PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud

2D Object DetectionのRCNNを真似た構造になっている
1st stage =>物体の大まかな位置をPoint Netを使って推定する
2nd stage =>1st stageで得たBounding Boxを入力のPoint CloudとPointNetで得た特徴量を元に修正する
*2DのRCNNと違う所は物体に所属するPointを推定する事と、入力のPoint Cloudを使って2nd stageの修正を行っている(2DだとSemantic Featureだけを入力にして、元のRGBimageを入力していない)
新規性
Bottom-up 3D proposal generation via point cloud segmentation
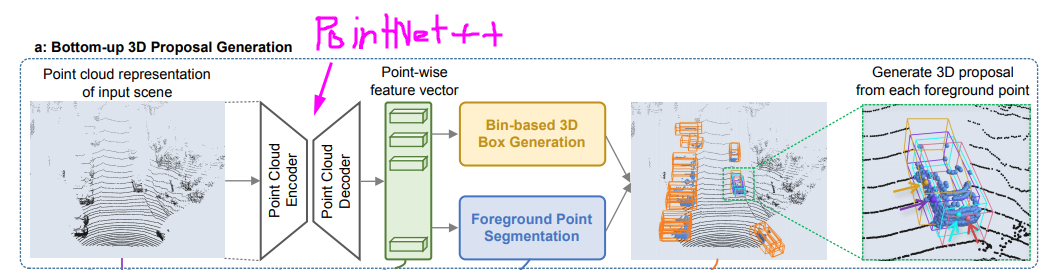Learning point cloud representations
point cloudから特徴量を抽出するのにPointNet++を使用している。 pointの特徴が取れれば別に何でも良いらしい。Foreground point segmentation
得られたPointの特徴からPointが前景(物体の点)かを推定する。 Ground TruthのForeground pointは、Ground TruthのBounding Boxの中に入っているPoint Cloudである。Bin-based 3D bounding box generation
得られたForegroundのPoint Cloudから3D Bounding Boxを推定するPoint cloud region pooling
 1. 得られた3D Bounding Box(オレンジ)のサイズを少し拡大してグレーのBounding Boxを得る 2. ForeGround Point Segmentationで前景として推定されたPointを抽出(地面や壁や木とかのPointを除去できる) 3. 残った青いPoint達に対応する点のSemantic FeatureをPoint-wise feature vectorから取り出す 4. もし一つも点がグレーのBounding Boxに入っていなければ、Bounding Boxを削除Canonical 3D bounding box refinement
Canonical transformation
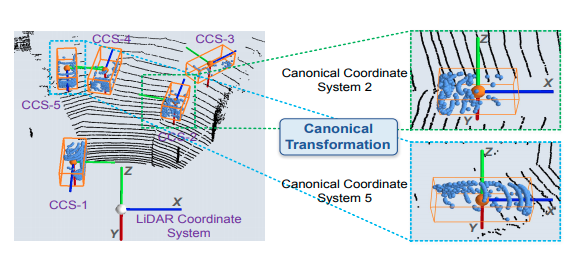 得られた3D Bonding Boxを基準に座標変換を行う。 そうすると学習がしやすいらしい。Feature learning for box proposal refinement
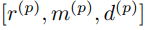 入力となる特徴量はr(反射強度)、m(segmentation mask)、d(LiDARからの距離)を入力とする。*depthの情報を入力する理由はcanonical TransformしたPointの3次元距離の情報がなくなってしまい、密度の違いやIntensityへの影響などを考慮する為。