はじめに
前々回、前回でRabbitMqの使い方をまとめました。今度はもう少し範囲を広げてプロデューサーとコンシューマの関係からRabbitMqの使い方を調べたので、メリットを簡単な例と一緒にまとめます。
環境
- python:3.6.5
- Java:11.0.5
- イメージ:rabbitmq:3-management
RabbitMqを使用するメリット
- キューのメッセージをためて順次実行できる
- プロデューサ・コンシューマの追加が容易
- プロデューサ・コンシューマの追加が任意のタイミングで可能
- メッセージの振り分けを分散可能
キューのメッセージをためて順次実行できる
プロデューサーから送信されたメッセージをキューにためて、その順にコンシューマが受信して処理を実行する。
シチュエーション例
複数の人が使用するWEBサイトなどで、同時に実行できないジョブを動かすとき。
プロデューサー
サンプルソース
キューに入れる処理はコンシューマの処理を待たずに終了するため、メッセージを2回送信しているだけです。
import pika
import datetime
pika_param = pika.ConnectionParameters('localhost')
connection = pika.BlockingConnection(pika_param)
channel = connection.channel()
channel.queue_declare(queue='hello')
print('Send Message 1 Start. {}'.format(datetime.datetime.now()))
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World 1')
print('Send Message 1 End. {}'.format(datetime.datetime.now()))
print('Send Message 2 Start. {}'.format(datetime.datetime.now()))
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World 2')
print('Send Message 2 End. {}'.format(datetime.datetime.now()))
実行結果
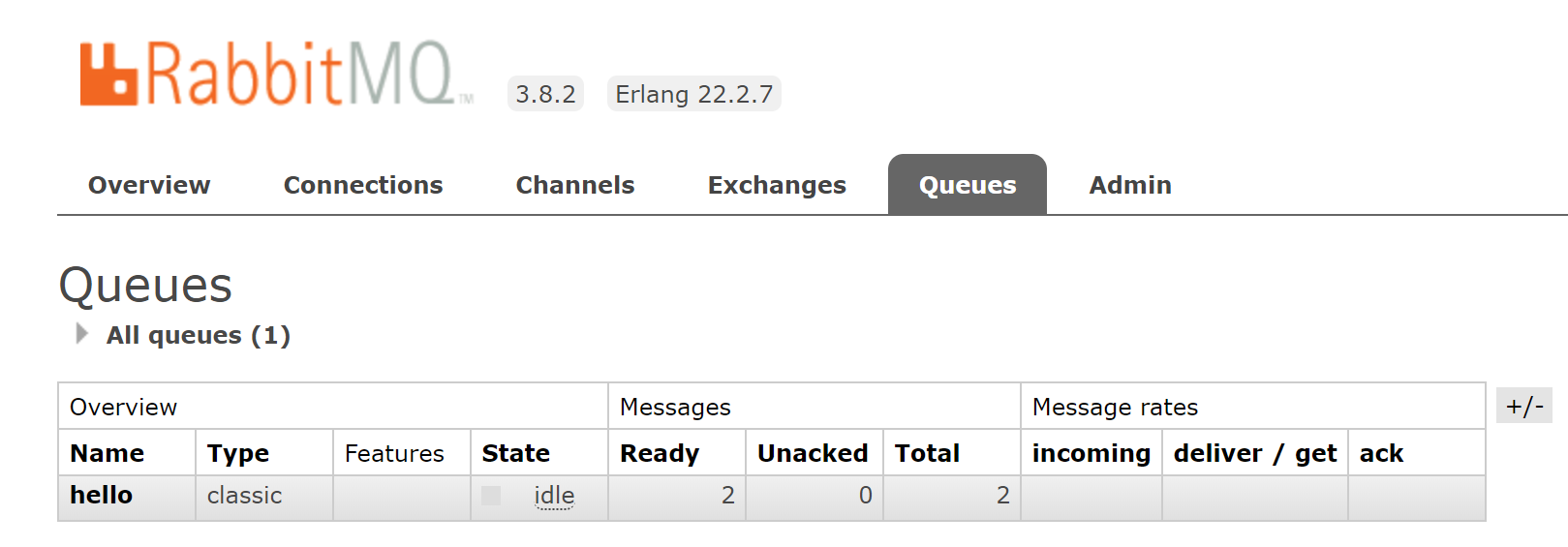
サンプルを実行すると送受信の時間が表示されて終了します。管理画面でQueuesを見るとMessageに2つあることが分かります。
PS C:\Users\xxxx\program\python\pika> python .\client_main.py
Send Message 1 Start. 2020-03-08 18:53:45.658027
Send Message 1 End. 2020-03-08 18:53:45.659027
Send Message 2 Start. 2020-03-08 18:53:45.659027
Send Message 2 End. 2020-03-08 18:53:45.660026
コンシューマ
サンプルソース
受信側はキューから処理を取り出して実行する関数を用意するだけです。
import datetime
import pika
pika_param = pika.ConnectionParameters(host='localhost', channel_max=2)
connection = pika.BlockingConnection(pika_param)
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print("{} Received. {}".format(body, datetime.datetime.now()))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(
queue='hello', on_message_callback=callback)
channel.start_consuming()
実行結果
