2023/9/4 追記
本記事の内容をプレゼンする機会がありましたので資料掲載しておきます。
また先月、本件関連機能のアップデートが発表され、Global Databaseの障害時フェイルオーバー操作がマネージド化されました。これはありがたいですね!
はじめに
AWSの提供するクラウドネイティブな高性能DB「Amazon Aurora」には、グローバルDBという「リージョンまたぎでDBを同期してくれる機能」がある。
これはBCP構成において非常に有用で、例えば「メインの東京リージョンで大災害が発生した際、サブの大阪リージョンにフェイルオーバーする」といったことが可能。
グローバルDBだと何がうれしいの?
データベースの異サイト復旧を検討する際、一番面倒なのがデータの同期。
日々更新されるメインサイトのDBをサブDBにも常時複製しておかないと、有事の際にフェイルオーバーしても必要なデータが存在しなかったり、鮮度が古い(最新のデータが欠けている)とRPO要件を満たすことができない。
グローバルDBの便利なところは、この「リージョン間のDB同期」をAWSがマネージドで勝手にやってくれることである。
実際にやってみた
以下を実際にAWS上でハンズオンしてみる。
- メインサイト(東京リージョン)にAuroraクラスターを構築
- DRサイト(大阪リージョン)にレプリカを追加
- DR発動!大阪リージョンをプライマリへ昇格
- 東京リージョンにレプリカを再構築
- 災害復旧。東京リージョンを再びプライマリへ昇格
1. メインサイト(東京リージョン)にAuroraクラスターを構築
RDSコンソールを開き「データベースの作成」を実行。
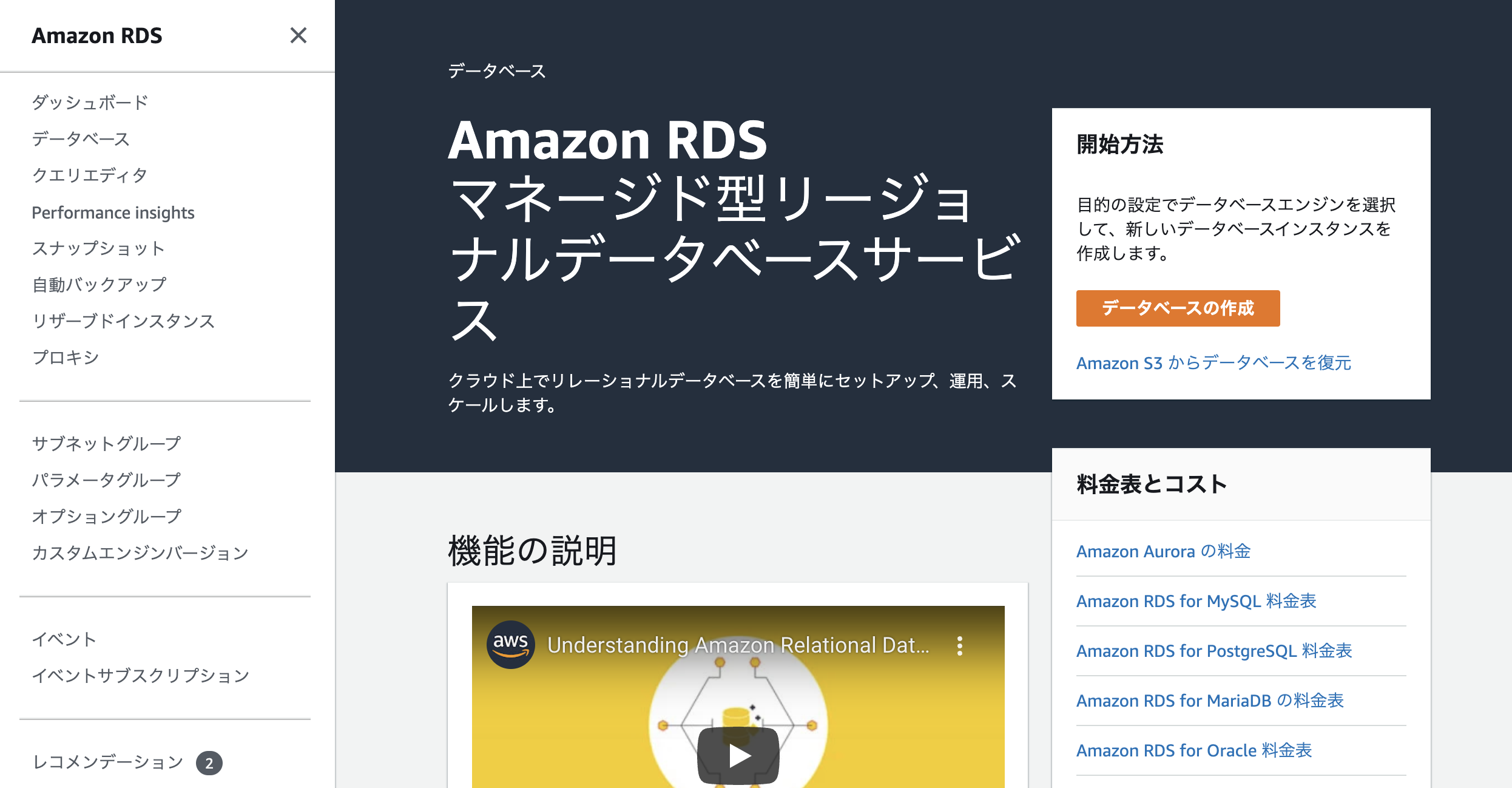
標準構成でクラスターを作成。「本番稼働用」テンプレートを利用する。
今回はPostgreSQL互換エンジンを選択。
