概要
PruningにはUnstractured PruningとStructured Pruningがある。
前者はPruningの仕方に制限が無いため精度は保ちやすいが、並列化が難しく高速化が難しい。
一方、後者は規則的にPruningする為精度は落ちやすいが、並列化しやすくGPUなどでも比較的高速化しやすい。
今回はStructured Pruning for Deep Convolutional Neural Networks: A surveyを元に高速化されやすいStructured Pruningについて大まかにまとめる。
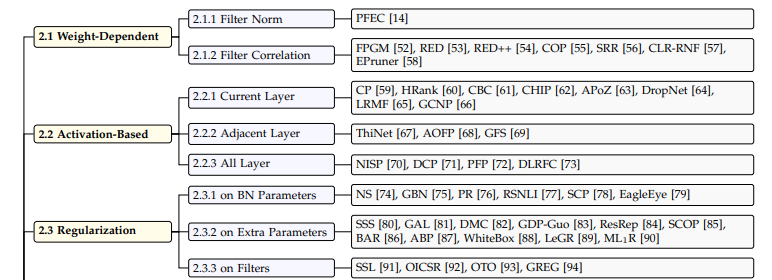
以下の図はPruningの分類である
2.1 Weight-Dependent
convolutionのweightの値によってfilterの重要度を推定
2.1.1 Filter Norm
PFEC(2017)
filterのL1 distanceが小さい順にPruningする
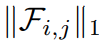
2.1.2 Filter Correlation
FPGM
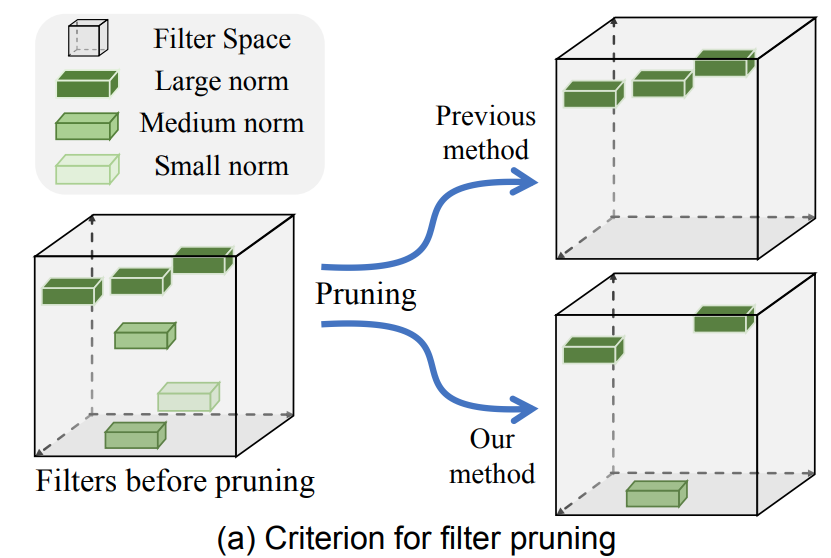
必ずしもnormが小さいfilterの重要度が低いという訳ではなく、似たようなnormが冗長的でという事に気づいた。
2.2 Activation-Based
Activation(layerの出力)によってfilterの重要度を推定
2.2.1 Current Layer
現在のlayerのみでfilterの重要度を推定
CP(2017)
channelをPruneした場合の出力と元の出力の差を計算する。小さい物からPruningしていく。
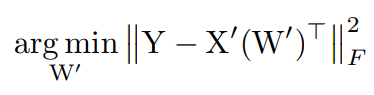
2.2.2 Adjacent Layers
前後のlayerでfilterの重要度を推定
ThiNet(2017)
(l+1)番目のlayerの重要度が低いChannelを見つけて、そのChannelを出力する為に寄与したfilterをl番目のlayerから削除する。
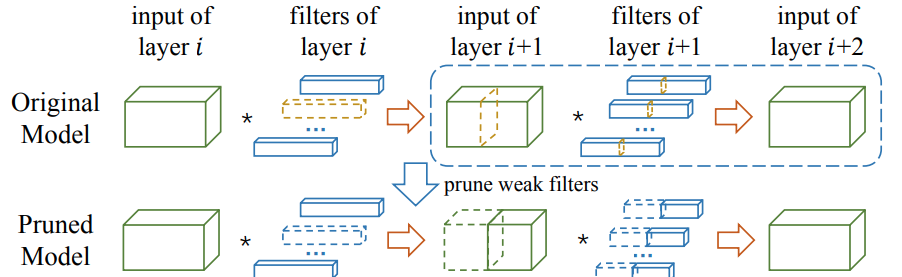
2.2.3 All Layer
モデル最終的な出力な変化によってfilterの重要度を推定
NISP