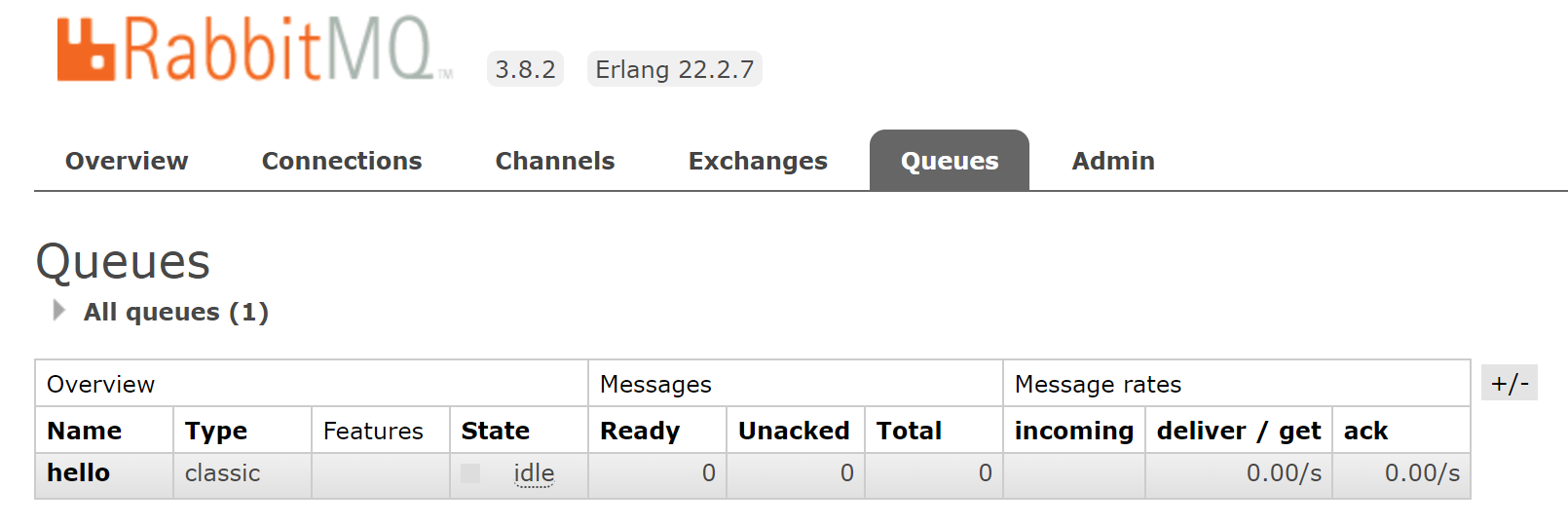
サンプルを実行するとちゃんと送信したときと同じ順番で処理が行われています。メッセージを処理したため管理画面でQueuesを見るとMessageが0であることが分かります。
PS C:\Users\xxxx\program\python\pika> python .\host_main.py
b'Hello World 1' Received. 2020-03-08 19:02:11.756469
b'Hello World 2' Received. 2020-03-08 19:02:11.757469
プロデューサ・コンシューマの追加が容易
プロデューサーとコンシューマが独立して実行することができるのでプロデューサーやコンシューマを容易に増やすことができます。また、メッセージの振り分けに関してはデフォルトで分散されるようになっているため、複数のコンシューマを追加すると自然に分散されます。
シチュエーション例
システムの利用者が増えてバックの処理が不足しているため、コンシューマを増やして対応する。
プロデューサー
サンプルソース
プロデューサーが起動している最中にコンシューマを増やしたいため、20回ほどメッセージを送信して、その間にコンシューマを増やします。
import time
import datetime
import pika
pika_param = pika.ConnectionParameters('localhost')
connection = pika.BlockingConnection(pika_param)
channel = connection.channel()
channel.queue_declare(queue='hello')
for i in range(20):
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World {}'.format(i))
print('Send Message {} Exec. {}'.format(i, datetime.datetime.now()))
time.sleep(2)
connection.close()
コンシューマ
サンプルソース
受信側はキューから処理を取り出して実行する関数を2つ用意しました。それぞれのソースだとわかるように表示するメッセージに数字を入れています。
import datetime
import pika
pika_param = pika.ConnectionParameters(host='localhost', channel_max=2)
connection = pika.BlockingConnection(pika_param)
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print("Host1 {} Received. {}".format(body, datetime.datetime.now()))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(
queue='hello', on_message_callback=callback)
channel.start_consuming()
import datetime
import pika
pika_param = pika.ConnectionParameters(host='localhost', channel_max=2)
connection = pika.BlockingConnection(pika_param)
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print("Host 2 {} Received. {}".format(body, datetime.datetime.now()))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(
queue='hello', on_message_callback=callback)
channel.start_consuming()
実行結果
