概要
Fully Convolutional Networkを理解してsemantic segmentationを理解してみるBase Network
図からみて分かるようにFCNはConvolutionのみを行い最終的にupsample(interpolation)する。
よって出力のsemantic mapの解像度は低くなる
改善
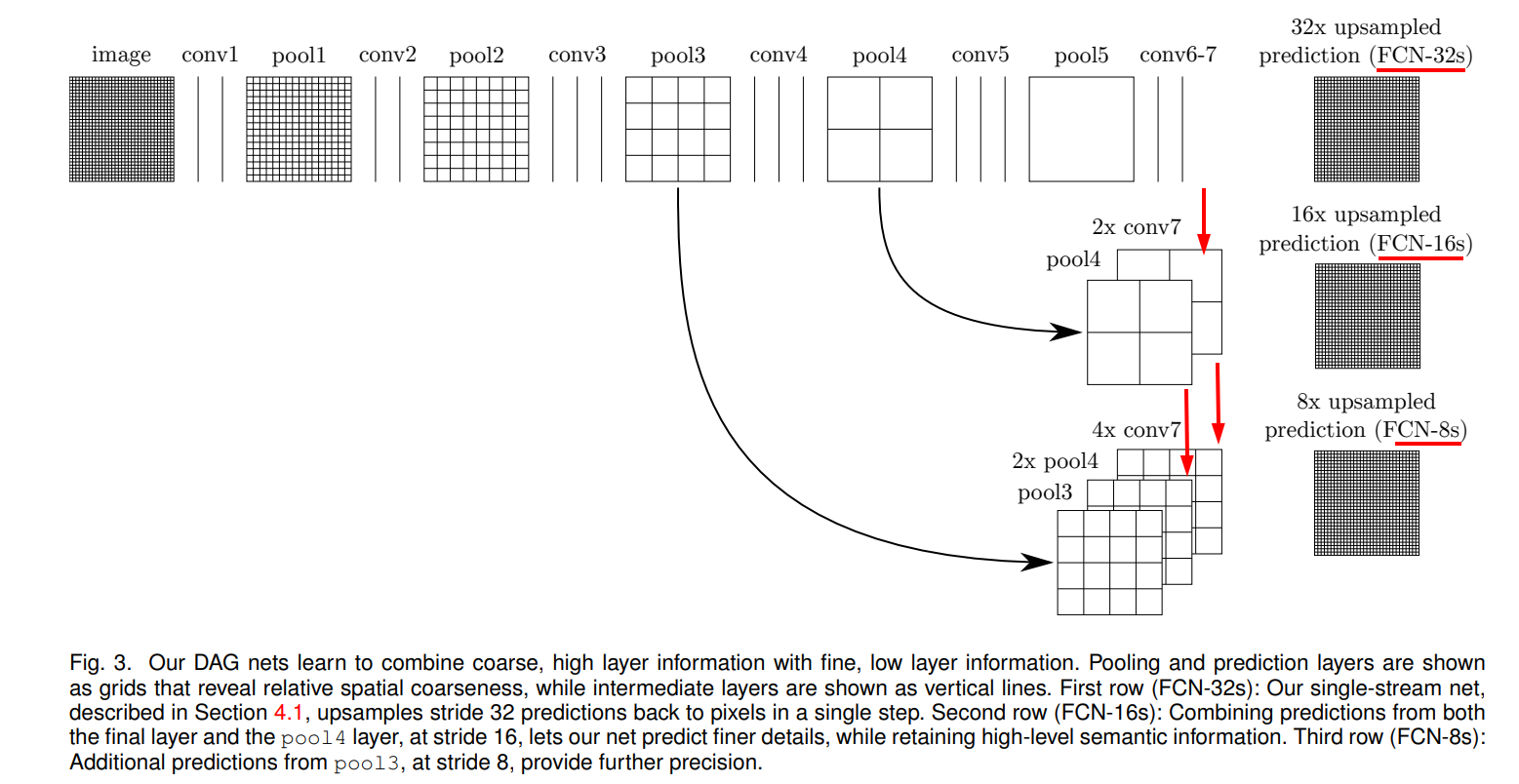
前の情報を足し合わせる事で精度を上げている
FC-32s
1列目はconv7の結果を32倍upsampleしてsegmentation mapを得る
FC-16s
2列目はconv7の結果を2倍upsampleしたものとpool4の結果を足し合わせて、16倍upsampleしてsegmentation mapを得る
FC-8s
3列目はconv7の結果を4倍upsampleしたものとpool4の結果を2倍upsampleしたものとpool3の結果を足し合わせてたものに、8倍upsampleしてsegmentation mapを得る
結果
図から見てわかるようにFC-32s->FC-16s->FC-8sになるに連れて精度が上がっている事が分かる。
FCNの特徴はDecordしない所かな!