日本時間2024/3/1(土)、こんな新機能が生えていました。
具体的な利用方法が少し分かりづらかったので解説です。
ナレッジベース for Bedrockとは?
生成AI利用時の「社内文書検索」(いわゆるRAG)機能をGUIで簡単に作成できてしまうAWSの機能です。
今回のアップデートは何が嬉しいの?
このナレッジベースが文書の検索時に「ハイブリッド検索」をサポートしたことで、ユーザーの質問に意味的に近いテキストのかたまり(チャンク)を引っ張ってくる際の精度が向上することが期待できます。
※ハイブリッド = セマンティック(意味)検索とテキスト(全文)検索の双方の結果を比べて、「いいとこ取り」をしてくれる動作と想像しています。
Hybrid Search is now generally available in Knowledge Bases for Bedrock for OpenSearch Serverless. Retrieval augmented generation (RAG) applications typically use semantic search, which relies on semantic vectors to search unstructured text. These vectors are created from machine learning models to capture contextual and linguistic meaning within the data to answer human-like questions. Hybrid search combines this semantic search with a text based search to improve the relevance of retrieved results, especially for keyword searches.
Hybrid search works by making two search queries to the semantic and text retrieval systems, and then combines the results through intelligent ranking. This increases the relevancy of results by casting a wider search net and retrieving relevant documents which may not necessarily contain