実行するときは以下の順番で実行して送信側が起動中に受信側を増やすようにしました。
- host1_main.pyを実行
- client_main.pyを実行
- host1_main.pyがいくつかメッセージを受信する
- host2_main.pyを実行
client_main.pyの表示
PS C:\Users\xxxx\program\python\pika> python .\client_main.py
Send Message 0 Exec. 2020-03-08 19:48:12.834261
Send Message 1 Exec. 2020-03-08 19:48:14.835843
Send Message 2 Exec. 2020-03-08 19:48:16.838815
Send Message 3 Exec. 2020-03-08 19:48:18.839815
Send Message 4 Exec. 2020-03-08 19:48:20.840815
Send Message 5 Exec. 2020-03-08 19:48:22.841815
Send Message 6 Exec. 2020-03-08 19:48:24.842788
Send Message 7 Exec. 2020-03-08 19:48:26.843861
Send Message 8 Exec. 2020-03-08 19:48:28.845190
Send Message 9 Exec. 2020-03-08 19:48:30.845934
host1_main.pyの表示
PS C:\Users\xxxx\program\python\pika> python .\host1_main.py
Host1 b'Hello World 0' Received. 2020-03-08 19:48:12.836260
Host1 b'Hello World 1' Received. 2020-03-08 19:48:14.839838
Host1 b'Hello World 2' Received. 2020-03-08 19:48:16.841816
Host1 b'Hello World 3' Received. 2020-03-08 19:48:18.840818
Host1 b'Hello World 4' Received. 2020-03-08 19:48:20.842817
Host1 b'Hello World 6' Received. 2020-03-08 19:48:24.844791
Host1 b'Hello World 8' Received. 2020-03-08 19:48:28.847190
host2_main.pyの表示
PS C:\Users\xxxx\program\python\pika> python .\host2_main.py
Host 2 b'Hello World 5' Received. 2020-03-08 19:48:22.843819
Host 2 b'Hello World 7' Received. 2020-03-08 19:48:26.845863
Host 2 b'Hello World 9' Received. 2020-03-08 19:48:30.847937
実行結果を見るとコンシューマを増やしたタイミングで増やしたコンシューマ側にもメッセージが来ていることがわかります。また、メッセージの分散処理も正常に働いており交互にメッセージを処理しています。
プロデューサ・コンシューマの追加が任意のタイミングで可能
プロデューサ・コンシューマの追加が容易の例と同じです。
メッセージの振り分けを分散可能
プロデューサ・コンシューマの追加が容易の例と同じです。
別の言語間でもメッセージのやり取りが可能
RabbitMqのクライアントは様々な言語のライブラリが存在するので言語間の差を意識しないでメッセージのやり取りができます。
また、プロデューサとコンシューマだけでなくプロデューサ間、コンシューマ間でも独立して動いているため、言語を統一する必要がありません。
シチュエーション例
様々な言語で動いているサービスを一つのサービスとして提供したいと考え、旧サービスになるべく手を入れずに利用して統合サービスを作成したいとき。
