Improving Semantic Segmentation via Video Propagation and Label Relaxation
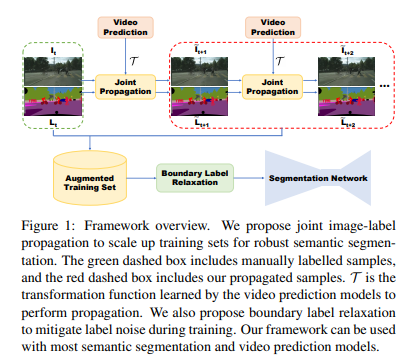annotation dataを増やそうというのがこの論文のメインテーマである。
optical flowを知っている人であれば簡単にイメージ出来ると思うが、画像とGround Truthデータのpixelをともにshiftすることでデータが増やせる。
新規性
データを増やそう
Optical Flow(時系列におけるpixelの移動)を用いる事でground truthのデータ(time=tをシフトしただけ)を生成する事が出来る。
ついでに対応する画像も必要なので、画像もpixelを移動させる
Optical Flow
過去のデータから次のframeの移動量(x,y)を推定するVideo Prediction(Motion Vector)
もうちょっと精度あげたくないってことで
Optical Flowと画像を入力して畳み込みを行いMotion Vectorというのを提案した。
要はOptical FlowをちょっことRefinementしてみた感じ。
*g(I,F): 画像とOptical Flowから得られたMotion Vector
*T(M,I) : Motion Vectorと画像を入力に次のFrameを推定する
Video Reconstruction(Motion Vector)
 過去データと現在のデータから未来を推定するより、未来のデータがあるんだから未来のデータと現在のデータから未来を推定(差分を見る)する方が正確だよね。というアイデアt-1とtから得られたMotion Vector
より
tとt+1から得られたMotion Vector
の方が
tの画像からt+1の画像を推定するのに適している。
*recording dataだから出来る
Boundary Label Relaxation
物体のedgeではannotationが正確でないことはよくある。
例えば、車と人のpixelが隣りあっていたら、人と推定しても車と推定しても正解にしよう!
という優しさがBoundary Label Relaxationである。
結論
・画像の連続性を使いannotationデータを増やしていた。 ・Boundary Label Relaxaxionで物体の境界線はどっちに推定しても良いようにしていた。dataを増やす発送は面白いと思った。しかし、実用として精度が落ちる可能性があるので使わないと思う。
Boundary Label Relaxationは一般的に有効な手段だと感じた。