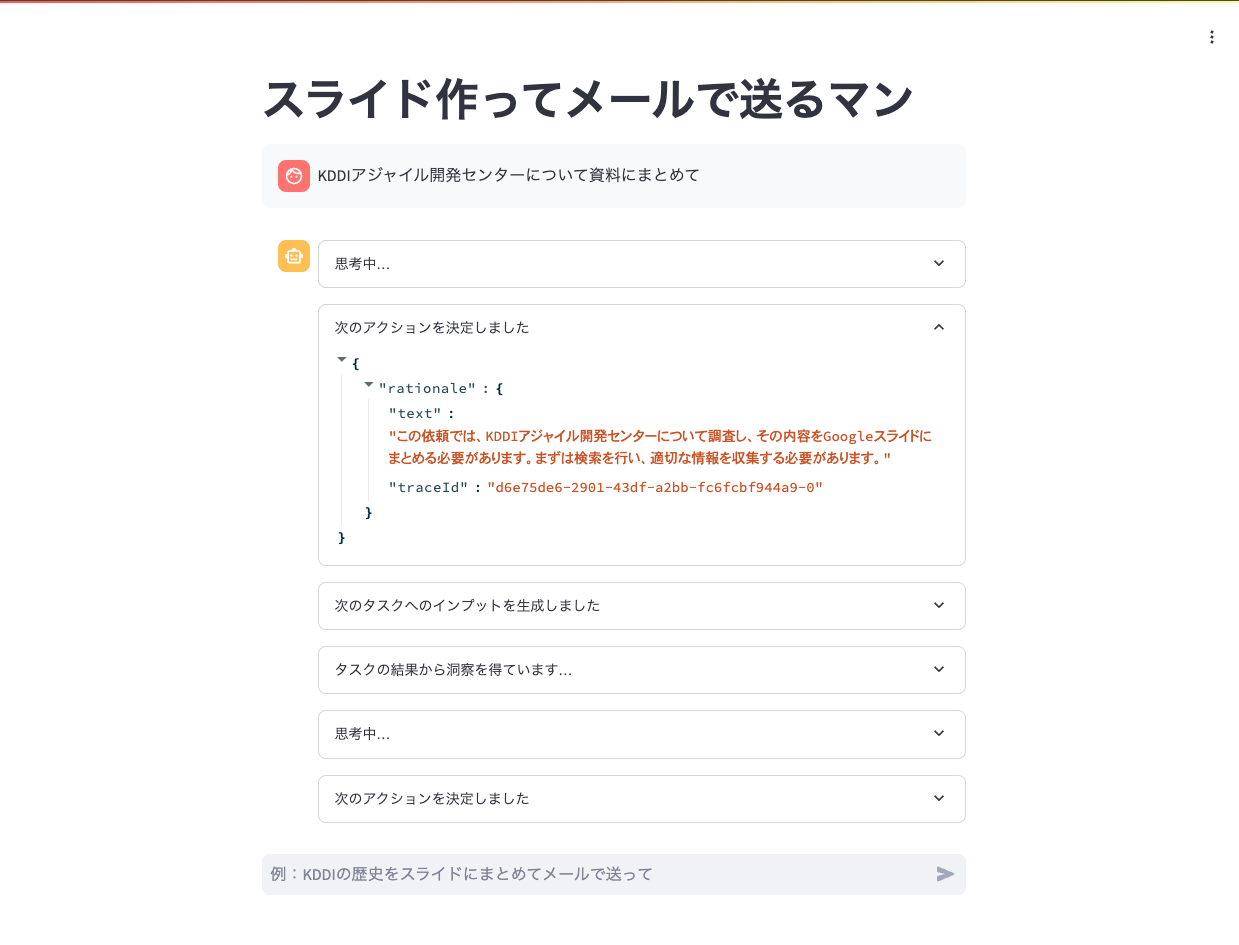
実際にこのアプリを使ってみましょう。
エージェントのトレース情報が、Streamlitのフロントエンドにリアルタイムで出力されるようになっています。
CloudShell上のPythonアプリにアクセスするため、今回はPinggyという外部サービスを利用し、一時的にインターネットからアクセス可能なURLを生成しています。セキュリティ上、意図せぬ第三者にURLを知られないよう注意ください。
また、このURLを同僚に共有すると、アプリを触って試してもらうこともできます。
ちなみにCloudShellは、20〜30分で自動停止してしまうため、StreamlitとPinggyの再実行が必要となります。また、Pinggyは無料版の制約としてURLにアクセス可能な時間が60分間となります。
お片付け
今回はサーバーレス構成のため、環境を放置してもほぼ課金は発生しませんが、セキュリティ事故を防ぐために以下の対応をおすすめします。
- AWSアカウントの閉鎖(閉鎖しない場合、ルートユーザーへのMFA設定)
- Google Cloud サービスアカウントの削除
次のステップ
Bedrockにはナレッジベースという、RAGを簡単に構築できる機能もあります。これも実施して、今回のエージェントから呼んでみるとさらに面白くなります!
また、今回作ったアプリをコンテナにデプロイして、Webアプリとして公開してみたい方は以下を活用ください。
宣伝
先日、凄腕Bedrockerの @hedgehog051 @moritalous と入門書を出版しました。
もしBedrockに興味を持たれた方は、お手に取ってみてくださいますと幸いです!
今回参考にさせていただいた森田さんの記事