動機
仕事で AI や機械学習、データ分析といった技術を身に付ける必要性ができ、
まずは Python を使ったデータ分析を修得するために pandas を
利用したデータ分析にチャレンジしています。
自分にはシステム開発経験があり SQL には使い慣れているのですが、
pandas のデータ分析の記述方法があまり理解できない状況でした。
巷では「pandas は SQL と似ている」といった表現をよく聞くので、
それならば SQL での書き方を pandas の書き方と比較したら
理解が深まるのではないかと思い、今回まとめてみました。
なお本記事は、ある程度のターミナル操作や
MySQL、Python、pandas についての知識がある方を対象としています。
なお、ここからの説明は長いためコードの比較結果のみを見たい場合は、
比較結果まとめを参照ください。
環境
| 項目 | 内容 |
|---|---|
| OS | CentOS Linux release 7.5.1804 |
| DB | 5.7.23-23 Percona Server (GPL), Release 23, Revision 500fcf5 |
| Python | anaconda3-5.3.1 / Python 3.7.0 |
| Editor | jupyterlab Version 0.34.9 |
| ブラウザ | Google Chrome 71.0.3578.98 |
DB は、MySQL 互換の「Percona Server」です。
MySQL のコマンドはすべてターミナルより直接入力します。
詳細は割愛しますが、Windows をホストマシンとし、
vagrant でゲスト OS に Linux を使っています。
また Linux では pyenv を利用して、一部パスのみ
上記 Python のバージョンとして動作するように設定しています。
利用データ
MySQL のサンプルデータを使います。
Example Databases → world database
このような素晴らしいサンプルデータがあることに感謝します。
今回は次のデータを利用します。
- データベース:world
- テーブル:
- city
- country
環境準備
ダウンロードした MySQL のサンプルデータを解凍し、次のようなコマンドでデータベースに取り込みます。
「world」という名前のデータベース(スキーマ)を作成するため、事前に利用するデータベースに重複する名前がないか確認することをお勧めします。
mysql -u [MySQLのユーザー] -p < world.sql
MySQL にログイン後、データベースが作成されていることを確認したら、 次のようなコマンドで、今度はタブ区切りの csv ファイルを作成します。
mysql -u [MySQLのユーザー] -p world -e "SELECT * FROM city;" > city.csv
mysql -u [MySQLのユーザー] -p world -e "SELECT * FROM country;" > country.csv
今回は「data」というディレクトリを作って保存したため、
csvファイルのパスは次の通りになります。
- data/city.csv
- data/country.csv
Python コード
Python では、jupyterlab で次のようなコードを記述して
csv ファイルのデータを pandas の DataFrame に取り込みます。
import pandas as pd
city = pd.read_csv("data/city.csv", sep="\t")
country = pd.read_csv("data/country.csv", sep="\t")
抽出方法の比較
1. 列指定
SQL
SELECT ID, Name, CountryCode FROM city;
+----+----------------+-------------+
| ID | Name | CountryCode |
+----+----------------+-------------+
| 1 | Kabul | AFG |
| 2 | Qandahar | AFG |
| 3 | Herat | AFG |
| 4 | Mazar-e-Sharif | AFG |
| 5 | Amsterdam | NLD |
(5件まで)
pandas
city[["ID", "Name", "CountryCode"]]
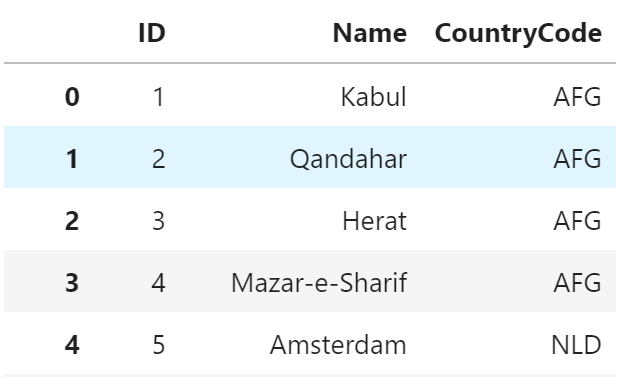
