はじめに
Jetson TX1のGPUを使用した効能を調査します。
第一回として、Pythonでもお手軽にGPU環境が使用できるCuPyを使用してみました。
(C/C++よりPythonの方がサクッと試せそうだったのでPythonを選択しています)
(ゴリゴリにCUDAやGPGPUを活用したい場合はC/C++を選択すべきかも?)
CuPyとは
Chainerをインストールすることで使用できるPython用ライブラリ。
NumPyと同じ構文・感覚で使用でき、うまく使えばNumPyとCuPy配列を手軽に切り替えられる。
import numpy
import cupy
# xp = numpy
xp = cupy
a = xp.arange( 25 ).reshape( 5 , 5 )
a = a.dot( a )
参考リンク: Preferred Networks社のスライドシェア
参考リンク: [ChainerとCuPyについて] (http://sora-sakaki.hatenablog.com/entry/2015/09/23/232409)
GPUの効能調査
CPU代表としてNumPyに、GPU代表としてCuPyに頑張ってもらいます。
比較方法
- 配列の内積を求めるプログラムで計算時間を比較する。
- 配列の準備やGPUのデバイスオープンの時間は除き、純粋に内積の計算時間のみ比較する。
- 下記プログラム内の「xp = ○○」をコメントアウトで切り替えることで、CPUのみとGPUを使用した場合を切り替える
- 下記プログラム内の「N」を10~1000変えてみて、CPUのみとGPUを使用した場合の計算時間を求める
- ターミナルにて「python gpu_test.py」を実行し処理時間を出力させる
import time
import numpy
import cupy
# xp = numpy
xp = cupy
# 配列の次元
N = 10
N2 = N * N
# 配列のセット
a = xp.arange( N2 ).reshape( N , N )
start = time.time()
# 内積の計算
a = a.dot( a )
end = time.time()
# 内積の計算時間を出力する
print ( end - start )
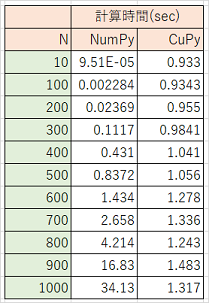
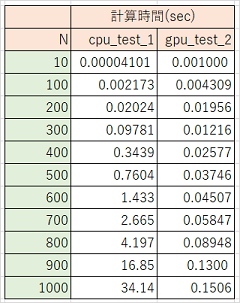
結果
- 500×500配列の内積計算まではCPUの方が高速、700×700配列以降はGPUの圧勝
- 配列の次元が増加するに連れ、
- CPUのみの場合はは指数関数的に計算時間が伸びている
- GPUを使用すると計算時間は微増するだけ
結果をまとめた表とグラフ
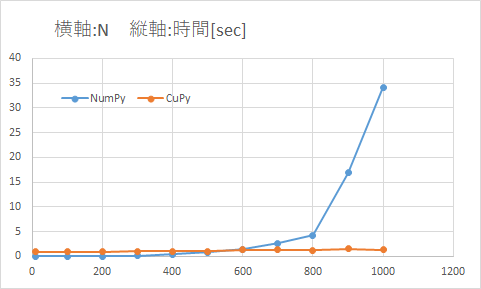
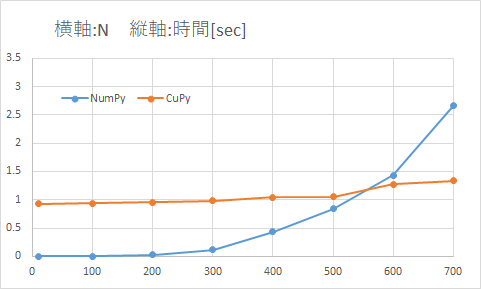
横軸の範囲を0~1200 -> 0~700、縦軸の範囲を0~40 -> 0~3.5に変更したグラフ
GPUの効能調査(追加確認)
chachayさんのナイスなコメントをいただきましたので、CuPyに関して追加で確認を実施しました。
(chachayさん、ありがとうございますm(_ _)m)
CuPyで内積を計算する前に、CuPyを用いた適当な計算を行うことにしました。
追加確認の内容
追加確認では下記の2種のプログラムを使用します。
- gpu_test_1.py:
- 上のテストとやってることは変わらない
- 1回プログラムを実行(ターミナルで「python gpu_test_1.py」)すればN=10~1000まで全部計算してくれる
- gpu_test_2.py:
- 計算時間を計測したい内積計算の前にCuPyを用いた適当な計算を行い、CUDAのコンパイルを先に完了させる
- 1回プログラムを実行(ターミナルで「python gpu_test_2.py」)すればN=10~1000まで全部計算してくれる
