Mishの利点
・少しマイナスの情報を保持することでDyingReLU減少が改善された。 ・Mishは飽和を避けてくれる。一般的にgradientが0に近いとtrainingのスピードが急激に遅くなる ・マイナスに行く事は強い正規化の効果もある ・ReLUのように特異点がない(連続である)Swish Familyを比べてみた
 Swishに似た活性化関数(Swish Family)を比較してみた。 右図から分かるようにMishとxlog(1+tanh(e^x))がSwishよりやや精度が高い事が分かる。しかし、xlog(1+tanh(e^x))はoverfittingしやすく学習が不安定であった。 よってMishが優秀な事が分かる。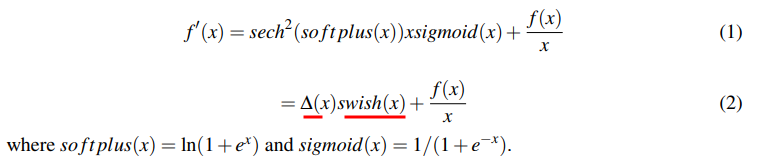
Mishな一次微分を変形してみると(2)のようになる。
∆(x) parameterは前処理のような振る舞いをする。それによって、正規化と勾配をsmoothにしてくれる。Swishに前処理を行うという事はSwishより精度が高くなる可能性があるらしい
Smoothだと何が良いの?
5層のNetworkをランダムにinitializationしReLUとMishを比べてみた。
Mishの方がReLUよりSmoothなのが分かる

図から分かるようにMishの最小値の範囲が一番広い。最小値の範囲が広いとgeneralizationに役立つ。
SwishやReLUは複数の最小値がある=>overfittingしやすい?!
実行速度
 MishはReLUに比べて約3倍遅い。CUDA-baseのimplementationしたMish-CUDAはReLUとほぼ同じ速度になっている。結論
論文が主張している通りであれば、理論も結果もReLUやSwishより良さそう。
今後色々な研究で使われるか見ていきたい。