説明
SQL では列名を SELECT句 に指定するのに対して、
pandas では DataFrame のインデックスに列名のリストを指定します。
SQLはテーブル定義されているため、列名をダブルクォートで囲む必要がありません。
対して pandas では文字列として指定するためダブルクォートで囲む必要があります。
2. 条件指定
SQL
SELECT * FROM city WHERE CountryCode = 'NLD';
+----+-------------------+-------------+---------------+------------+
| ID | Name | CountryCode | District | Population |
+----+-------------------+-------------+---------------+------------+
| 5 | Amsterdam | NLD | Noord-Holland | 731200 |
| 6 | Rotterdam | NLD | Zuid-Holland | 593321 |
| 7 | Haag | NLD | Zuid-Holland | 440900 |
| 8 | Utrecht | NLD | Utrecht | 234323 |
| 9 | Eindhoven | NLD | Noord-Brabant | 201843 |
(5件まで)
pandas
city[city.CountryCode == "NLD"]
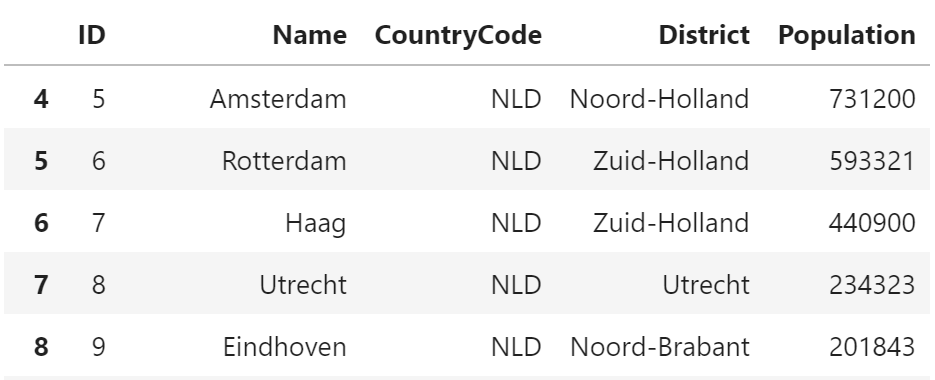
説明
SQL では WHERE句 に条件を指定するのに対して、
pandas では、「ブールインデックス」を使って、
DataFrame のインデックスに条件を指定します。
DataFrame のインデックスに [True, False・・・] のようなリストを、DataFrame のレコード数分指定すると、Trueが指定されたレコードのみを抽出することができます。
city.CountryCode == "NLD"
インデックスに指定しているこの式は、
すべての city のレコードに対して True または False を返す式です。
3. 複数条件指定
SQL
SELECT * FROM city WHERE CountryCode = 'NLD' AND Population < 100000;
+----+---------+-------------+---------------+------------+
| ID | Name | CountryCode | District | Population |
+----+---------+-------------+---------------+------------+
| 30 | Delft | NLD | Zuid-Holland | 95268 |
| 31 | Heerlen | NLD | Limburg | 95052 |
| 32 | Alkmaar | NLD | Noord-Holland | 92713 |
+----+---------+-------------+---------------+------------+
pandas
city[(city.CountryCode == "NLD") & (city.Population < 100000)]
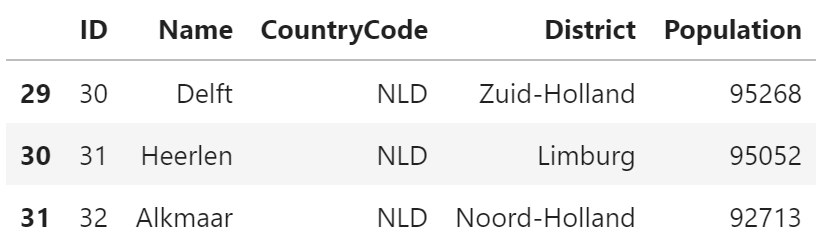
説明
SQL では AND で条件をつなぎますが、
pandas では「&」で条件をつなぎます。
各条件式は()で囲む必要があります。
ブールインデックス同士で両方とも True になるレコードが抽出されます。
4. 複数条件指定(同項目内)
SQL
SELECT * FROM city WHERE CountryCode IN ('SMR', 'TCD', 'SOM');
+------+-------------+-------------+-------------------+------------+
| ID | Name | CountryCode | District | Population |
+------+-------------+-------------+-------------------+------------+
| 3170 | Serravalle | SMR | Serravalle/Dogano | 4802 |
| 3171 | San Marino | SMR | San Marino | 2294 |