クラスター作成開始したら、ステータスが「利用可能」になるまで待つ。
2. DRサイト(大阪リージョン)にレプリカを追加
Auroraクラスターの作成が完全に完了したら、アクション項目で「AWSリージョンを追加」がアクティブになっているのでクリック。
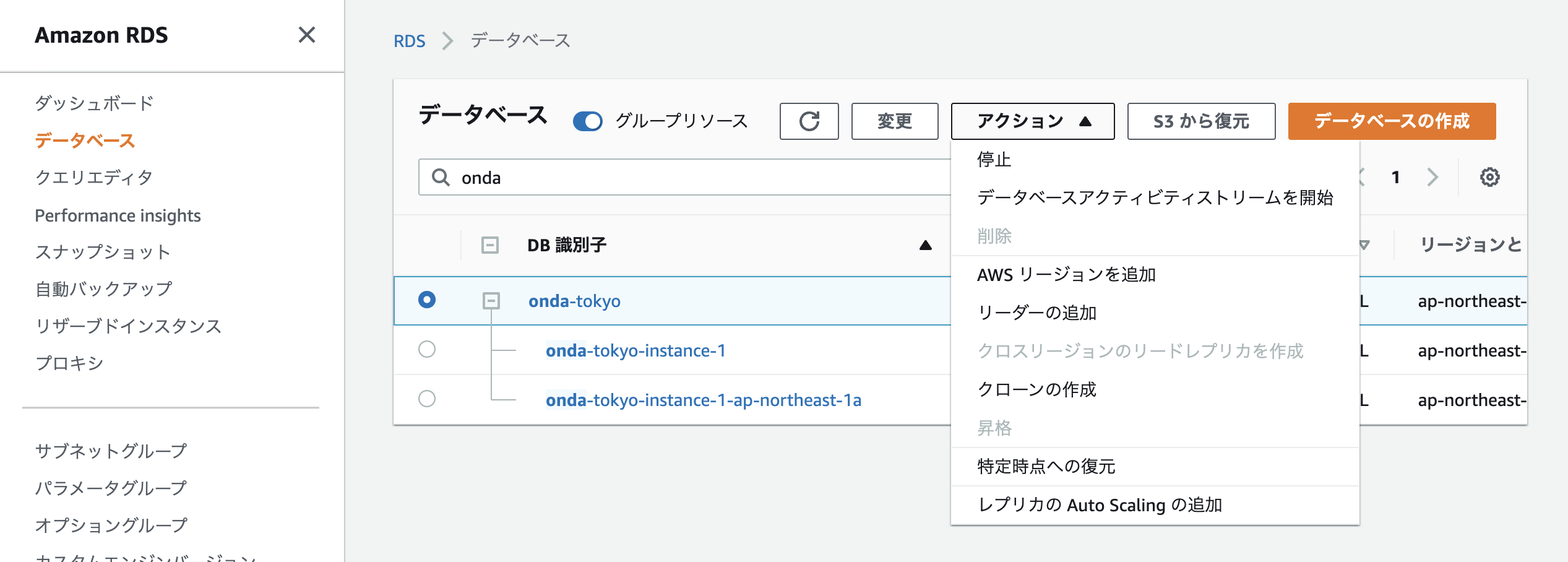
するとグローバルDBの設定ウィザードが起動する。
「グローバルDB識別子」は、同期対象の各リージョンDBのセット全体につく一つの名前となる。
今回セカンダリリージョンには大阪を指定。またインタンスの「マルチAZ構成」も有効にしてみる。
グローバルDBの作成が完了すると、マネコン上では以下のようにいろいろ増えている。
青色が元からあったクラスターで赤色が増えた部分。
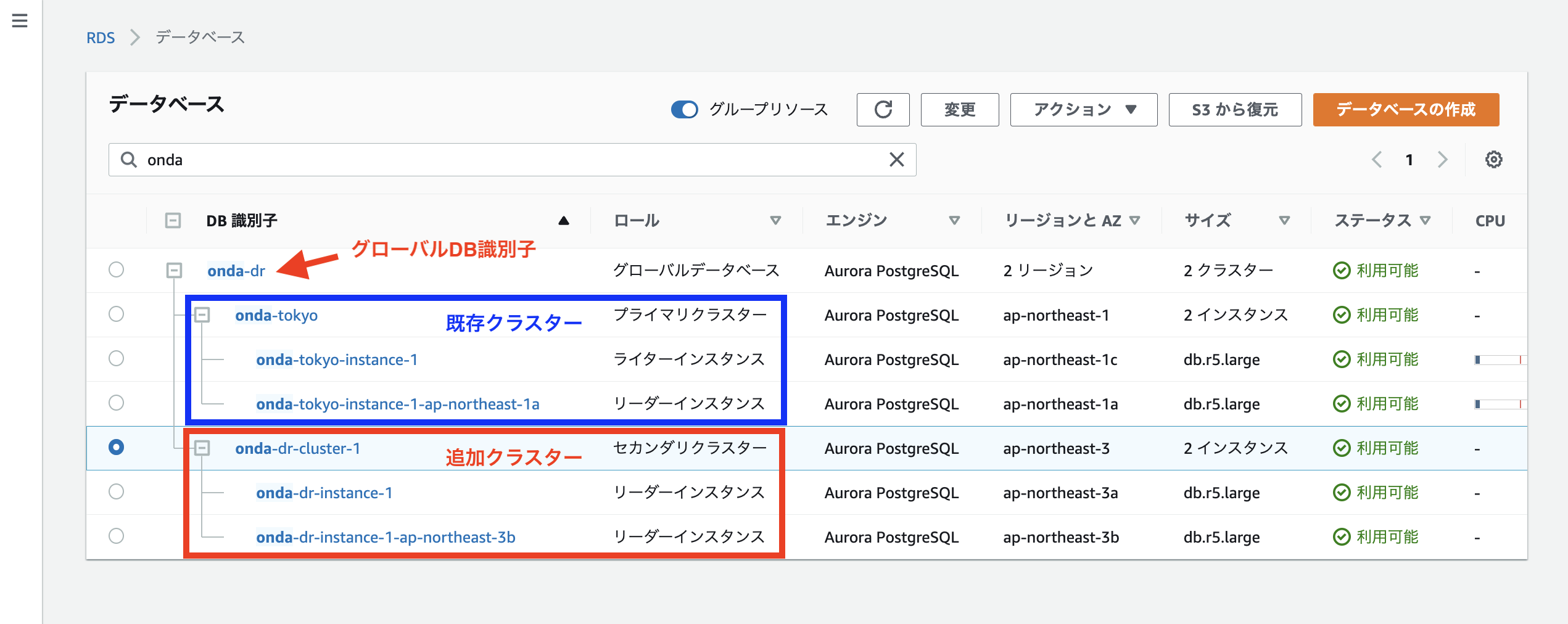
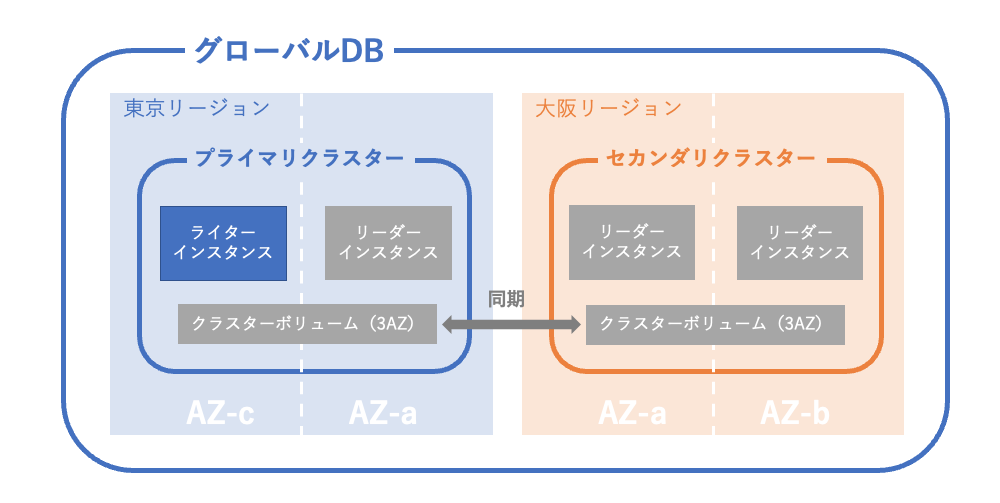