the appropriate semantic structure of the document. You can enable hybrid search through the Knowledge Bases SDK or in the console. Select hybrid search as your preferred search option within Knowledge Bases, or choose the default search option where AWS will intelligently determine the best search methods to use for your data. Hybrid search is available in US East (N. Virginia) and US West (Oregon) AWS Regions. To learn more, refer to Knowledge Bases for Amazon Bedrock documentation. To get started, visit the Amazon Bedrock console.
詳細を確認してみる
ナレッジベースのドキュメントには以下の記載が追加されていました。
By default, Amazon Bedrock decides a search strategy for you. If you're using an Amazon OpenSearch Serverless vector store configured with a filterable text field, you can specify whether to use HYBRID or SEMANTIC search in the overrideSearchtype field in the retrievalConfiguration. See above for search type details.
まとめると以下です。
- ハイブリッド検索は、ナレッジベースのベクトルストアにOpenSearch Serverlessを選択した際に利用可能
- デフォルト設定だと、ハイブリッド or セマンティック検索をBedrockが(よしなに)選択してくれる
マネコンからの操作方法
AWSマネジメントコンソールからナレッジベースを作成。
作成時は変化ありませんが、テスト画面に設定ボタンが登場しています。
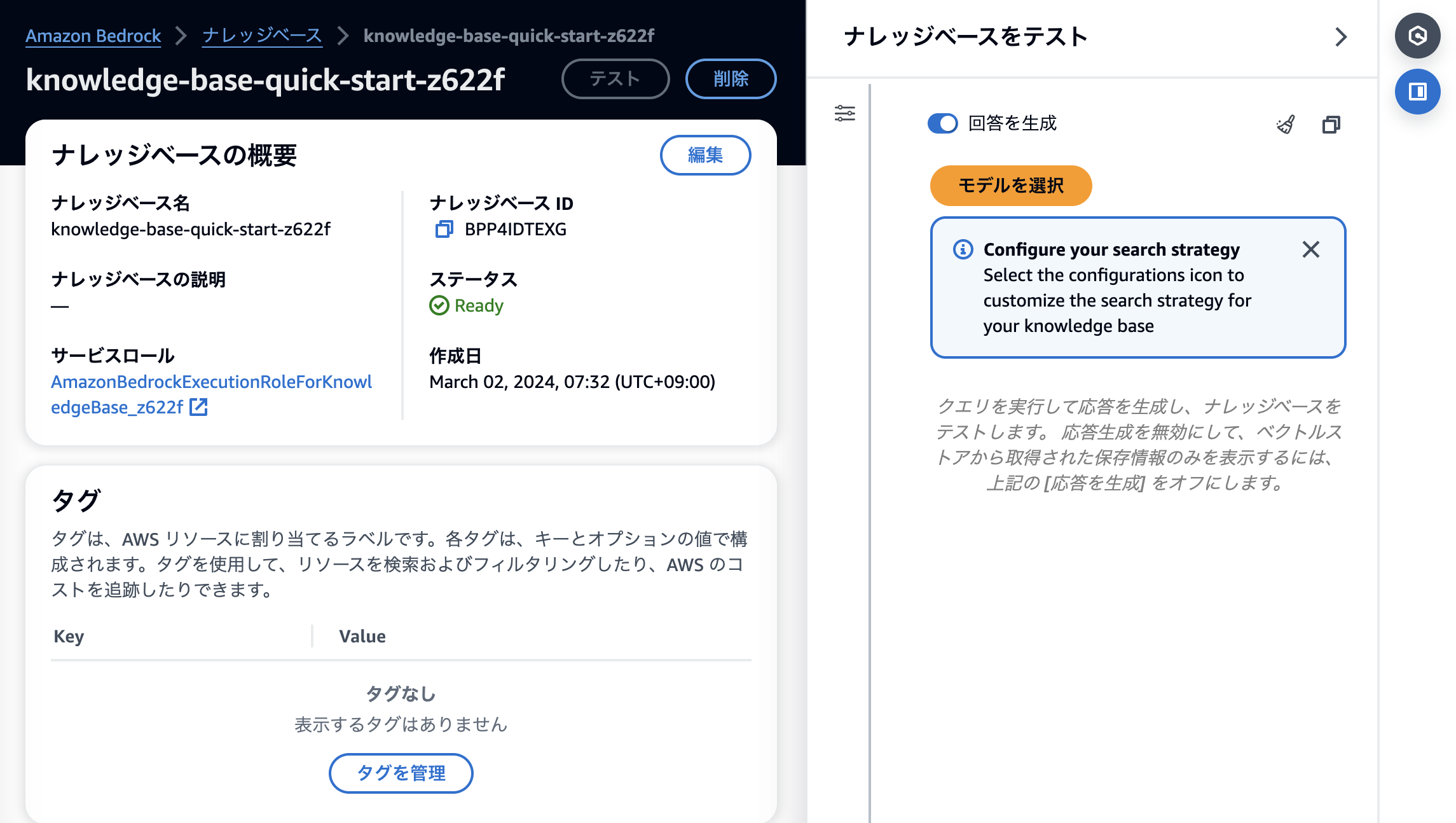