| 3214 | Mogadishu | SOM | Banaadir | 997000 |
| 3215 | Hargeysa | SOM | Woqooyi Galbeed | 90000 |
| 3216 | Kismaayo | SOM | Jubbada Hoose | 90000 |
| 3337 | N´Djaména | TCD | Chari-Baguirmi | 530965 |
| 3338 | Moundou | TCD | Logone Occidental | 99500 |
+------+-------------+-------------+-------------------+------------+
pandas
city[city.CountryCode.isin(["SMR", "TCD", "SOM"])]
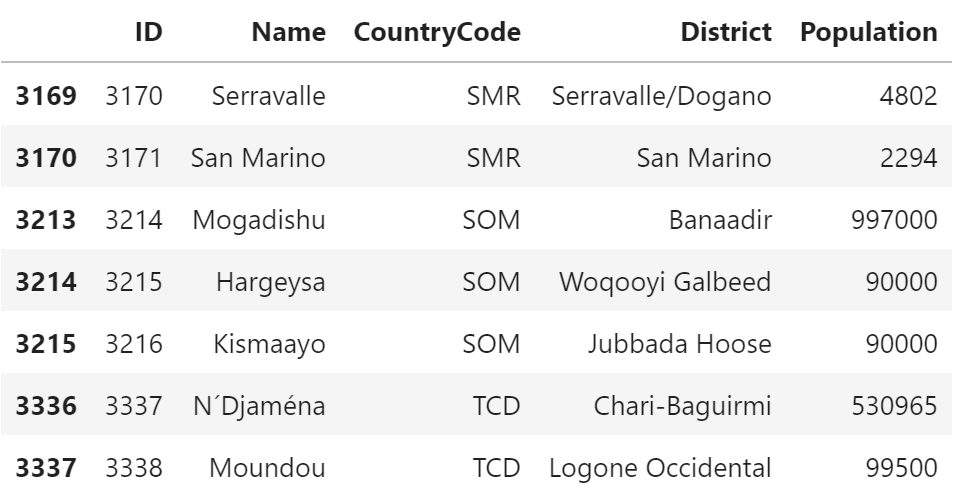
説明
SQL では、IN句 でカンマ区切りに条件を指定します。
pandas では、DataFrame の isin関数 を利用します。
isin関数 の引数に条件をリストで指定します。
5. 件数指定
SQL
SELECT * FROM city LIMIT 5;
+----+----------------+-------------+---------------+------------+
| ID | Name | CountryCode | District | Population |
+----+----------------+-------------+---------------+------------+
| 1 | Kabul | AFG | Kabol | 1780000 |
| 2 | Qandahar | AFG | Qandahar | 237500 |
| 3 | Herat | AFG | Herat | 186800 |
| 4 | Mazar-e-Sharif | AFG | Balkh | 127800 |
| 5 | Amsterdam | NLD | Noord-Holland | 731200 |
+----+----------------+-------------+---------------+------------+
pandas
city.head(5)
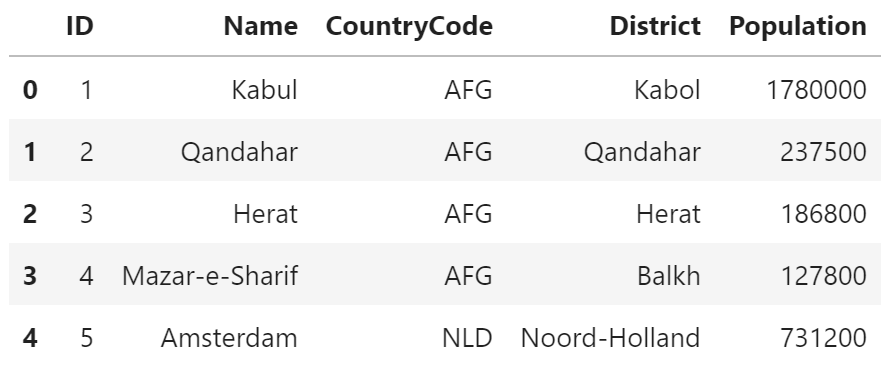
説明
SQL では、LIMIT句 を利用して取得します。
pandas では head関数 を利用します。
また、最後のレコードを取得する tail関数 も存在します。
6. 並び替え
SQL
SELECT * FROM city ORDER BY Population DESC;
+------+-----------------+-------------+--------------+------------+
| ID | Name | CountryCode | District | Population |
+------+-----------------+-------------+--------------+------------+
| 1024 | Mumbai (Bombay) | IND | Maharashtra | 10500000 |
| 2331 | Seoul | KOR | Seoul | 9981619 |
| 206 | São Paulo | BRA | São Paulo | 9968485 |
| 1890 | Shanghai | CHN | Shanghai | 9696300 |
| 939 | Jakarta | IDN | Jakarta Raya | 9604900 |
(5件まで)
pandas
city.sort_values(by="Population", ascending=False)
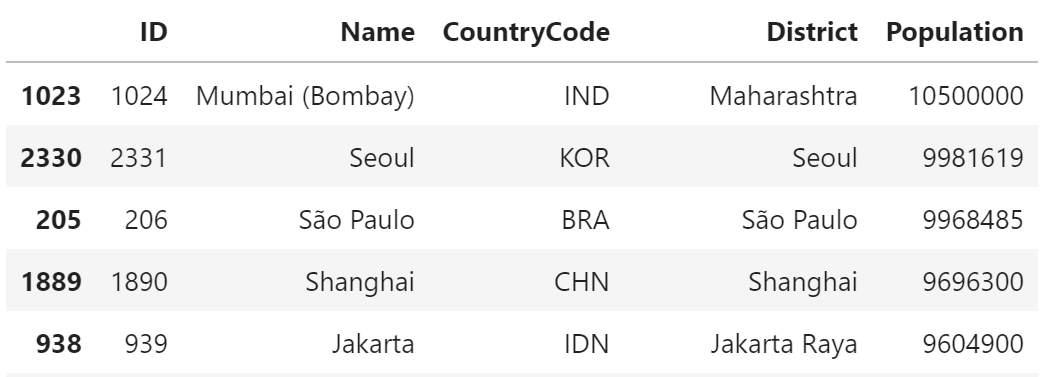
説明
SQL では、ORDER BY句 を利用して並び順を指定します。
pandas では、DataFrame の sort_values関数 を利用します。
引数の by に文字列で列を指定して、降順にする場合は、
引数の ascending に False を設定します。
7. 件数
SQL
SELECT COUNT(*) FROM city;
+----------+
| COUNT(*) |
+----------+
| 4079 |
+----------+
pandas