つまり今、こういう状態である。これで災害発生前、平常時の構成が完成。
3. DR発動!大阪リージョンをプライマリへ昇格
ここで東京リージョンで大障害が発生したと仮定し、以下の順でDRオペレーションを実施する。
- 大阪クラスターを一度、グローバルDBから脱退させる
- 脱退させた大阪クラスターをプライマリとして、新たにグローバルDBを設定する
まずは大阪クラスターを「グローバルDBから削除」する。
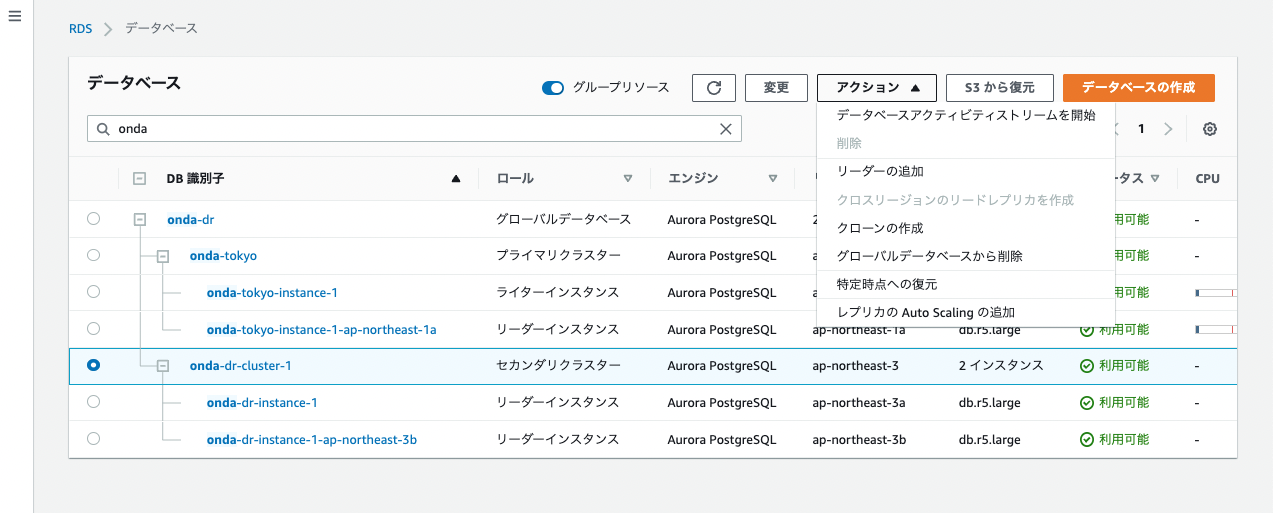
ちなみに削除時にはポップアップで「昇格しますか?」と確認される。
つまりセカンダリクラスターをグローバルDBから削除する=新たなグローバルDBのプライマリクラスターに昇格するということが改めて理解できる。
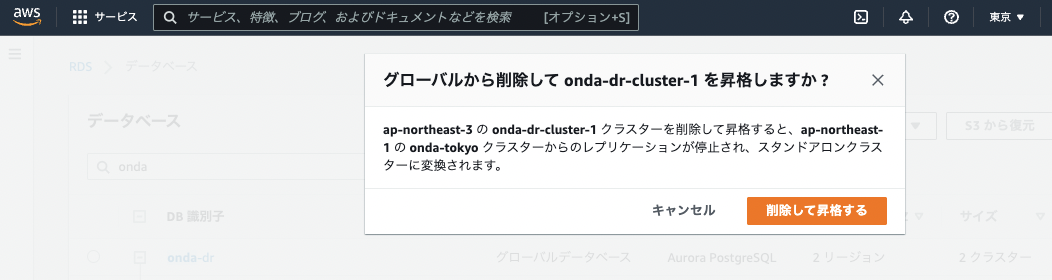
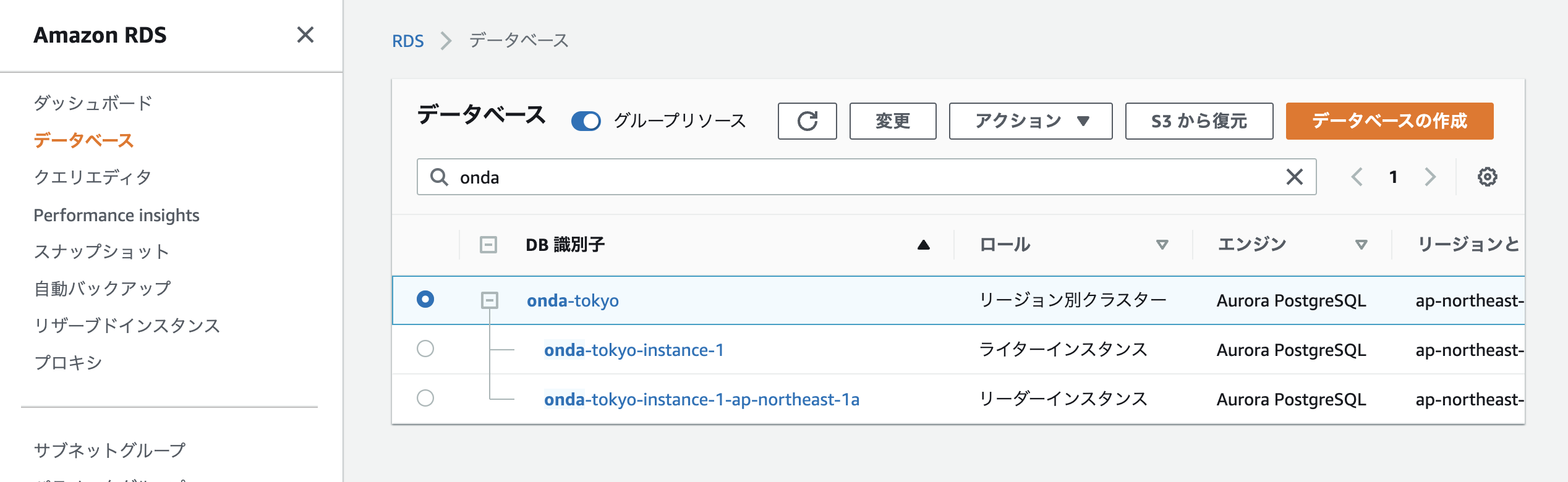
