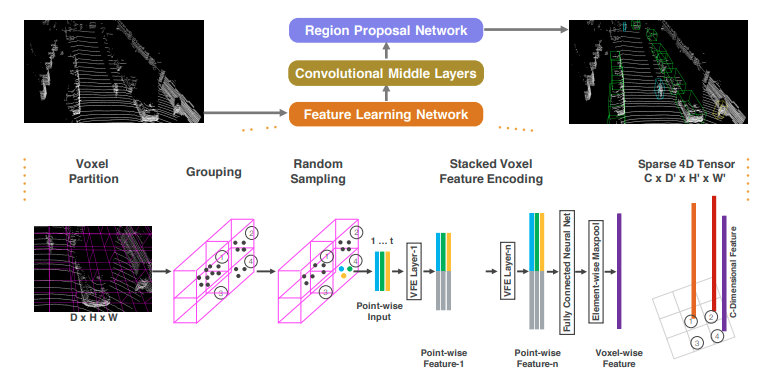
上の図のように3つのModuleからなる
- Feature Learning Network => Voxelの特徴を取り出し、3D Feature Mapを作る
- Convolutional Middle Layers => 3D Feature Mapを2D Feature Mapに落とし込む
- Region Proposal Network => 2D Feature Mapから3D物体検出
ちなみにend-to-endらしい
詳細を見ていこう!
新規性
Feature Learning Network
1. Voxel Partition => 3次元空間を等間隔でVoxelに区切る 2. Grouping => Voxelの中の点群をグループとする 3. Random Sampling => 全部はいらんから任意の数のPointをランダムで選ぶ 4. Stacked Voxel Feature Encoding => Voxelの特徴量をVoxelの中の点群から抽出するRandom Samplingのメリット
1. 計算コストを抑えられる。 2. voxel間のpoint数の不均衡を減らせる。Stacked Voxel Feature Encodingの処理概要
 点は3次元位置と反射強度の情報を持っている。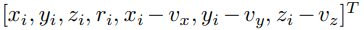
さらにCentroid(voxelの内のpointの平均)からの距離の情報3つを加える。
この7つの特徴量をPoint-wise inputとする。

Fully Connected Layerで特徴量を抽出。
Channel毎の最大値を結合する。(Voxel内の点群の一番強い特徴が残る)

単純にVFEをn回繰り返えす。
最後にFully Connected layerとElement-Wise MaxPoolをしてVoxelの特徴量を得る。

すべてのVoxelに同じ処理をするとVoxelのFeature Map(Channel,Depth,Height,Width)が得られる。
意外とシンプル!