len(city)

説明
SQL では COUNT関数 を使います。
pandas では複数方法はありますが、len関数 の引数に
DataFrame を指定する方法が SQL とも似ていて分かりやすいと思います。
8. 合計
SQL
SELECT SUM(Population) FROM city;
+-----------------+
| SUM(Population) |
+-----------------+
| 1429559884 |
+-----------------+
pandas
city.Population.sum()

説明
SQL では、SUM関数 を利用します。
pandas では、DataFrame の列に対して合計をとることをオブジェクト指向の方法で sum関数 を使って行います。
9. 平均
SQL
SELECT AVG(Population) FROM city;
+-----------------+
| AVG(Population) |
+-----------------+
| 350468.2236 |
+-----------------+
pandas
city.Population.mean()

説明
SQL では、AVG関数 を使います。
pandas では、DataFrame の列に対して合計をとることをオブジェクト指向の方法で mean関数 を使って行います。
MySQL ではデフォルトの計算では、
Python に比べて精度の低いものになっています。
MySQL で小数精度を高める方法の一つとして、あらかじめ大きな数をかけて整数とし、
平均をとった後に同じ数で割る方法があります。
MySQL では次のような SQL になります。
SELECT FORMAT(AVG(Population * 100000000000) / 100000000000, 20) FROM city;
+-----------------------------------------------------------+
| FORMAT(AVG(Population * 100000000000) / 100000000000, 20) |
+-----------------------------------------------------------+
| 350,468.22358421181662172100 |
+-----------------------------------------------------------+
Python で同様の方法で計算しても結果は変わりませんでした。
あまり取るべき手法ではないと考えられます。
((city.Population * 100000000000).mean())/100000000000

掛けて割る値を大きくしすぎると、
問題が起きるので気を付ける必要があります。
MySQL ではエラーに、pandas では、不正値が出力されます。
SQL(エラー)
ERROR 1690 (22003): BIGINT value is out of range in '(`world`.`city`.`Population` * 1000000000000)'
pandas(エラー)※不正計算
((city.Population * 1000000000000).mean())/1000000000000

10. データ定義
SQL
desc city;
+-------------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------+------+-----+---------+----------------+
| ID | int(11) | NO | PRI | NULL | auto_increment |
| Name | char(35) | NO | | | |
| CountryCode | char(3) | NO | MUL | | |
| District | char(20) | NO | | | |
| Population | int(11) | NO | | 0 | |
+-------------+----------+------+-----+---------+----------------+
pandas
city.dtypes
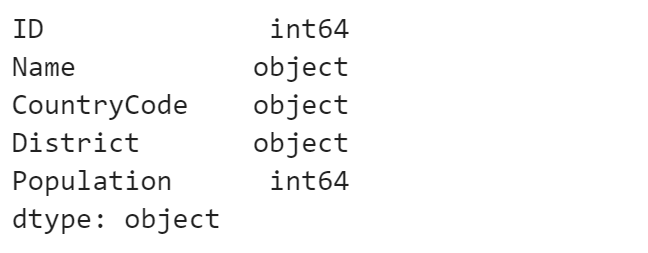
説明
MySQL では、desc コマンドを利用します。
SHOW CREATE TABLE city\G にすると、
テーブル作成クエリを確認できます。