削除が完了すると、元いたグローバルDBとは別の「レプリカクラスター」として表示される。
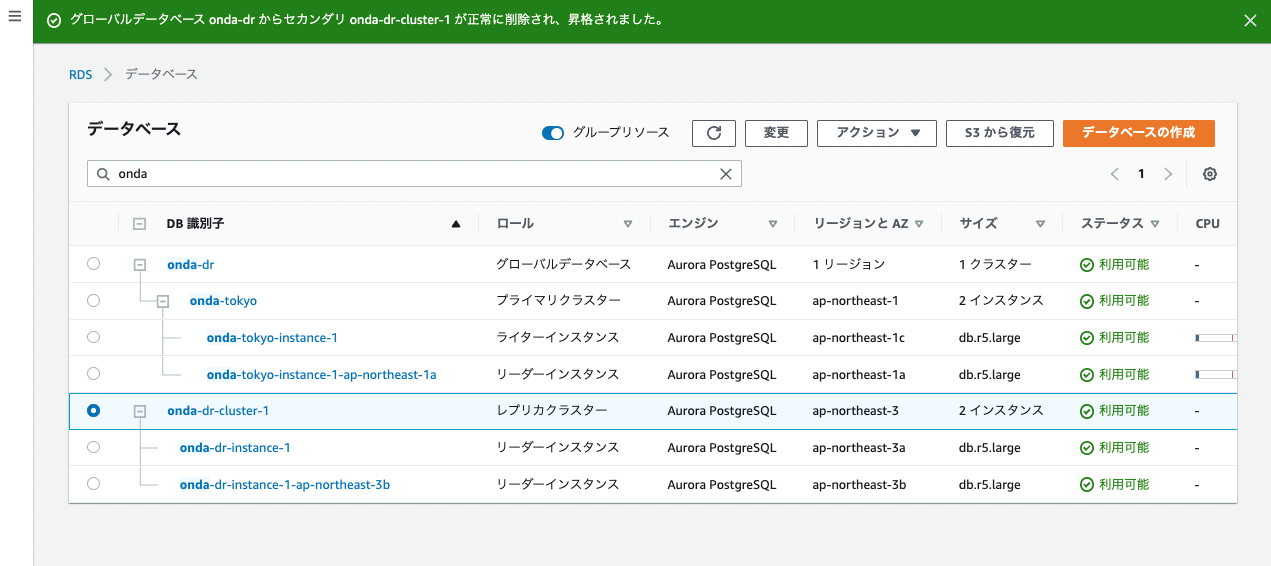
こいつはもう東京リージョンにいない亡霊のはずなので、マネコンを大阪リージョンに切り替えてみると…
レプリカではなく「リージョン別クラスター」になっていることが分かる。インスタンスも片方がライターへ昇格されている。
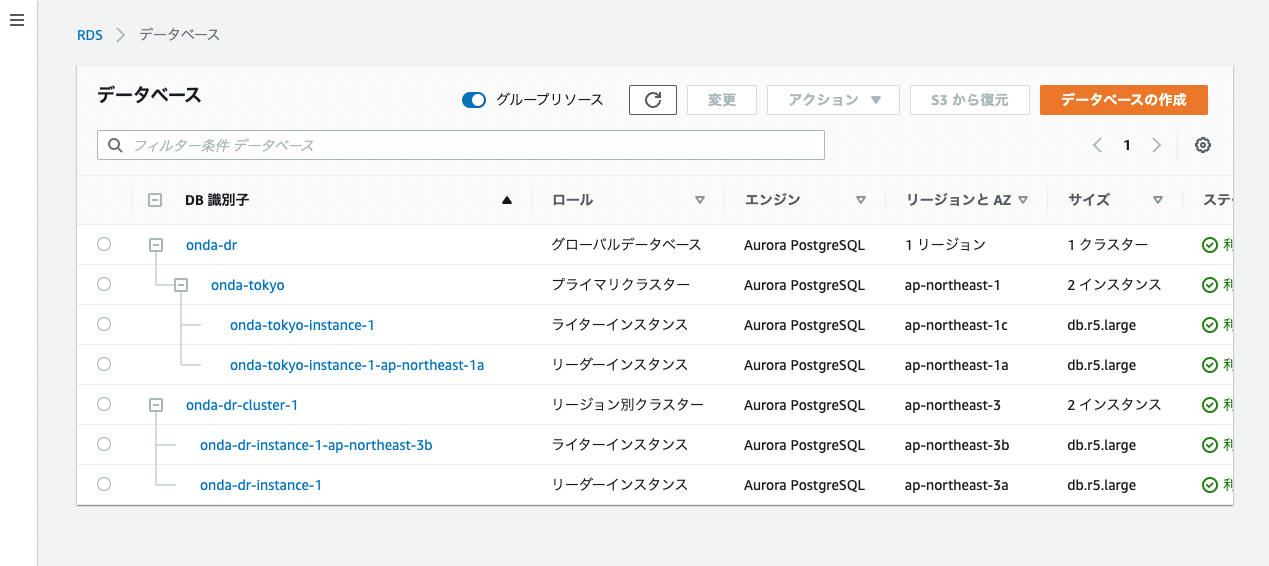
4. 東京リージョンにレプリカを再構築
被災後、無事に大阪リージョンをAuroraクラスターのメインサイトに昇格できたため、しばらくは大阪メインでAuroraを稼働させることになる。その間、マルチリージョンの可用性を維持できるよう東京リージョンに大阪のレプリカを構築しておく。
もし東京復旧後にメインサイトを戻したくなった場合、そのまま東京側のレプリカをプライマリクラスターへ昇格させることも可能となる。
