[前回] AWS公式資料で挑むMLS認定(7)-Amazon Pollyの基本
はじめに
前回は、Amazon Pollyの機能とユースケースを勉強しました。
今回は、音声変換における技術トピックを勉強します。
テキストから音声への変換処理品質を判断する尺度
- 自然に聞こえるか
- 音声変換出力がどれくらい人間の声に近いか
- 正確さ
- 一般的なテキスト解釈システムの能力
- 略語
- 数字の羅列
- ホモグラフ(同一つづりで発音が異なる語彙)
- 一般的なテキスト解釈システムの能力
- わかりやすさ
- 音声がどれくらいわかりやすいか
Amazon Pollyの仕組み
Amazon Pollyは入力テキストを肉声に近い音声に変換。
処理フロー:
- 合成するテキストを入力
- プレーンテキスト
- または、音声合成マークアップ言語(SSML)形式
- 発音、ボリューム、ピッチ、話す速度など音声要素を制御可能
- 音声合成メソッドを呼び出す
- 音声エンジンを
engineプロパティで指定- Standard(標準音声)
- ニューラル音声
- 音声出力形式を指定
- Webやモバイルアプリ用、MP3やOgg Vorbis形式
- AWS IoTデバイスやテレフォニーソリューション用、PCM形式
- 音声エンジンを
- 合成された音声ストリームを出力
- Amazon Pollyは翻訳サービスではなく、合成音声はテキストと同じ言語
- ただし、テキストと音声言語が異なる場合、音声言語にて合成される
- Amazon Pollyは翻訳サービスではなく、合成音声はテキストと同じ言語
TTS(標準音声) vs. NTTS(ニューラルTTS)
ニューラルTTSが標準TTS音声より高品質で自然、人間に似たものを生み出す。
- TTS
- 標準連結合成技術が使用される
- 録音された音声の音素をまとめ(連結)、自然な合成音声を生成
- ただし、波形をセグメント化する手法であるため、音声のバリエーションや品質が制限される
- 標準連結合成技術が使用される
- NTTS
- sequence-to-sequenceモデルを使用し、スペクトログラムを生成
- 音素のシーケンスをスペクトログラムのシーケンスに変換するニューラルネットワーク
- 音素のシーケンスは、最も基本的な言語単位
- 入力からのみならず、入力要素シーケンスの連携まで考慮
- 人間の脳が使用する音響能力を強調する周波数帯域を使用
- スペクトログラムとは
- 複合信号を窓関数に通し、周波数スペクトルを計算した結果
- 3次元(時間、周波数、信号成分の強さ)のグラフで表される
- 声紋の鑑定、動物の鳴き声の分析、音楽、ソナー/レーダー、音声処理などに使われる
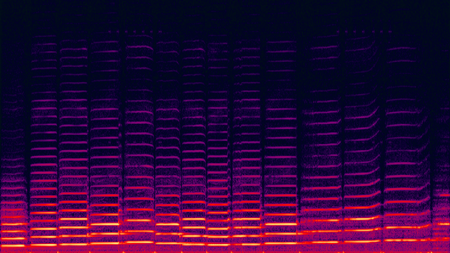
※ 引用元: Wikipediaのスペクトログラム
- 汎用連結合成システムの構築に使用される大規模なデータセットでトレーニングさせると
- より高品質で自然な響きの声を生み出せる
- 音素のシーケンスをスペクトログラムのシーケンスに変換するニューラルネットワーク
- ボコーダーを使用し、スペクトログラムを連続したオーディオ信号に変換
- スペクトログラムが音声波形に変換される
- スペクトログラムのシーケンスは、異なる周波数帯域のエネルギーレベルのスナップショット
- スペクトログラムが音声波形に変換される
- NTTSをコンソールまたはAPIで使用時、TTSエンジンパラメータを
neuralに設定する必要あり - リアルタイムおよび非同期の音声合成オペレーションをサポート
- sequence-to-sequenceモデルを使用し、スペクトログラムを生成
スピーチマーク
- 合成音声を表すメタデータ
- 例えば、音声ストリームで文章または単語の開始/終了
- テキストのスピーチマークをリクエストすると、合成音声の代わりにメタデータを返す
- 合成スピーチ音声ストリームとスピーチマークを組み合わせ、ビジュアル体験を提供するアプリを構築可能
- 例えば、
- スピーチと表情アニメーション(リップシンキング)を同期
- 読み上げられたとおり書かれた単語をハイライト表示
- 例えば、
スピーチマークの種類
- sentence(文)
- 入力テキストで文の要素を示す
- word(単語)
- 入力テキストで単語の要素を示す
- viseme(ビゼーム)
- 音声の視覚的な構成要素で、単語を読み上げる際の顔と口の位置/形を表す
- 話されている各音素に対応する顔と口の動き
- 単語が作られる基本的な音声単位である音素と視覚的に同等
- 各言語に、特定の音素に対応するビゼームセットが含まれている
- すべてのビゼームが特定音素にマッピングできるとは限らない
- 理由は、音声が異なる場合でも、読み上げる際に膨大な音素が表示されるため
- たとえば、英語の
petとbetという単語は聴覚的に異なるが、視覚的に同じ
- 音声の視覚的な構成要素で、単語を読み上げる際の顔と口の位置/形を表す
- ssml
- SSML入力テキストからの
<mark>要素を表す
- SSML入力テキストからの
スピーチマークのリクエスト方法
- コマンド
- SynthesizeSpeech
- または、StartSpeechSynthesisTask
- オプション
-
--output-format json- JSON形式のみサポート
- 未サポート出力形式を使用する場合、Amazon Pollyは例外をスロー
-
--voice-id Joanna- メタデータを音声ストリームと一致させるため指定
- 合成スピーチ音声ストリームの生成に使用されている音声を指定
-
--text-type- デフォルトの入力テキストは、プレーンテキスト
- SSMLスピーチマークを返す場合は、
--text-type ssmlを使用する必要あり
-
--outfile- メタデータが書き込まれた出力ファイルを指定
-
--speech-mark-types='["sentence", "word", "viseme", "ssml"]'- 入力テキストから返すメタデータ要素を指定
- 最大4種類のメタデータをリクエスト可能
- リクエストごとに1種類以上を指定する必要あり