pandas では、dtypesプロパティ で確認できます。
11. あいまい条件指定
SQL
SELECT * FROM city WHERE LOWER(Name) LIKE '%nab%';
+------+---------------------+-------------+-------------------+------------+
| ID | Name | CountryCode | District | Population |
+------+---------------------+-------------+-------------------+------------+
| 38 | Annaba | DZA | Annaba | 222518 |
| 835 | Panabo | PHL | Southern Mindanao | 133950 |
| 1551 | Funabashi | JPN | Chiba | 545299 |
| 1831 | Burnaby | CAN | British Colombia | 179209 |
| 2925 | Guaynabo | PRI | Guaynabo | 100053 |
| 3114 | Osnabrück | DEU | Niedersachsen | 164539 |
| 3610 | Nabereznyje Tšelny | RUS | Tatarstan | 514700 |
| 4078 | Nablus | PSE | Nablus | 100231 |
+------+---------------------+-------------+-------------------+------------+
pandas
city[city.Name.str.lower().str.contains("nab")]
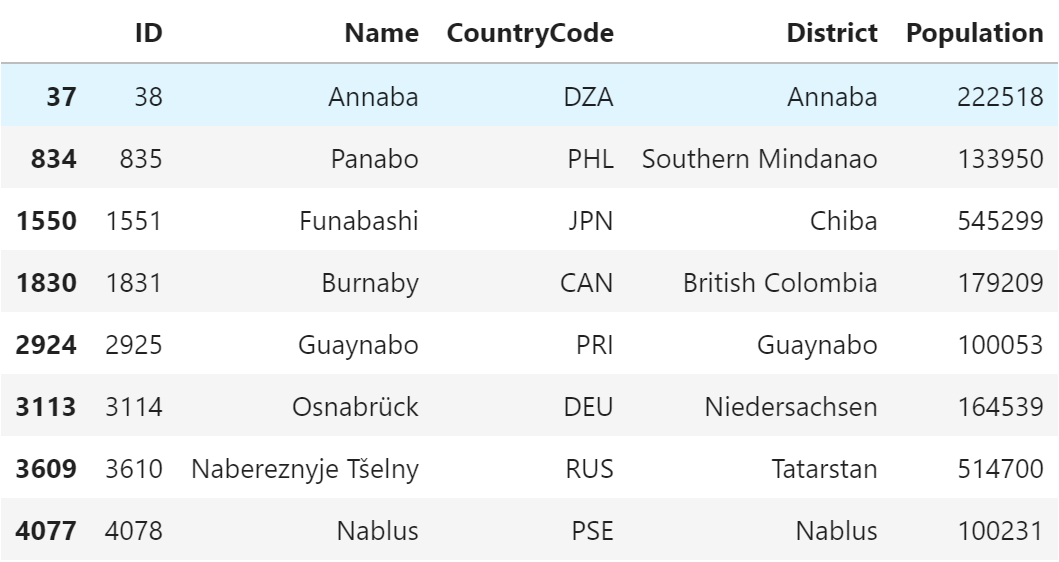
説明
SQL では、LIKEステートメントを利用して、
正規表現の記号として「%」を利用します。
文字列を条件にする場合、大文字・小文字の区別がされない設定に
されていることが多いです。
今回はわかりやすくするため LOWER関数 を利用しましたが、
この関数を利用しなくても結果は同じです。
pandas では、少し工夫が必要で、文字列の列にある strアクセサを使います。
大文字・小文字を区別させない場合は、lower関数 を利用して小文字状態で確認します。
また、今回は「nab」を含むことを条件としているため、
同じく strアクセサ の containsメソッド を利用しています。
12. グループ化
SQL
SELECT CountryCode, COUNT(*) FROM city GROUP BY CountryCode;
+-------------+----------+
| CountryCode | COUNT(*) |
+-------------+----------+
| ABW | 1 |
| AFG | 4 |
| AGO | 5 |
| AIA | 2 |
| ALB | 1 |
(5件まで)
pandas
city.groupby("CountryCode", as_index=False).count()[["CountryCode","ID"]]

説明
SQL では以下を指定するのがポイントです。
- 抽出列
- グループ集計関数
- GROUP BY句
「抽出列」と「GROUP BY句」に指定する列名を同じにし、
必要なグループ集計関数を指定すれば、グループ化されたデータを
抽出することができます。
pandas では、「軸」の考え方が重要で、SQL で抽出列に該当するものです。
この軸を groupby関数 の引数に文字列で指定して、
どこのの列を集計処理するのか、どのように集計するのかを関数にすることでグループ化したデータを抽出することができます。
今回は次の通りです。
- 軸 ⇒ CountryCode
- どこの列を集計処理 ⇒ ID
- どのように集計 ⇒ 件数を集計(count)
as_index に False を指定しているのは、
指定しないと、軸をインデックスに設定してしまうので
他と違い扱いづらくなるためです。
13. テーブル結合
SQL
SELECT city.CountryCode, country.Name AS CountryName, city.Name AS CityName FROM city LEFT JOIN country ON city.CountryCode = country.Code;