まずは大阪のリージョン別クラスターをグローバルDBとして再構成する。最初に東京側からグローバルDBを構成した際と同じく「AWSリージョンを追加」する。
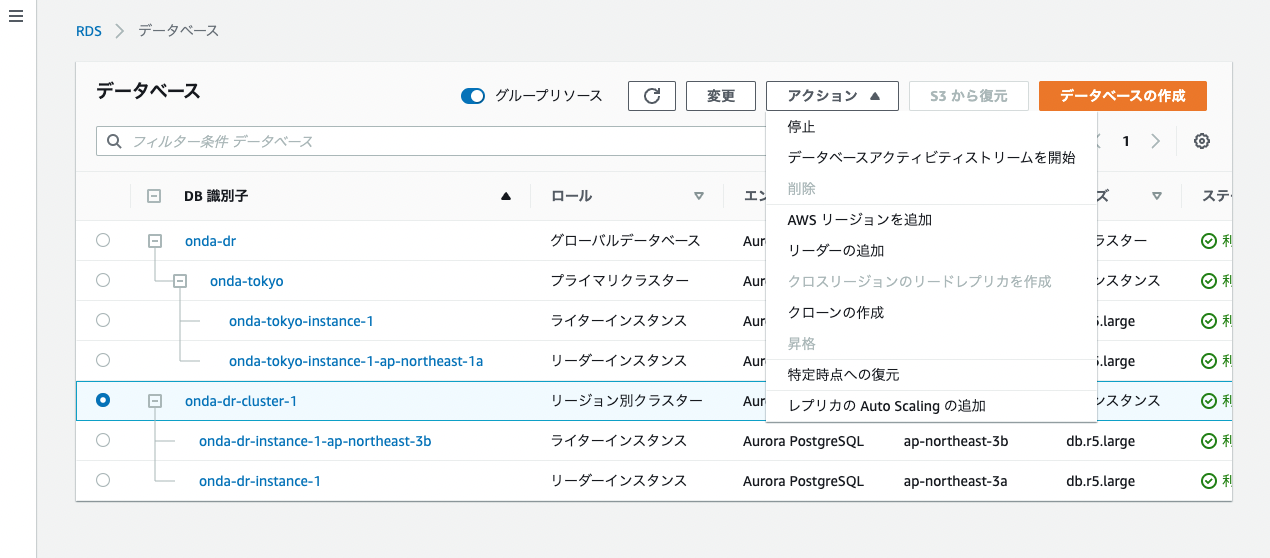
今度は東京リージョンをセカンダリにする。インスタンス構成は今回もマルチAZを選択。
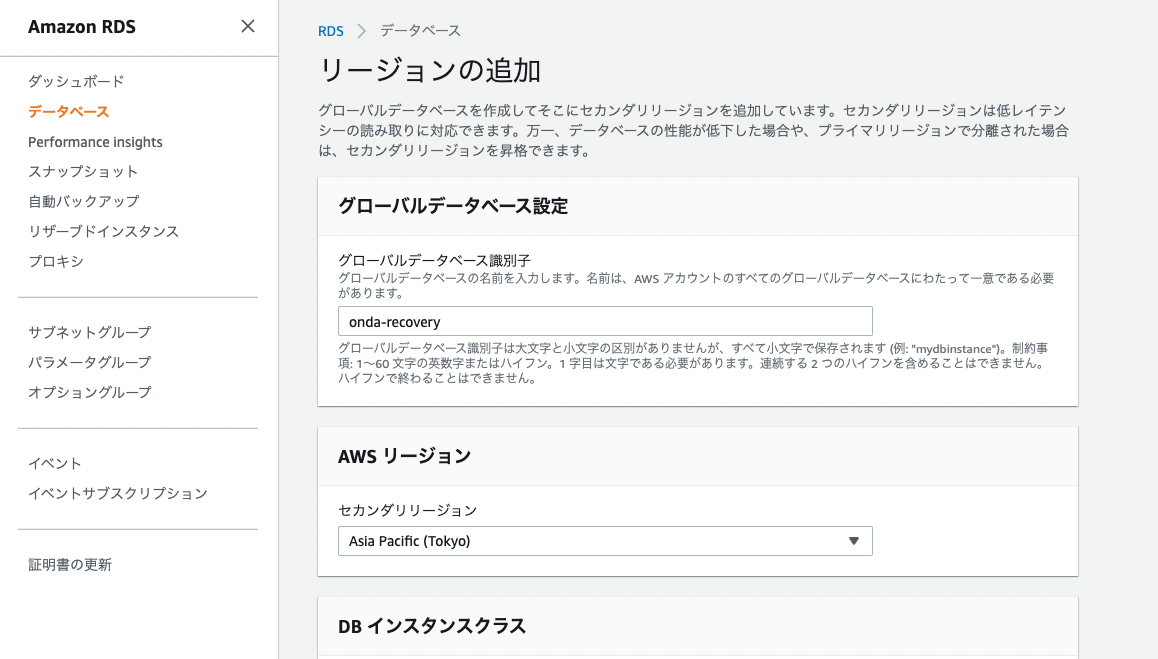
すると新規グローバルDBが構成され、東京リージョン側にセカンダリクラスターが追加される。これで大阪をメインサイトとするAuroraクラスターの完全復旧が完了。
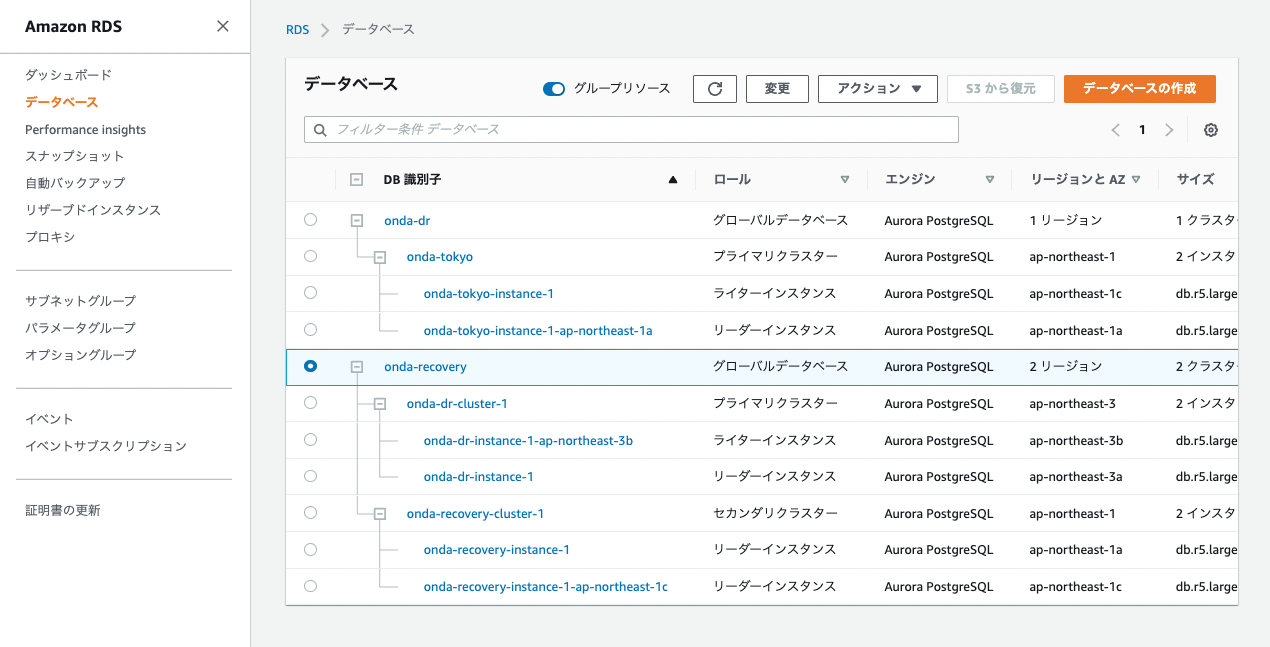
5. 災害復旧。東京リージョンを再びプライマリへ昇格
数時間後、東京リージョンの大障害も落ち着いたらしいのでAuroraのプライマリクラスターを再度東京リージョンへ戻すこととする。