最後のlayer(Final Response Layer)の値のReconstruction Errorを最小化するようにpruniningする。そのぞれのChannelに対してReconstruction Errorを計算するのはコストが高い為、後方のlayerから一つ前のlayerにimportance scoreを伝播させていく事で計算コストをさげる。
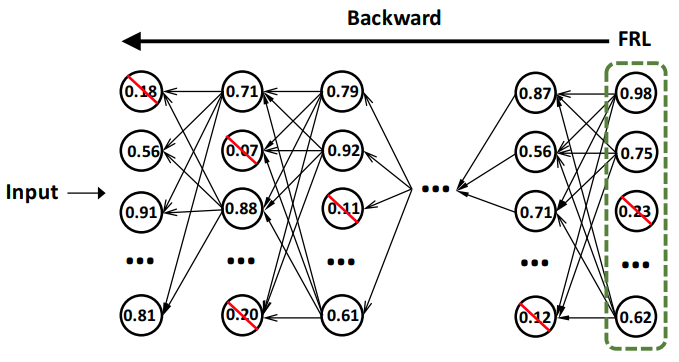
2.3 Regularization
2.3.1 on BN Parameters
BatchNormのParamterでfilterの重要度を推定
NS(2017)
BatchNormのr(channel毎のscaling factor)がZeroに近いChannelを削除
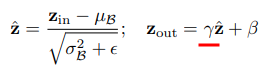
GBN(2019)
scaling factor Φ(Trainable Parameter)を追加する事によってBatch Normのβも含めた出力がzeroになるように学習出来る
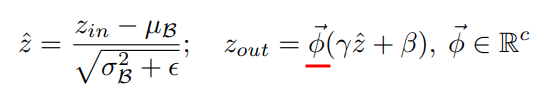
2.3.2 on Extra Parameter
Learnable Parameterを追加してfilterの重要度を推定
SSS(2018)
Trainable Paramter θを追加して、Threshold以下であれば、Channelを削除
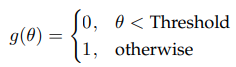
2.3.3 on Filters
GREG(2021)
記載予定
Layer Grouping
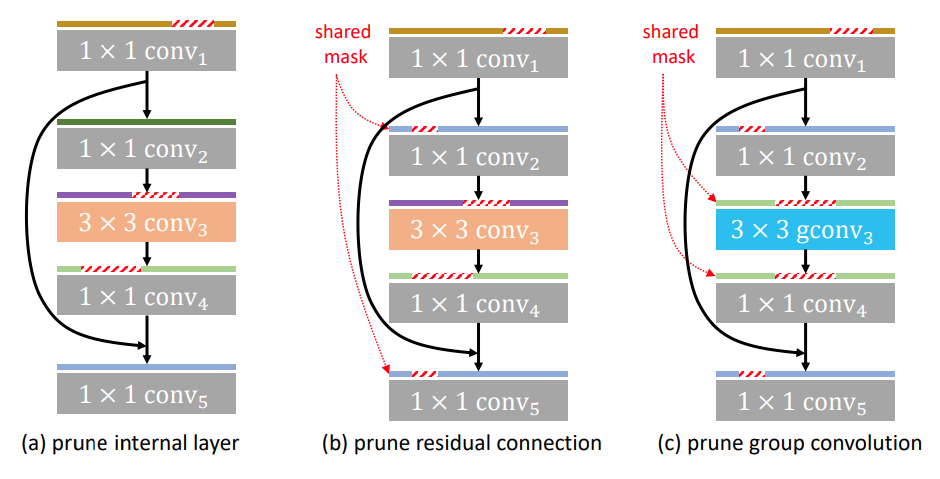
residual connectionなどの複雑な構造はlayer毎にPruningするとchannelの数が一致しない場合がある。layerとlayerとのDependencyを考慮する事でこの問題を解決出来る。
GFP(2021)
residual connectionやgroup convolutionを関連するlayerをgroupingして、一緒にPruningすることで、構造のChannelの数を一致させることが出来る。
その他
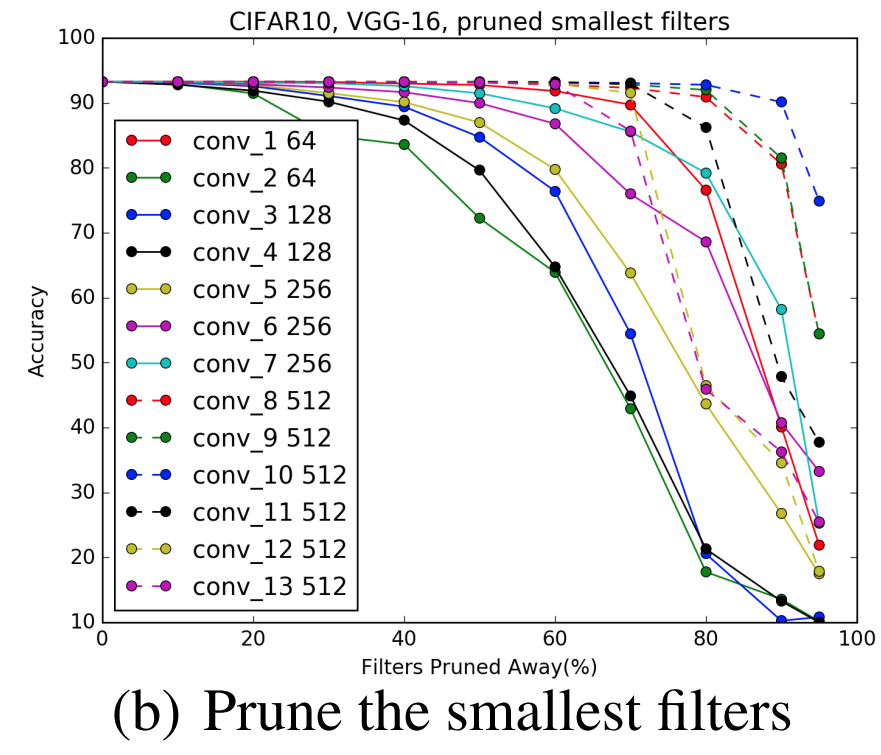
深い層の方がPruneしても精度が落ちにくい