[前回] Elasticsearchクラスタ検証(4): Elasticsearch 8.xのクラスタ化(HTTPS対応)
はじめに
Elasticsearchクラスタを設計する前に、
Elasticsearchシステム構成の基本をおさらいします。
Elasticsearchとは、その特徴
- 全文検索サーバである、検索エンジンにApache Luceneを使用
- 転置インデックスを使用し、全文検索を高速に
- 分散配置により、検索性能と可用性のスケールアウトを実現
- クラスタ構成でデータを分散保存/処理
- REST APIを使ってJSONフォーマットの文書を扱う
- 他のシステムと親和性がよい
Elasticsearchクラスタのアーキテクチャ概要
※ 引用元: https://raw.githubusercontent.com/exo-addons/exo-es-search/master/doc/images/image_05.png
Elasticsearchの論理構成
用語
- インデックス
- ドキュメントの保存場所
- ドキュメント
- インデックスに格納する一つの文章単位(RDBのレコード相当)
- フィールド
- ドキュメント内のキー/バリューペア
- データ型が存在
- ドキュメント内のキー/バリューペア
- ドキュメントタイプ
- 全フィールドのデータ型(RDBのスキーマ相当)
- 1つのインデックスに一種類のドキュメントタイプのみ
- マッピング
- ドキュメントタイプの定義(RDBのテーブル定義相当)
構成
- インデックス
- ドキュメントタイプ(マッピング)
- ドキュメント1
- フィールド1
- フィールド2
- 。。。
- ドキュメント2
- フィールド1
- フィールド2
- 。。。
- 。。。
- ドキュメント1
- ドキュメントタイプ(マッピング)
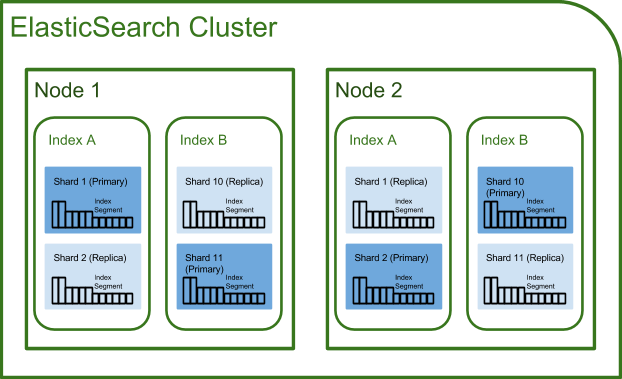
Elasticsearchの物理構成
用語
- ノード
- Elasticsearchが稼働する各サーバ
- クラスタ
- 複数ノードが協調動作するグループ
- シャード
- インデックスを分割する単位
- 実体はLuceneインデックスファイル
- 目的
- 複数ノードで並列検索し性能向上
- インデックス作成後には増やせない
- インデックスを分割する単位
- レプリカ
- シャードの複製である、プライマリとレプリカは異なるノードに配置
- 目的
- 可用性(ノードダウン時データロスト防止)
- 検索性能向上の狙いも
- インデックス作成後も増やせる
構成
- クラスタ
- ノード1
- インデックス1
- シャード1(プライマリ)
- シャード2(プライマリ)
- 。。。
- インデックス2
- シャード1(プライマリ)
- シャード2(プライマリ)
- 。。。
- インデックス1
- ノード2
- インデックス1
- シャード1(レプリカ)
- シャード2(レプリカ)
- 。。。
- インデックス2
- シャード1(レプリカ)
- シャード2(レプリカ)
- 。。。
- インデックス1
- ノード3
- 。。。
- ノード1
おわりに
Elasticsearchのシステム構成をおさらいしました。
次回も続きます。お楽しみに。