このとき、DR発動時の切り替え手順とは異なる操作を行う。
グローバルDBを選択すると、アクションに「グローバルDBをフェイルオーバー」という項目が表示される。
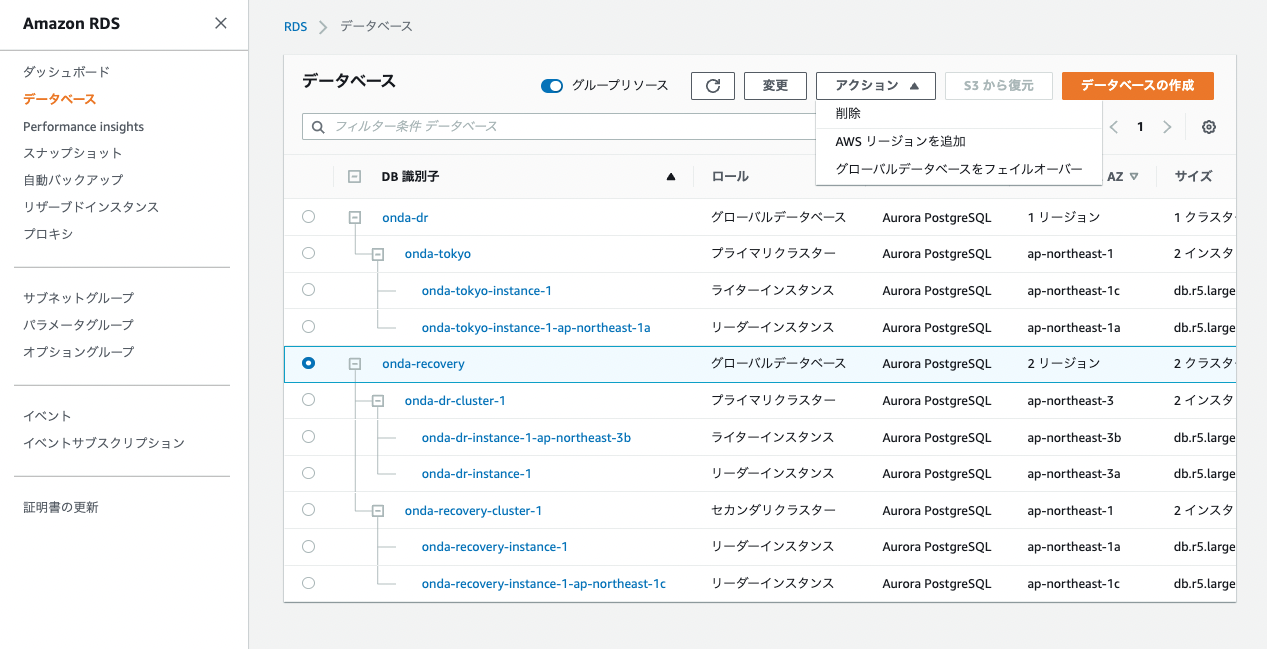
これはDR復旧時のように計画的なフェイルオーバーを実施するのに適した「マネージドフェイルオーバー」という機能。先ほどのように手動でレプリカクラスターを除隊する手順に比べて、データ損失を完全に避けられる(RPO=0)のがメリット。
ただし正常なグローバルDBを想定したコマンドのため実障害のフェイルオーバー用途には適さず、あくまで復旧後などの計画的なプライマリリージョン変更に利用する。
ポップアップにてフェイルオーバー先のセカンダリリージョンをプルダウンで選択し、実行する。
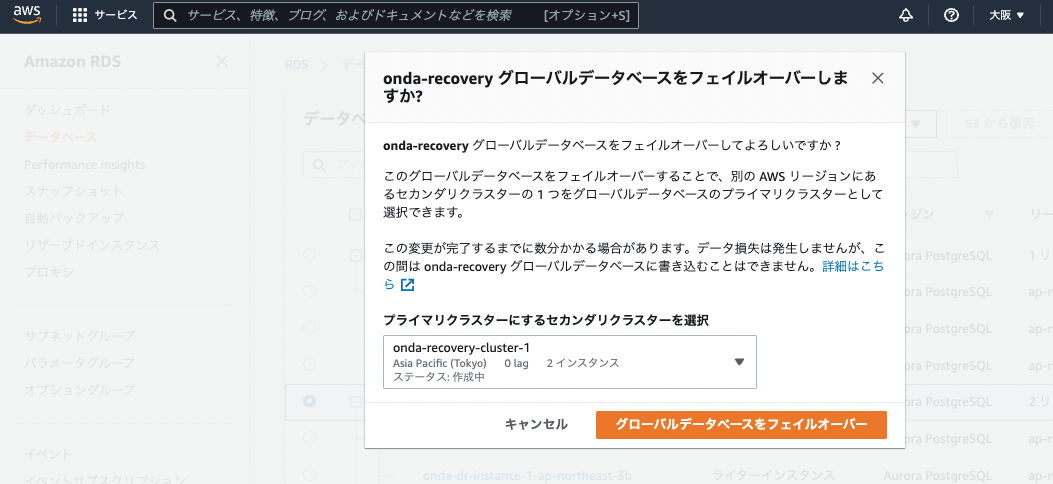