プロデューサー
サンプルソース
上のpythonでのプロデューサを使います。
コンシューマ
サンプルソース
pythonとして上で書かれたhost1_main.pyを使います。別言語としてKotlinとして次のソースを使用します。
import com.rabbitmq.client.AMQP
import com.rabbitmq.client.ConnectionFactory
import com.rabbitmq.client.DefaultConsumer
import com.rabbitmq.client.Envelope
fun main(argv: Array<String>) {
val factory = ConnectionFactory()
factory.host = "localhost"
val connection = factory.newConnection()
val channel = connection.createChannel()
channel.queueDeclare("hello", false, false, false, null)
val callback = object : DefaultConsumer(channel) {
override fun handleDelivery(consumerTag: String, envelope: Envelope, properties: AMQP.BasicProperties, body: ByteArray) {
val message = String(body, charset("UTF-8"))
println("Host Kotlin '$message' Received")
channel.basicAck(envelope.deliveryTag, false)
}
}
channel.basicConsume("hello", false, callback)
}
実行結果
実行するときは、コンシューマを起動してからプロデューサを起動しました。
client_main.pyの表示
PS C:\Users\xxxx\program\python\pika> python .\client_main.py
Send Message 0 Exec. 2020-03-08 21:21:06.572582
Send Message 1 Exec. 2020-03-08 21:21:08.573535
Send Message 2 Exec. 2020-03-08 21:21:10.574442
Send Message 3 Exec. 2020-03-08 21:21:12.575198
host1_main.pyの表示
PS C:\Users\xxxx\program\python\pika> python .\host1_main.py
Host1 b'Hello World 1' Received. 2020-03-08 21:21:08.575536
Host1 b'Hello World 3' Received. 2020-03-08 21:21:12.577199
host_kotlin_mainKt.ktの表示
"C:\Program Files\Java\bin\java.exe" .... Host_kotlin_mainKt
Host Kotlin 'Hello World 0' Received
Host Kotlin 'Hello World 2' Received
実行結果を見るとコンシューマがpythonであっても、Kotlin(Java)であっても正常に動作していることがわかります。
おわりに
RabbitMqの便利な使い方をまとめてみました。RabbitMqと言ったもののほとんどキューイングであったりAMQPであったりとRabbitMq独自のものはほとんどありませんでした。
個人的には自然に分散してくれるところとプロデューサとコンシューマの追加がすごく簡単なところが使いやすいと感じました。
今回はプロデューサとコンシューマの関係に注視してまとめましたが、キューに注視してみるとまだまだたくさん機能がありました。すべて把握するのはすごい時間がかかりそうな気がします。