AdapNet: Adaptive Semantic Segmentation in Adverse Environmental Conditions
basenetworkにResNet+deconvolutionを組み合わせたシンプルなネットワークResNetUpconvを使用している。FCNと同じくらいの精度が出てパラメターが少なくて早かったらしい。
新規性
Multiscale Blocks (MS)
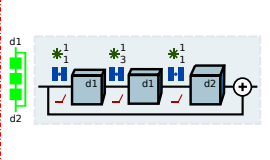
普通のResNetで使われているResidual Block。
*普通の3x3 Convを重ねていくと消失勾配という問題が出るので、入力を足す事で回避
*1x1 Conv(Channel数を小さくする)->3x3 Conv->1x1 Conv(出力したいChannel数にする) => 計算量が小さくなる
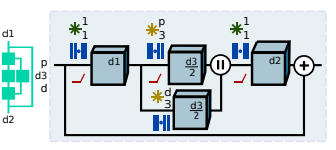
複数のsize(Globalとlocal)の特徴量を学習する為に、channelを半分に分けて別々のDilated(atrous) Convで畳み込み、結合する。
Front Convolution (FC)
ResNetではstride2のConvと2x2Max Poolingで画像サイズが1/4になっていしまう。
High Resolutionの特徴を失っちゃうんじゃね?!という事でその前に3x3 Convを一つ挟んでみたそうです。
convoluted mixture of deep experts (CMoDE)
まだ理解出来ていないので、今後updateします。 分かる人いたら、説明して頂けると嬉しいです。結論
・ResNetにUpconvをしただけのsimpleなネットワークがbase ・Residual Blockを複数のサイズで学習出来るように工夫 ・3x3 convを最初に付け足した ・CMoDEという手法を使っている次はSOTAのAdaptNet++を調べるぞ!