ちなみにフェイルオーバー中は両クラスターともロールが保留中となり、DB利用が不可となる。
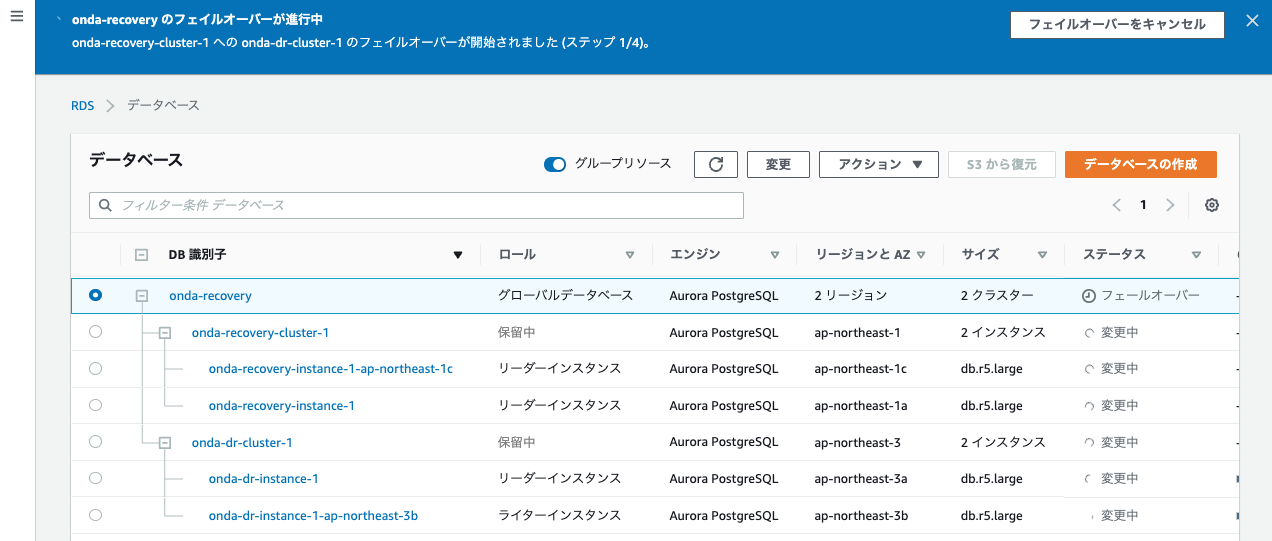
今回は2〜3分でフェイルオーバーが完了。東京側のクラスターがプライマリに昇格された。
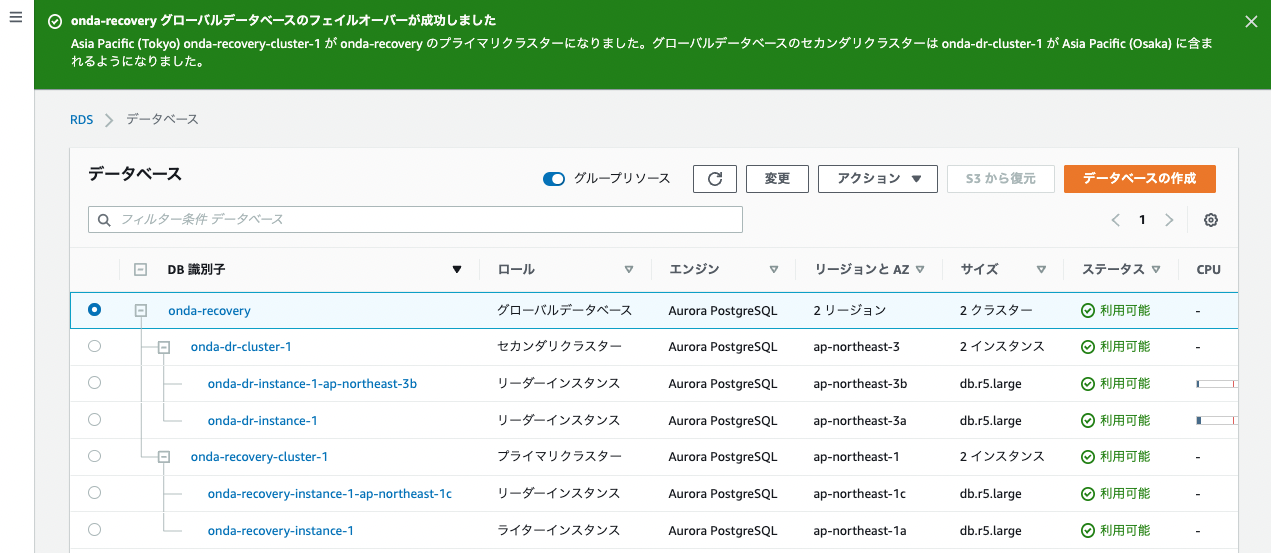
まとめ
マルチリージョン構成なんてよっぽどミッションクリティカルな現場でしか採用されないと思われがちだが、シングルリージョン構成だと例えばDirect Connectなど特定のサービスが思わぬ可用性の泣き所となってしまう可能性もある。
せっかくAWSを使ってシステムを構築するのであれば、リレーショナルDBにはぜひ高性能なAuroraを採用し、BCP構成としてグローバルDBを活用したい。
(そしてエンプラ的にはOracle互換エンジンのサポートにも期待したいところ…!AWSさん🥺)