-
スピーチマークの出力フォーマット
スピーチマークのオブジェクトは、改行で区切られたJSONストリーム。
オブジェクトに含まれるフィールド
- time(時間)
- 対応する音声ストリームの開始からのタイムスタンプ(ミリ秒)
- type(種類)
- スピーチマークの種類(文、単語、ビゼーム、ssml)
- start(開始)
- 入力テキストオブジェクトの開始からのオフセット(文字ではなくバイト)(ビゼームマークを含まない)
- end(終了)
- 入力テキストオブジェクトの終了のオフセット(文字ではなくバイト)(ビゼームマークを含まない)
- value(値)
- スピーチマークの種類によって異なる
- SSML:
<mark>SSMLタグ - viseme: ビゼーム名
- word/sentence: 入力テキストの部分文字列
- 開始/終了フィールドで区切られる
- 例: 入力テキスト:
Mary had a little lamb- 生成されるwordスピーチマークのオブジェクト
-
{"time":373,"type":"word","start":5,"end":8,"value":"had"}- 単語
hadは、音声ストリーム開始後373ミリ秒後に開始 - 入力テキストの5バイト目で開始、8バイト目で終了
- 単語
- SSML:
- スピーチマークの種類によって異なる
スピーチマークの例
- 例1: SSMLを使用しないスピーチマーク
aws polly synthesize-speech \
--output-format json \
--voice-id Joanna \
--text 'Mary had a little lamb.' \
--speech-mark-types='["viseme", "word", "sentence"]' \
MaryLamb.txt
スピーチマーク単位で出力が返却される
出力.txtファイル
{"time":0,"type":"sentence","start":0,"end":23,"value":"Mary had a little lamb."}
{"time":6,"type":"word","start":0,"end":4,"value":"Mary"}
{"time":6,"type":"viseme","value":"p"}
{"time":73,"type":"viseme","value":"E"}
{"time":180,"type":"viseme","value":"r"}
{"time":292,"type":"viseme","value":"i"}
{"time":373,"type":"word","start":5,"end":8,"value":"had"}
{"time":373,"type":"viseme","value":"k"}
{"time":460,"type":"viseme","value":"a"}
{"time":521,"type":"viseme","value":"t"}
{"time":604,"type":"word","start":9,"end":10,"value":"a"}
{"time":604,"type":"viseme","value":"@"}
{"time":643,"type":"word","start":11,"end":17,"value":"little"}
{"time":643,"type":"viseme","value":"t"}
{"time":739,"type":"viseme","value":"i"}
{"time":769,"type":"viseme","value":"t"}
{"time":799,"type":"viseme","value":"t"}
{"time":882,"type":"word","start":18,"end":22,"value":"lamb"}
{"time":882,"type":"viseme","value":"t"}
{"time":964,"type":"viseme","value":"a"}
{"time":1082,"type":"viseme","value":"p"}
- 例2: SSMLを使用したスピーチマーク
aws polly synthesize-speech \
--output-format json \
--voice-id Joanna \
--text-type ssml \
--text '<speak><prosody volume="+20dB">Mary had <break time="300ms"/>a little <mark name="animal"/>lamb</prosody></speak>' \
--speech-mark-types='["sentence", "word", "ssml"]' \
output.txt
出力.txtファイル
{"time":0,"type":"sentence","start":31,"end":95,"value":"Mary had <break time=\"300ms\"\/>a little <mark name=\"animal\"\/>lamb"}
{"time":6,"type":"word","start":31,"end":35,"value":"Mary"}
{"time":325,"type":"word","start":36,"end":39,"value":"had"}
{"time":897,"type":"word","start":40,"end":61,"value":"<break time=\"300ms\"\/>"}
{"time":1291,"type":"word","start":61,"end":62,"value":"a"}
{"time":1373,"type":"word","start":63,"end":69,"value":"little"}
{"time":1635,"type":"ssml","start":70,"end":91,"value":"animal"}