開くとこんな感じです。
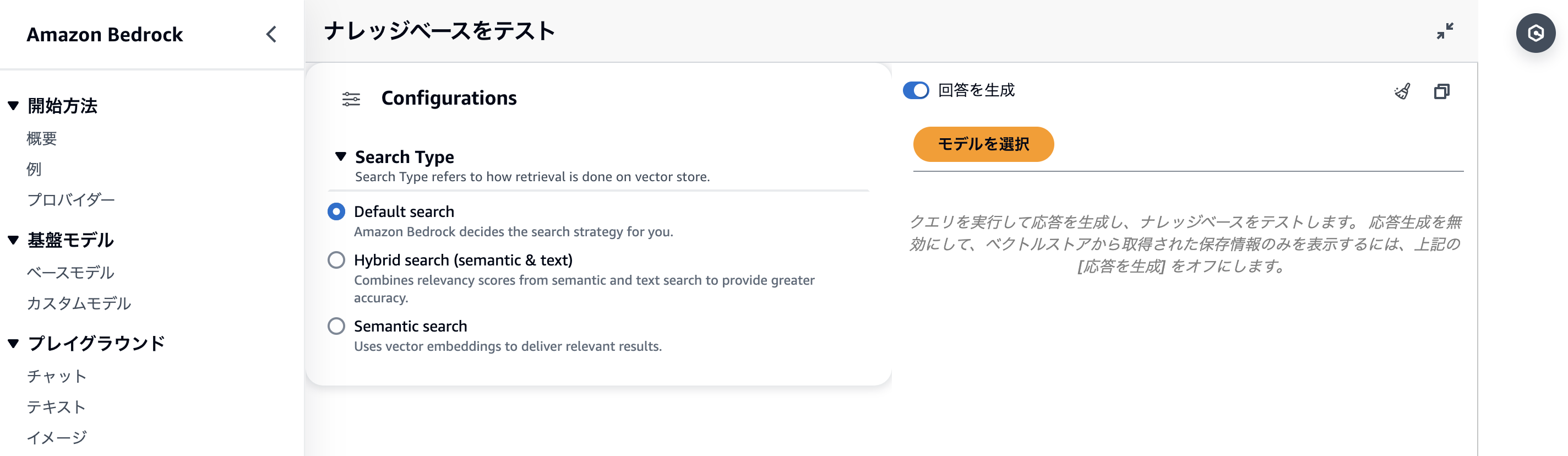
デフォルト設定の場合の回答例
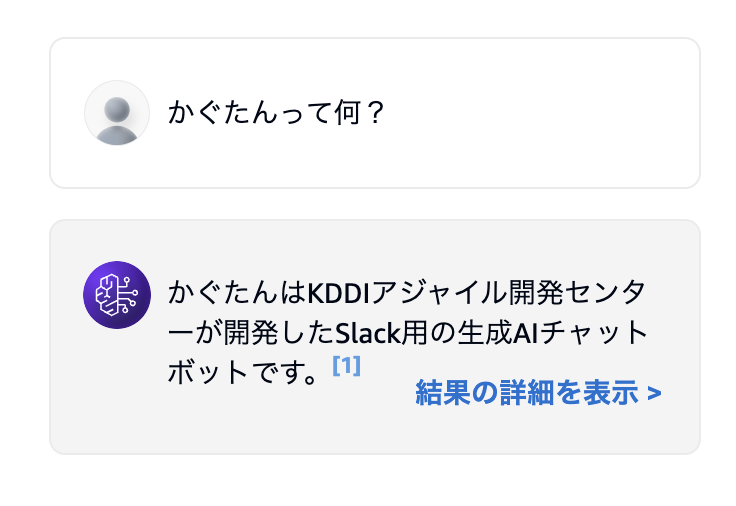
ハイブリッド検索の場合の回答例
LLMの回答は必ずしも一定ではないのですが、ハイブリッド検索により回答精度が上がっている可能性がありそうです。
APIからの利用方法
ナレッジベースを呼び出す際の「RetrieveAndGenerate」APIの overrideSearchType パラメーターで指定できます。
POST /retrieveAndGenerate HTTP/1.1
Content-type: application/json
{
"input": {
"text": "string"
},
"retrieveAndGenerateConfiguration": {
"knowledgeBaseConfiguration": {
"knowledgeBaseId": "string",
"modelArn": "string",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults": number,
"overrideSearchType": "string"
}
}
},
"type": "string"
},
"sessionConfiguration": {
"kmsKeyArn": "string"
},
"sessionId": "string"
}
設定方法は以下です。
overrideSearchType
By default, Amazon Bedrock decides a search strategy for you. If you're using an Amazon OpenSearch Serverless vector store that contains a filterable text field, you can specify whether to query the knowledge base with a HYBRID search using both vector embeddings and raw text, or SEMANTIC search using only vector embeddings. For other vector store configurations, only SEMANTIC search is available. For more information, see Test a knowledge base.Type: String
