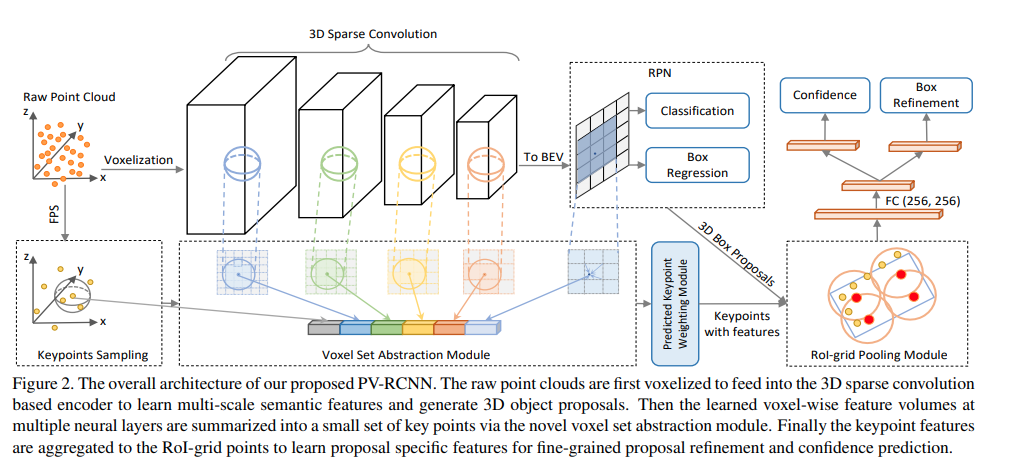
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
sparse convolutionを用いた3D voxel CNNは効率的で良い3D ObjectのProposalが出来る
PointNet-basedの方法はより詳細なcontext情報を柔軟な受容範囲で学習できる。
アルゴリズム
1st stageの3DBounding Boxの提案をしよう
anchor-baseの3D voxel CNN backboneはrecall率がpointnet-baseの手法より高いとです。
SECONDで提案されている3DのVoxelを畳み込んで2Dに落とし込んでから、RPNを行う方法です。
keyPointが物体のPointかどうか重みをつけよう
Keypoints Sampling
FurthestPoint-Sampling (FPS) algorithmを使って任意のn個の点を抽出する。
Voxel Set Abstraction Module

各Voxelの領域内(ROI)で、複数の解像度から得られたFeature Vector結合し、PointNet++でVoxelの特徴を学習する。
*上図を見ると分かりやすい。
Extended VSA(Voxel Set Abstraction) Module

ちょっとまって〜。もっと入力の特徴量を増やしたいよということで
PointVoxel featureにraw point cloud feature と birdeye view featureを追加したら精度が上がったらしい。
Predicted Keypoint Weighting
従来と同じで、前景のpointをsemantic segmentationで見つけましょ〜
Grid Pointと重み付けされたKeyPointから3D Bouding Boxをrefinementしよう
RoI-grid Pooling via Set Abstraction

従来手法では3D Bounding BoxのProposalの中のPointだけを取り出して、特徴量としていた。
この論文では、3D Bounding Boxを均等に分割して、6x6x6個のGrid Pointを定義する。そのGrid Pointから半径r以内のkeyPointの中から任意の数randomに選び、MLPで特徴を学習する。さらにGrid Pointに複数の半径rを定義する事で複数のreceptice fieldの情報を得られる。
3D Proposal Refinement and Confidence Prediction
従来研究と同じく得られた特徴量からBouding Boxを修正する
結果

全体的に精度が結構上がっとる。
結論
・1st stageにVoxel-baseメソッド、2nd stageにPointNet-baseメソッドを用いると精度が良くなる事がわかった。
・Voxel set Abstraction Moduleでマルチ解像度でVoxelの特徴を取るのはSemantic Segmentation(Keypoint weighting)に効果を発揮してる感じがする。
参考文献
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
https://arxiv.org/pdf/1912.13192.pdf