+-------------+-------------+----------------+
| CountryCode | CountryName | CityName |
+-------------+-------------+----------------+
| AFG | Afghanistan | Kabul |
| AFG | Afghanistan | Qandahar |
| AFG | Afghanistan | Herat |
| AFG | Afghanistan | Mazar-e-Sharif |
| NLD | Netherlands | Amsterdam |
(5件まで)
pandas
country_city = pd.merge(city, country,
how="left", left_on="CountryCode", right_on="Code"
)[["CountryCode", "Name_y", "Name_x"]]
country_city.columns = ["CountryCode", "CountryName", "CityName"]
country_city

説明
SQL では、LEFT JOIN句 を使って結合するテーブルと、
結合条件を指定します。
また列名は AS句 を使ってエイリアス指定により変更します。
pandas では処理が2段階に分かれます。
まずは、pandas の merge関数 を使って
結合するデータを2つ指定し、結合方法、結合条件となる列名を指定します。
「Name_y」「Name_x」としているのは、
city、country ともに「Name」という列を保持しているため、
pandas がデフォルトで重複する場合にサフィックスとして「_x」「_y」を
つけるためです。
次に columnsプロパティ に新しい列名を設定しています。
14. グループ化 + 並び替え + 件数指定 + 件数
SQL
SELECT CountryCode, COUNT(*) AS cnt FROM city GROUP BY CountryCode ORDER BY cnt DESC LIMIT 7;
+-------------+-----+
| CountryCode | cnt |
+-------------+-----+
| CHN | 363 |
| IND | 341 |
| USA | 274 |
| BRA | 250 |
| JPN | 248 |
| RUS | 189 |
| MEX | 173 |
+-------------+-----+
pandas
city.groupby("CountryCode", as_index=False)[["ID"]].count().sort_values(by="ID", ascending=False).head(7)

説明
SQL では、グループ集計と並び替え、指定件数を組み合わせただけになります。
pandas では、少々複雑で次の順番でデータ抽出を考えてコードを作りました。
- グループ化
- 抽出列指定
- 集計関数指定
- 並び替え指定
- 抽出件数指定
どの処理も DataFrame を返すので処理順を考えて指定するのがポイントです。
比較結果まとめ
| 1. 列指定 | |
|---|---|
| SQL | SELECT ID, Name, CountryCode FROM city; |
| pandas | city[["ID", "Name", "CountryCode"]] |
| 2. 条件指定 | |
|---|---|
| SQL | SELECT * FROM city WHERE CountryCode = 'NLD'; |
| pandas | city[city.CountryCode == "NLD"] |
| 3. 複数条件指定 | |
|---|---|
| SQL | SELECT * FROM city WHERE CountryCode = 'NLD' AND Population < 100000; |
| pandas | city[(city.CountryCode == "NLD") & (city.Population < 100000)] |
| 4. 複数条件指定(同項目内) | |
|---|---|
| SQL | SELECT * FROM city WHERE CountryCode IN ('SMR', 'TCD', 'SOM'); |
| pandas | city[city.CountryCode.isin(["SMR", "TCD", "SOM"])] |