Valid Values: HYBRID | SEMANTIC
Required: No
Cloud9からAPIを呼んでみる
実際にAPIを叩いてみました。
事前にBoto3をアップデートしましょう。
pip install -U boto3
Cloud9で以下コードを実行します。
# 外部ライブラリをインポート
import streamlit as st
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_community.llms.bedrock import Bedrock
from langchain_community.retrievers.bedrock import AmazonKnowledgeBasesRetriever
# 検索手段を指定
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id="XXXXXXXXXX", #ナレッジベースIDを指定
retrieval_config={
"vectorSearchConfiguration": {
"numberOfResults": 10,
"overrideSearchType": "HYBRID"}}) #ここで指定
# プロンプトのテンプレートを定義
prompt = ChatPromptTemplate.from_template("以下のcontextに基づいて回答してください: {context} / 質問: {question}")
# LLMを指定
model = Bedrock(model_id="anthropic.claude-v2:1", model_kwargs={"max_tokens_to_sample": 1000})
# チェーンを定義(検索 → プロンプト作成 → LLM呼び出し → 結果を取得)
chain = ({"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser())
# フロントエンドを記述
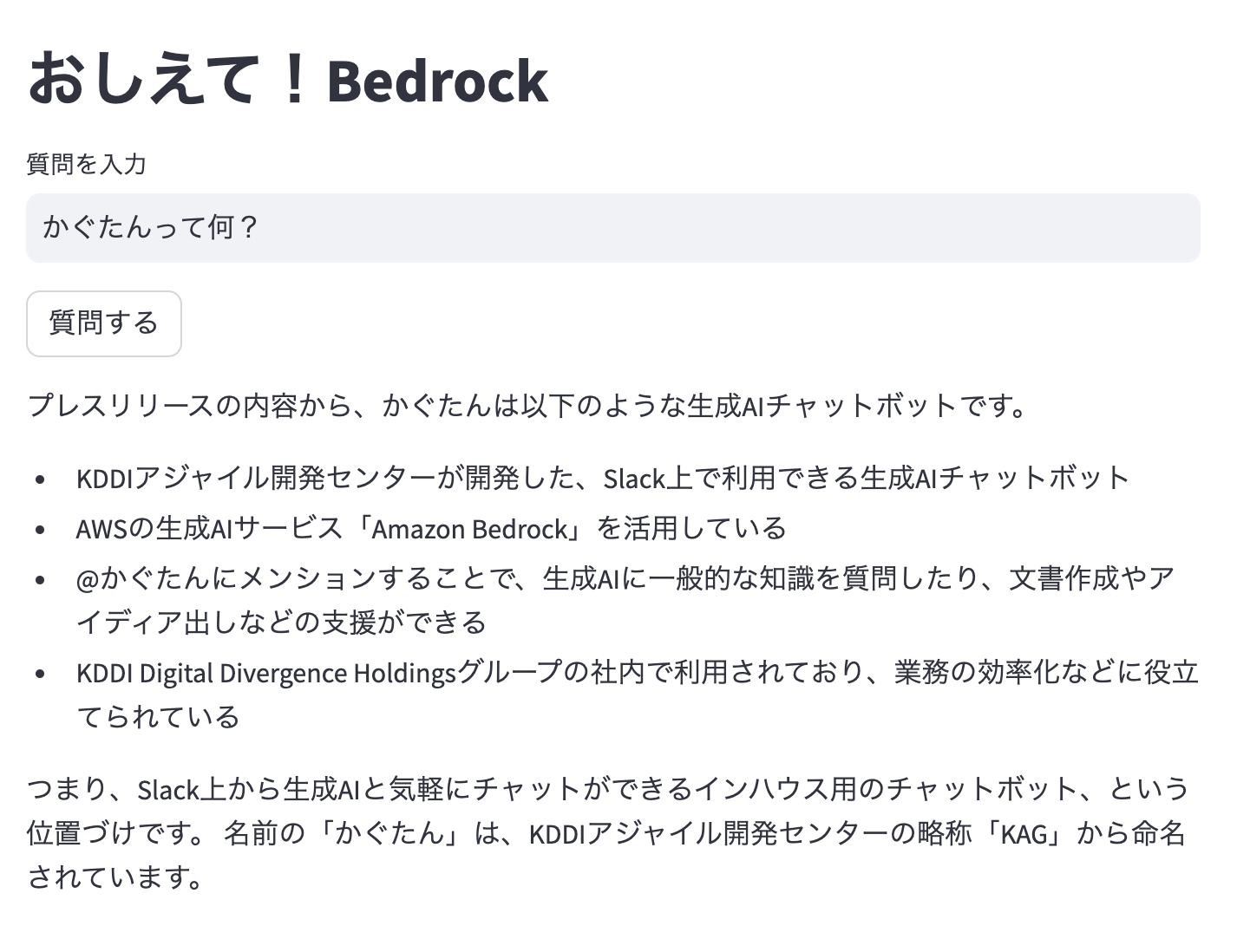
st.title("おしえて!Bedrock")
question = st.text_input("質問を入力")
button = st.button("質問する")
# ボタンが押されたらチェーン実行結果を表示
if button:
st.write(chain.invoke(question))
無事にハイブリッド検索で結果が返されました🎉