import time
import numpy
import cupy
# xp = numpy
xp = cupy
N = [10,100,200,300,400,500,600,700,800,900,1000]
# if xp == cupy:
# z = xp.arange(4).reshape( 2 , 2 )
# z.dot( z )
for N in N:
N2 = N * N
a = xp.arange(N2).reshape(N, N)
start = time.time()
a.dot(a)
end = time.time()
print str(N) + " * " + str(N) + " => " + str(end - start)
import time
import numpy
import cupy
# xp = numpy
xp = cupy
N = [10,100,200,300,400,500,600,700,800,900,1000]
# CuPyを用いた適当な計算を実行し、CUDAのコンパイルを先に完了させる
if xp == cupy:
z = xp.arange(4).reshape( 2 , 2 )
z.dot( z )
for N in N:
N2 = N * N
a = xp.arange(N2).reshape(N, N)
start = time.time()
a.dot(a)
end = time.time()
print str(N) + " * " + str(N) + " => " + str(end - start)
追加確認の結果
先にCUDAのコンパイルを完了させるのとさせないのでは、1回目の内積計算で大きな差(約0.6sec)が出ました。
結果をまとめた表とグラフ
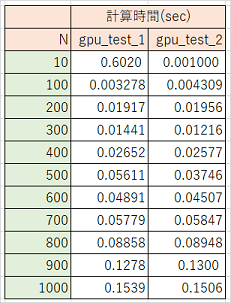
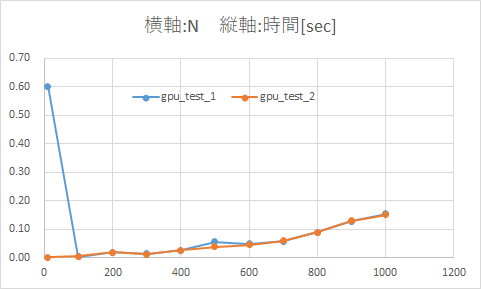
縦軸の範囲を0~0.7 -> 0~0.18に変更したグラフ
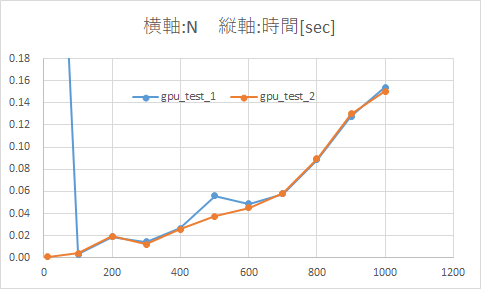
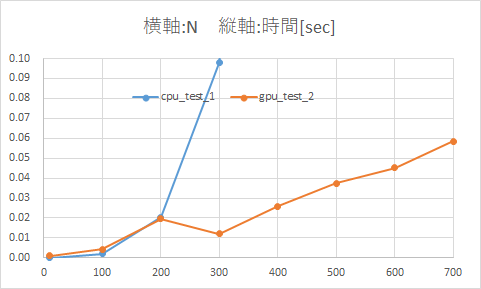
CPU(NumPy)とGPU(CuPy)の計算時間 決定版
※Jetson TX1の場合の計算時間です
(他のGPUボード等では結果に差が出る可能性があります)
- 10×10配列など配列の次元が小さい場合はCPUの方が高速だが、200×200配列以降はGPUの方が速くなる
- 配列の次元が増加するに連れ、
- CPUのみの場合はは指数関数的に計算時間が伸びている
- GPUを使用すると計算時間は微増するだけ
結果をまとめた表とグラフ
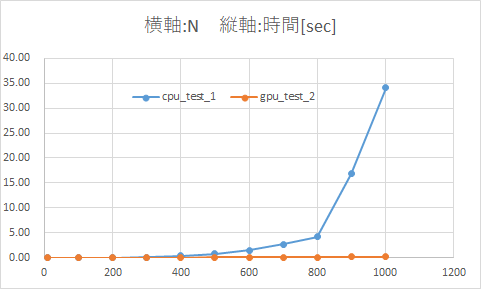
横軸の範囲を0~1200 -> 0~700、縦軸の範囲を0~40 -> 0~0.1に変更したグラフ
終わりに
配列の次元が小さく並列度が小さい場合は、GPUの効果があまり感じられないことが分かりました(いまさら感)。
ただ、内積計算だけで言えば、700×700配列を使用しなければGPUの効果が得られないのは意外でした。
CPUからGPUへのメモリアクセスによる遅延だけが問題なのか、それ以外に問題があるのか深堀したいですね。
(2016/09/23追記)
Jetson TX1において、内積の計算は200×200配列以降でGPUの方が速く計算できることがわかりました。
関数自体を並列化するなどすれば、配列の次元が小さくてもGPUの方が速く計算できそうな気がします。
(CuPyで関数の並列化できるのかなど、今後の調査課題も見つかりました)
また、追加確認の結果、最初にCuPy実行時にCUDAのコンパイルが実行されるということがわかりました。
コメントでご指摘をくださったchachayさん、ありがとうございます!