| 5. 件数指定 | |
|---|---|
| SQL | SELECT * FROM city LIMIT 5; |
| pandas | city.head(5) |
| 6. 並び替え | |
|---|---|
| SQL | SELECT * FROM city ORDER BY Population DESC; |
| pandas | city.sort_values(by="Population", ascending=False) |
| 7. 件数 | |
|---|---|
| SQL | SELECT COUNT(*) FROM city; |
| pandas | len(city) |
| 8. 合計 | |
|---|---|
| SQL | SELECT SUM(Population) FROM city; |
| pandas | city.Population.sum() |
| 9. 平均 | |
|---|---|
| SQL | SELECT AVG(Population) FROM city; |
| pandas | city.Population.mean() |
| 10. データ定義 | |
|---|---|
| SQL | desc city; |
| pandas | city.dtypes |
| 11. あいまい条件指定 | |
|---|---|
| SQL | SELECT * FROM city WHERE LOWER(Name) LIKE '%nab%'; |
| pandas | city[city.Name.str.lower().str.contains("nab")] |
| 12. グループ化 | |
|---|---|
| SQL | SELECT CountryCode, COUNT(*) FROM city GROUP BY CountryCode; |
| pandas | city.groupby("CountryCode", as_index=False).count()[["CountryCode","ID"]] |
| 13. テーブル結合 | |
|---|---|
| SQL | SELECT city.CountryCode, country.Name AS CountryName, city.Name AS CityName FROM city LEFT JOIN country ON city.CountryCode = country.Code; |
| pandas | country_city = pd.merge(city, country, how="left", left_on="CountryCode", right_on="Code" )[["CountryCode", "Name_y", "Name_x"]] country_city.columns = ["CountryCode", "CountryName", "CityName"] country_city |
| 14. グループ化 + 並び替え + 件数指定 + 件数 | |
|---|---|
| SQL | SELECT CountryCode, COUNT(*) AS cnt FROM city GROUP BY CountryCode ORDER BY cnt DESC LIMIT 7; |
| pandas | city.groupby("CountryCode", as_index=False)[["ID"]].count().sort_values(by="ID", ascending=False).head(7) |
所感
pandas での書き方だけで考えていたらあまり理解できませんでしたが、
SQL で書いたものを pandas で書く、と考えたところ理解しやすく感じました。
抽出条件が複雑になると SQL の方が組み立てやすく、
pandas では特徴を理解して工夫をする必要があるように感じました。
この辺りは実践で反復して身に付ける必要があると思います。
pandas では、戻り値が2次元データの DataFrame なのか、
1次元データの Series なのかを考えるのがコツに感じました。
DataFrame であればその後ろに DataFrame 用の
関数や記述ができるので、少し複雑になっても組み合わせられると思います。
Series であれば値がすべてブール型ならば、
DataFrame のインデックスに指定して条件とできると考えるのがよいと思います。
以上です。
この記事が同じようなことを考えられている方にとって、
有用になれば幸いです。