{"time":1635,"type":"word","start":91,"end":95,"value":"lamb"}
SSMLドキュメントからの音声生成
-
SSML拡張テキストを使用し、テキストからの音声生成方法を制御
- テキスト内に長い一時停止時間を追加
- 話す速度やピッチを変更
- 特定の単語やフレーズを強調する
- 発音記号を使用する
- 呼吸音を含む
- ウィスパー
- ニュースキャスターの話し方
-
エスケープ処理が必要な予約文字
- 引用符(二重引用符)
":"にエスケープが必要 - アンパサンド
&:&にエスケープが必要 - 一重引用符(アポストロフィまたは)
':'にエスケープが必要 - 小なり記号
<:<にエスケープが必要 - 大なり記号
>:>にエスケープが必要
- 引用符(二重引用符)
-
サポートされるSSMLタグ
- タグ例:
<speak>タグ- すべてのAmazon Polly SSMLテキストのルート要素
- SSML拡張テキストはすべて
<speak>タグで囲む必要あり
- タグ例:
レキシコンの管理
- 発音レキシコンとは
- APIオペレーションを使用し、単語の発音をカスタマイズ
- レキシコンはAWSリージョンに依存
- SynthesizeSpeechオペレーションを使用しテキスト合成時、同じリージョンから1つ以上のレキシコンを使用
- 合成が始まる前に、入力テキストに指定されたレキシコンが適用される
- 音声合成エンジンでレキシコンのユースケース
- テキスト内の
W3Cなど頭文字に対し、レキシコンを使用しエイリアスを定義- 例:
W3Cを完全な形のWorld Wide Web Consortiumに置き換えて読み上げる
- 例:
- 選択した言語で一般的でない単語に対し、音声記号を使用し発音を指定可能
- テキスト内の
複数レキシコンの適用方法
- テキストに最大5つのレキシコンを適用可能
- テキストに適用する複数のレキシコンに同じ書記素がある場合
- 適用順序により音声の結果が異なる
例として、テキストHello, my name is Bobに、二つのレキシコンを適用した場合、
適用順序により、同じ書記素Bobに異なる語彙素RobertまたはBobbyが使用される。
- 二つのレキシコンを用意
<lexeme>
<grapheme>Bob</grapheme>
<alias>Robert</alias>
</lexeme>
<lexeme>
<grapheme>Bob</grapheme>
<alias>Bobby</alias>
</lexeme>
- LexA、LexBの順に適用
aws polly synthesize-speech \
--lexicon-names LexA LexB \
--output-format mp3 \
--text 'Hello, my name is Bob' \
--voice-id Justin \
bobAB.mp3
音声出力
Hello, my name is Robert.
- LexB、LexAの順に適用
aws polly synthesize-speech \
--lexicon-names LexB LexA \
--output-format mp3 \
--text 'Hello, my name is Bob' \
--voice-id Justin \
bobBA.mp3
音声出力
Hello, my name is Bobby.
非同期合成による長い音声ファイルの作成
- 通常のSynthesizeSpeechオペレーションの制限
- 3000文字まで合成可能
- ほぼリアルタイムにオーディオを生成
- 大規模テキストのTTSファイル作成
- Amazon Pollyの非同期合成機能を使用
非同期合成で使用する3つのSpeechSynthesisTask API
- StartSpeechSynthesisTask
- 新しい合成タスクを開始
- リクエストがキューに入れられ、システムリソースが利用可能になると非同期処理開始
- GetSpeechSynthesisTask
- 以前送信された合成タスクの詳細を返す
- ListSpeechSynthesisTasks
- 送信された合成タスクを一覧表示
出力結果の保存と通知
- 作成されたスピーチまたはスピーチマークストリームをAmazon S3バケット(必須)に直接アップロード
- 完了したファイルの可用性について、SNSトピック(オプション)を通じて通知
処理可能サイズ
リクエスト可能な最大サイズは、テキスト毎に100,000文字(または合計200,000文字)
暗号化(Encryption)
- 出力ファイルを暗号化された形式でS3バケットに保存可能
- Amazon S3バケットの暗号化を有効にする
- ブロック暗号の256ビット高度暗号化規格
AES-256を使用- ブロック暗号とは、共通鍵暗号の一種で、固定長のデータを単位として処理する暗号の総称
- ブロック暗号の256ビット高度暗号化規格
非同期合成用のIAMポリシー設定
次のIAM許可ポリシーが必要
- 新しいAmazon Pollyオペレーションの使用
- 出力S3バケットへの書き込み
- ステータスSNSトピックへの発行(オプション)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"polly:StartSpeechSynthesisTask",
"polly:GetSpeechSynthesisTask",
"polly:ListSpeechSynthesisTasks"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::bucket-name/*"
},
{
"Effect": "Allow",
"Action": "sns:Publish",
"Resource": "arn:aws:sns:region:account:topic"
}
]
}
おわりに
机上ではありますが、Amazon Pollyを技術の観点から理解しました。
次回は、実際AWS環境で手を動かしながら、Amazon Pollyの理解を深めます。
お楽しみに。