DeepLearningの基本的サンプルであるMNISTの入力データの詳細を調べてみる。
これを理解することで、自分で学習させたいデータを作成する際の参考となると思われる。
入力データの種類
MNISTでは以下の4種類のデータを入力データとして読み込んでいる。
| ファイル名 | 内容 |
|---|---|
| train-images-idx3-ubyte.gz | 学習用画像データ |
| train-labels-idx1-ubyte.gz | 学習用ラベルデータ |
| t10k-images-idx3-ubyte.gz | テスト用画像データ |
| t10k-labels-idx1-ubyte.gz | テスト用ラベルデータ |
これらのファイルはzipで圧縮されているため、実際に使用する際には内部的に解凍してから使用している。
学習用の画像枚数は60,000枚、テスト用の画像枚数は10,000枚となっている。
また、学習用データのうち5,000枚を検証用として使用している。(枚数は変更可能)
ラベルの識別数は10種類(0~9)である。
画像データ
画像データのフォーマットは以下のようになっている。
(例)train-images-idx3-ubyte.gz:学習用画像データ(28x28pixel、60,000枚)
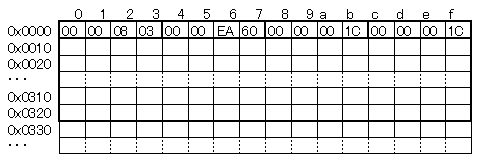
0x0000~0x0003:マジックナンバー(2051) ※これでMNISTの画像データかを判断している
0x0004~0x0007:画像枚数(60,000)
0x0008~0x000b:画像の高さ(28)
0x000c~0x000f:画像の幅(28)
0x0010~0x032f:1枚目の画像データ ※1pixelは1byte整数固定
画像データが60,000枚分続き、ファイルが終了する。
ラベルデータ
ラベルデータのフォーマットは以下のようになっている。
(例)train-labels-idx1-ubyte.gz:学習用ラベルデータ(10分類、60,000枚)
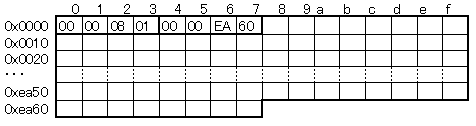
0x0000~0x0003:マジックナンバー(2049) ※これでMNISTのラベルデータかを判断している
0x0004~0x0007:画像枚数(60,000)
0x0008~0xea67:各画像のラベルの値 ※ラベルの値(0~9)は1byte整数固定
ラベルデータが60,000枚分続き、ファイルが終了する。
なお、各画像のラベルデータは、直接対応する分類番号が入っていることに注意すること。
各画像に対応する各識別値を指定したい場合は、0~9に対応したフラグ(0 or 1が10個)のような構造にする必要がある。
※もちろん、データだけでなく処理も修正が必要になる
参考
TensorFlowの場合、MNISTデータの読み込み処理は「tensorflow\contrib\learn\python\learn\datasets\mnist.py」にあるので、独自のデータを扱う際には、これを真似するのが理解しやすく良さそうだ。